Choose timezone
Your profile timezone:
Please visit Jefferson Lab Event Policies and Guidance before planning your next event: https://www.jlab.org/conference_planning.
Thank you all for a very successful CHEP 2023 in Norfolk! It was a pleasure to have you all here. Proceedings have been published and recordings of most plenary sessions are available.
We look forward to seeing you all at CHEP 2024 in Krakow, Poland (Oct 19--25, 2024).
The CHEP conferences address the computing, networking and software issues for the world’s leading data‐intensive science experiments that currently analyze hundreds of petabytes of data using worldwide computing resources. The Conference provides a unique opportunity for computing experts across Particle and Nuclear Physics to come together to learn from each other and typically attracts over 500 participants. The event features plenary sessions, parallel sessions, and poster presentations; it publishes peer-reviewed proceedings.
You can find additional information through the Conference Website and the links on the right sidebar.
The CHEP 2023 Proceedings have been published through the EPJ Web of Conferences. Thank you very much to everyone who contributed!
The world is full of computing devices that calculate, monitor, analyze, and control processes. The underlying technical advances within computing hardware have been further enhanced by tremendous algorithmic advances across the spectrum of the sciences. The quest -- ever present in humans -- to push the frontiers of knowledge and understanding requires continuing advances in the development and use of computation, with an increasing emphasis on the analysis of complex data originating from experiments and observations. How this move toward data intensive computing affects our underlying processes in the sciences remains to be fully appreciated. In this talk, I will briefly describe how we arrived at this point, and also give a prospective toward the end of the talk.
In today's Nuclear Physics (NP), the exploration of the origin, evolution, and structure of the universe's matter is pursued through a broad research program at various collaborative scales, ranging from small groups to large experiments comparable in size to those in high-energy physics (HEP). Consequently, software and computing efforts vary from DIY approaches among a few researchers to well-organized activities within large experiments. With new experiments underway and on the horizon, and data volumes rapidly increasing even at small experiments, the NP community has been considering the next generation of data processing and analysis workflows that will optimize scientific output. In my keynote, I will discuss the unique aspects of software and computing in NP and explore how the NP community can strengthen collective efforts to chart a path forward for the next decade. This decade promises to be an exciting one, with diverse scientific programs ongoing at facilities such as CEBAF, FRIB, RHIC, and many others. I will also demonstrate how this path informs the software and computing at the future Electron-Ion Collider.·
The dCache project provides open-source software deployed internationally to satisfy
ever more demanding storage requirements. Its multifaceted approach provides an integrated
way of supporting different use-cases with the same storage, from high throughput data
ingest, data sharing over wide area networks, efficient access from HPC clusters and long
term data persistence on a tertiary storage. Though it was originally developed for the
HEP experiments, today it is used by various scientific communities, including astrophysics,
biomed, life science, which have their specific requirements. With this contribution we
would like to highlight the recent developments in the dCache regarding integration with
CERN Tape Archive (CTA), advanced metadata handling, bulk API for QoS transitions, RESTAPI
to control interaction with tape system and the future development directions.
XRootD implemented a client-side erasure coding (EC) algorithm utilizing the Intel Intelligent Storage Acceleration Library. At SLAC, a prototype of XRootD EC storage was set up for evaluation. The architecture and configuration of the prototype is almost identical to that of a traditional non-EC XRootD storage behind a firewall: a backend XRootD storage cluster in its simplest form, and an internet facing XRootD proxy that handles EC and spreads the data stripes of a file/object across several backend nodes. This prototype supports all functions used on a WLCG storage system: HTTP(s) and XRootD protocols, Third Party Copy, X509/VOMS/Token, etc. The cross-node EC architecture brings significant advantages in both performance and resilience: e.g. parallel data access, tolerance of downtime and hardware failure. This paper will describe the prototype’s architecture and its design choices, the performance in high concurrent throughputs and file/object operations, failure modes and their handling, data recovery methods, and administration. This paper also describes the work that explores the HTTP protocol feature in XRootD to support data access via industry standard Boto3 S3 client library.
INFN-CNAF is one of the Worldwide LHC Computing Grid (WLCG) Tier-1 data centers, providing support in terms of computing, networking, storage resources and services also to a wide variety of scientific collaborations, ranging from physics to bioinformatics and industrial engineering.
Recently, several collaborations working with our data center have developed computing and data management workflows that require access to S3 storage services and the integration with POSIX capabilities.
To accomplish this requirement in distributed environments, where computing and storage resources are located at geographically distant physical sites, the possibility to locally mount a file system from a remote site to directly perform operations on files and directories becomes crucial.
Nevertheless, the access to the data must be regulated by standard, federated authentication and authorization mechanisms, such as OpenID Connect (OIDC), which is already adopted as AuthN/AuthZ mechanism within WLCG and the European Open Science Cloud (EOSC).
Starting from such principles, we evaluated the possibility to regulate data access by integrating JSON Web Token (JWT) authentication, provided by INDIGO-IAM as Identity Provider (IdP), with solutions based on S3 (for object storage) and HTTP (for hierarchical storage) protocols.
In particular, in regard to S3 data exposition, we integrated MinIO and CEPH RADOS Gateway with s3fs-fuse, providing the needed custom libraries to mount an S3 bucket via FUSE by preserving the native object format for files. Both solutions support Secure Token Service (STS), providing a client with temporary credentials to perform a given operation on a storage resource by checking the value of a JWT claim associated with the request.
Native MinIO STS does not support IAM JWT profile, thus we delegated STS service to Hashicorp Vault in the case of MinIO.
RADOS Gateway is an object storage interface for Ceph. It provides a RESTful S3-compatible API and a feature for integration with OIDC IdP. Access tokens produced for OIDC clients can be used by the STS implemented within RADOS Gateway for authorizing specific S3 operations.
On the other hand, HTTP data access has been managed by using Rclone and WebDAV protocol, to mount a storage area via INDIGO-IAM token authentication. In this case the storage area is exposed via HTTP by using the StoRM-WebDAV application, but the solution is general enough to be used with other HTTP data management servers (e.g. Apache, NGINX).
In such respect, a comparison between the performances yielded by S3 and WebDAV protocols has been carried out within the same Red Hat OpenShift environment, in order to better understand which solution is most suitable for each of the use cases of interest.
The Storage Group in the CERN IT Department operates several Ceph storage clusters with an overall capacity exceeding 100 PB. Ceph is a crucial component of the infrastructure delivering IT services to all the users of the Organization as it provides: i) Block storage for the OpenStack infrastructure, ii) CephFS used as persistent storage by containers (OpenShift and Kubernetes) and as shared filesystems by HPC clusters, and iii) S3 object storage for cloud-native applications, monitoring, and software distribution across the WLCG.
The Ceph infrastructure at CERN has been rationalized and restructured to offer storage solutions for high(er) availability and Disaster Recovery / Business Continuity. In this contribution, we give an overview of how we transitioned from a single RBD zone to multiple ones enabling Storage Availability zones and how RBD mirroring functionalities available in Ceph upstream have been hardened. Also, we illustrate future plans for storage BC/DR including backups via restic to S3 and Tape, replication of objects across multiple storage zones, and the instantiation of clusters spanning different computing centres.
Data access at the UK Tier-1 facility at RAL is provided through its ECHO storage, serving the requirements for the WLGC and increasing numbers of other HEP and astronomy related communities.
ECHO is a Ceph-backed erasure-coded object store, currently providing in excess of 40PB of usable space, with frontend access to data provided via XRootD or gridFTP, using the libradosstriper library of Ceph.
The storage must service the needs of: high-throughput compute, with staged and direct file access passing through an XCache on each workernode; data access to compute running at storageless satellite sites; and, managed inter-site data transfers using the recently adopted HTTPS protocol (via WebDav), which includes multi-hop data transfers to and from RAL’s newly commissioned CTA tape endpoint.
A review of the experiences of providing data access via an object store within these data workflows is presented, including the details of the improvements necessary for the transition to WebDav, used for most inter-site data movements, and enhancements for direct-IO file access, where the development and optimisation of buffering and range coalescence strategies is explored.
In addition to serving the requirements of LHC Run-3, preparations for Run-4 and for large astronomy experiments is underway. One example is with ROOT-based data formats, where the evolution from a TTree to RNTuple data structure provides an opportunity for storage providers to benchmark and optimise against this new format. A comparison of the current performance between data formats within ECHO is presented and the details of potential improvements presented.
EOS has been the main storage system at CERN for more than a decade, continuously improving in order to meet the ever evolving requirements of the LHC experiments and the whole physics user community. In order to satisfy the demands of LHC Run-3, in terms of storage performance and tradeoff between cost and capacity, EOS was enhanced with a set of new functionalities and features that we will detail in this paper.
First of all, we describe the use of erasure coded layouts in a large-scale deployment which enables an efficient use of available storage capacity, while at the same time providing end-users with better throughput when accessing their data. This new operating model implies more coupling between the machines in a cluster, which in turn leads to the next set of EOS improvements that we discuss, targeting I/O traffic shaping, better I/O scheduling policies and tagged traffic prioritization. Increasing the size of the EOS clusters to cope with experiment demands, means stringent constraints on the data integrity and durability that we addressed by a re-designed consistency check engine. Another focus area of EOS development was to minimize the operational load by making the internal operational procedures (draining, balancing or conversions) more robust and efficient, to allow managing easily multiple clusters and avoid possible scaling issues.
All these improvements available in the EOS 5 release series, are coupled with the new XRootD 5 framework which brings additional security features like TLS support and optimizations for large data transfers like page read and page write functionalities. Last but not least, the area of authentication/authorization methods has seen important developments by adding support for different types of bearer tokens that we will describe along with EOS specific token extensions. We conclude by highlighting potential areas of the EOS architecture that might require further developments or re-design in order to cope with the ever-increasing demands of our end-users.
The LHCb experiment is one of the four large experiments on the LHC at CERN. This forward spectrometer is designed to investigate differences between matter and antimatter by studying beauty and charm Physics. The detector and the entire DAQ chain have been upgraded, to profit from the higher luminosity delivered by the particle accelerator during Run3. The new DAQ system introduces a substantially different model for reading-out the detector data, which has not been used in systems of similar scale up to now. We designed a system capable of performing read-out, event-building and online reconstruction of the full event-rate produced by the LHC, without incurring the inefficiencies that a low-level hardware trigger would introduce. This design paradigm requires a DAQ system capable of ingesting an aggregated throughput of ~32 Tb/s, this poses significant technical challenges which have been solved by using both off-the-shelf solutions - like InfiniBand HDR - and customly developed FPGA-based electronics.
In this contribution, we will: provide an overview on the final system design, with a special focus on the event-building infrastructure; present quantitative measurements taken during the commissioning of the system; discuss the resiliency of the system concerning latency and fault tolerance; and provide feedback on the first year of operations of the system.
ALICE (A Large Ion Collider Experiment) has undertaken a major upgrade during the LHC Long Shutdown 2. The increase in the detector data rates led to a hundredfold increase in the input raw data, up to 3.5 TB/s. To cope with it, a new common Online and Offline computing system, called O2, has been developed and put in production.
The O2/FLP system, successor of the ALICE DAQ system, implements the critical functions of detector readout, data quality control and operational services running in the CR1 data centre at the experimental site. Data from the 15 ALICE subdetectors are read out via 8000 optical links by 500 custom PCIe cards hosted in 200 nodes. It addresses novel challenges such as the continuous readout of the TPC detector while keeping compatibility with legacy detector front-end electronics.
This paper discusses the final architecture and design of the O2/FLP system and provides an overview of all its components, both hardware and software. It presents the selection process for the FLP nodes, the different commissioning steps and the main accomplishments so far. It will conclude with the challenges that lie ahead and how they will be addressed.
Athena is the software framework used in the ATLAS experiment throughout the data processing path, from the software trigger system through offline event reconstruction to physics analysis. For Run 3 data taking (which started in 2022) the framework has been reimplemented into a multi-threaded framework. In addition to having to be remodelled to work in this new framework, the ATLAS High Level Trigger (HLT) system has also been updated to rely on common solutions between online and offline software to a greater extent than in Run 2 (data taking between 2015-2018). We present the now operational new HLT system, reporting on how the system was tested, commissioned and optimised. In addition, we show developments that have been made in tools that are used to monitor and configure the HLT, some of which are designed from scratch for Run 3.
The INDRA-ASTRA project is part of the ongoing R&D on streaming readout and AI/ML at Jefferson Lab. In the interdisciplinary project, nuclear physicists and data scientists work towards a prototype for an autonomous, responsive detector system as a first step towards a fully autonomous experiment. In our presentation, we will present our method for autonomous calibration of DIS experiments using baseline calibrations and autonomous change detection via the multiscale method. We will demonstrate how the versatile multiscale method we have developed can be used to increase reliability of data and find and fix issues in near real time. We will show test results from a prototype detector and the running, large-scale SBS experiment at Jefferson Lab.
The ATLAS experiment at CERN is constructing upgraded system
for the "High Luminosity LHC", with collisions due to start in
2029. In order to deliver an order of magnitude more data than
previous LHC runs, 14 TeV protons will collide with an instantaneous
luminosity of up to 7.5 x 10e34 cm^-2s^-1, resulting in much higher pileup and
data rates than the current experiment was designed to handle. While
this is essential to realise the physics programme, it presents a huge
challenge for the detector, trigger, data acquisition and computing.
The detector upgrades themselves also present new requirements and
opportunities for the trigger and data acquisition system.
The design of the TDAQ upgrade comprises: a hardware-based low-latency
real-time Trigger operating at 40 MHz, Data Acquisition which combines
custom readout with commodity hardware and networking to deal with
4.6 TB/s input, and an Event Filter running at 1 MHz which combines
offline-like algorithms on a large commodity compute service
with the potential to be augmented by commercial accelerators .
Commodity servers and networks are used as far as possible, with
custom ATCA boards, high speed links and powerful FPGAs deployed
in the low-latency parts of the system. Offline-style clustering and
jet-finding in FPGAs, and accelerated track reconstruction are
designed to combat pileup in the Trigger and Event Filter
respectively.
This contribution will report recent progress on the design, technology and
construction of the system. The physics motivation and expected
performance will be shown for key physics processes.
The fast algorithms for data reconstruction and analysis of the FLES (First Level Event Selection) package of the CBM (FAIR/GSI) experiment were successfully adapted to work on the High Level Trigger (HLT) of the STAR (BNL) experiment online. For this purpose, a so-called express data stream was created on the HLT, which enabled full processing and analysis of the experimental data in real time.
With this express data processing, including online calibration, reconstruction of tracks and short-lived particles, as well as search and analysis of hyperons and hypernuclei, approximately 30% of all the data collected in 2019-2021 within the Beam Energy Scan (BES-II) program at energies down to 3 GeV has been processed on the free resources of the HLT computer farm.
A block diagram of the express data processing and analysis will be presented, particular features of the online calibration and application of the reconstruction algorithms, work under pile-up conditions at low collision energies in the fixed-target mode, and results of the real-time search for hyperons and hypernuclei up to $^5_\Lambda$He with 11.6$\cdot\sigma$ at HLT will be presented and discussed. The high quality of the express data enabled preliminary analysis results in several physics measurements.
The reconstruction of particle trajectories is a key challenge of particle physics experiments, as it directly impacts particle identification and physics performances while also representing one of the main CPU consumers of many high energy physics experiments. As the luminosity of particle collider increases, this reconstruction will become more challenging and resource intensive. New algorithms are thus needed to address these challenges efficiently. One potential step of track reconstruction is the ambiguity resolution. In this step, performed at the end of the tracking chain, we select which tracks candidates should to be kept and which ones need to be discarded. In the ATLAS experiment, for example, this is achieved by identifying fakes tracks, removing duplicates and determining via a Neural Network which hits should be shared by multiple tracks. The speed of this algorithm is directly driven by the number of track candidates, which can be reduced at the cost of some physics performance. Since this problem is fundamentally an issue of comparison and classification, we propose to use a machine learning based approach to the Ambiguity Resolution itself. Using a nearest neighbour search, we can efficiently determine which candidates belong to the same truth particle. Afterward, we can apply a Neural Network (NN) to compare those tracks and determine which ones are the duplicate and which one should be kept. Finally, another NN is applied to all the remaining candidates to identify which ones are fakes and remove those. This approach is implemented within A Common Tracking Software (ACTS) framework and tested on the Open Data Detector (ODD) a realistic virtual detector, similar to a future ATLAS one, to fully evaluate the potential of this approach.
MkFit is an implementation of the Kalman filter-based track reconstruction algorithm that exploits both thread- and data-level parallelism. In the past few years the project transitioned from the R&D phase to deployment in the Run-3 offline workflow of the CMS experiment. The CMS tracking performs a series of iterations, targeting reconstruction of tracks of increasing difficulty after removing hits associated to tracks found in previous iterations. MkFit has been adopted for several of the tracking iterations, which contribute to the majority of reconstructed tracks. When tested in the standard conditions for production jobs, speedups in track pattern recognition are on average of the order of 3.5x for the iterations where it is used (3-7x depending on the iteration). Multiple factors contribute to the observed speedups, including vectorization and a lightweight geometry description, as well as improved memory management and single precision. Efficient vectorization is achieved with both the icc and the gcc (default in CMSSW) compilers and relies on a dedicated library for small matrix operations, Matriplex, which has recently been released in a public repository. While the mkFit geometry description already featured levels of abstraction from the actual Phase-1 CMS tracker, several components of the implementations were still tied to that specific geometry. We have further generalized the geometry description and the configuration of the run-time parameters, in order to enable support for the Phase-2 upgraded tracker geometry for the HL-LHC and potentially other detector configurations. The implementation strategy and preliminary results with the HL-LHC geometry will be presented. Speedups in track building from mkFit imply that track fitting becomes a comparably time consuming step of the tracking chain. Prospects for an mkFit implementation of the track fit will also be discussed.
Despite recent advances in optimising the track reconstruction problem for high particle multiplicities in high energy physics experiments, it remains one of the most demanding reconstruction steps in regards to complexity and computing ressources. Several attemps have been made in the past to deploy suitable algorithms for track reconstruction on hardware accelerators, often by tailoring the algorithmic strategy to the hardware design. This led in certain cases to algorithmic compromises, and often came along with simplified descriptions of detector geometry, input data and magnetic field.
The traccc project is an R&D initiative of the ACTS common track reconstruction; it aims to provide a complete track reconstruction chain for both CPU and GPU architectures. Emphasis has been put on sharing as much common source code as possible while trying to avoid algorithmic and physics performance compromises. Within traccc, dedicated components have been developed that are usable on standard CPU and GPU architectures: an astraction layer for linear algebra operations that allows to customize the mathematical backend (algebra-plugin), a host and device memory management system (vecmem), a generic vector field library (covfie) for the magneic field description, and a geometry and propagation library (detray). They serve as building blocks of a fully developed track reconstruction demonstrator based on clustering (connected component labelling), space point formation, track seeding and combinatorial track finding.
We present the concepts and implementation of the traccc demonstrator and classify the physics and computational performance on selected hardware using the Open Data Detector in an scenario minicking the HL-LHC run condition. In addition, we give insight in our attempts to use different native language and portability solutions for GPUs, and summarize our main findings during the development of the entire traccc project.
The high luminosity expected from the LHC during the Run 3 and, especially, the HL-LHC of data taking introduces significant challenges in the CMS event reconstruction chain. The additional computational resources needed to treat this increased quantity of data surpass the expected increase in processing power for the next years. In order to fit the projected resource envelope, CMS is re-inventing its online and offline reconstruction algorithms, with their execution on CPU+GPU platforms in mind. Track clustering and primary vertex reconstruction accounts today about 10% of the reconstruction chain at 200 pileup and involves similar computations over hundreds to thousands of reconstructed tracks. This makes it a natural candidate for the development of a GPU-based algorithm that parallelizes it dividing the work in blocks. In this contribution we discuss the physics performance as well as the runtime performance of a new vertex clustering algorithm CMS developed for heterogeneous plarforms. We'll show that the physics results achieved are better than the current CMS vertexing algorithm in production, that the algorithm is up to 8 times faster on CPU and runs as well on GPUs. We will also discuss the plans for using this algorithm in production in Run 3 and for extending it to make use of timing information provided by the CMS Phase-2 MIP Timing Detector (MTD).
Building on the pioneering work of the HEP.TrkX project [1], Exa.TrkX developed geometric learning tracking pipelines that include metric learning and graph networks. These end-to-end pipelines capture the relationships between spacepoint measurements belonging to a particle track. We tested the pipelines on simulated data from HL-LHC tracking detectors [2,5], Liquid Argon TPCs for neutrino experiments [3,8], and the straw tube tracker of the PANDA experiment[4]. The HL-LHC pipeline provides state-of-the-art tracking performance (Fig. 2), scales linearly with spacepoint density (Fig. 1), and has been optimized to run end-to-end on GP-GPUs, achieving a 20x speed-up with respect to the baseline implementation [6,9].
The Exa.TrkX geometric learning approach also has shown promise in less traditional tracking applications, like large-radius tracking for new physics searches at the LHC [7].
Exa.TrkX also contributed to developing and optimizing common data formats for ML training and inference targeting both neutrino detectors and LHC trackers.
When applied to LArTPC neutrino experiments, the Exa.TrkX message-passing graph neural network classifies nodes, defined as the charge measurements or hits, according to the underlying particle type that produced them (Fig 3). Thanks to special 3D edges, our network can connect nodes within and across wire planes and achieve 94% accuracy with 96% consistency across wire planes [8].
From the very beginning, the Exa.TrkX project has functioned as a collaboration open beyond its three original institutions (CalTech, FNAL, and LBNL). We released the code associated with every publication and produced tutorials and quickstart examples to test our pipeline.
Eight US universities and six international institutions have contributed significantly to our research program and publications. The collaboration currently includes members of the ATLAS, CMS, DUNE, and PANDA experiments. Members of the FNAL muon g-2 experiment and CERN MUonE projects have tested the Exa.TrkX pipeline on their datasets.
Exa.TrkX profits from multi-year partnerships with related research projects, namely the ACTS common tracking software, the ECP ExaLearn project, the NSF A3D3 institute, and the Fast ML Lab. More recently, as our pipeline matured and became applicable to more complex datasets, we started a partnership with HPE Lab, which uses our pipeline as a benchmark for its hyperparameter optimization and common metadata framework. NVIDIA (through the NERSC NESAP program) is evaluating the Exa.TrkX pipeline as an advanced use case for their R&D in Graph neural networks optimization.
At this stage of the project, a necessary focus of the Exa.TrkX team is on consolidation and dissemination of the results obtained so far. We are re-engineering the LHC pipeline to improve its modularity and usability across experiment frameworks. We aim to integrate our pipelines with online and offline reconstruction chains of neutrino and collider detectors and release a repository of production-quality HEP pattern recognition models that can be readily composed into an experiment-specific pipeline.
We are investigating heterogeneous graph networks to improve our pipelines' physics performance and make our models more easily generalizable [11]. Heterogeneity allows mixing and matching information from multiple detector geometries and types (strips vs. pixels, calorimeters vs. trackers vs. timing detectors, etc.).
We have demonstrated that it is possible to recover “difficult” tracks (e.g., tracks with a missing spacepoint) by using hierarchical graph networks [10]. Next, we need to scale these models to more challenging datasets, including full HL-LHC simulations.
We are also investigating how to parallelize our pipeline across multiple GPUs. Data parallelism for graph networks is an active research area in geometric learning. The unique setting of our problem, with large graphs that change structure with every event, makes parallelizing the inference step particularly challenging.
A future research project's ultimate goal would be to combine these four R&D threads into a generic pipeline for HEP pattern recognition that operates on heterogeneous data at different scales, from raw data to particles.
[1 ]Farrell, S., Calafiura, P., et al. . Novel deep learning methods for track reconstruction. (2018). arXiv. https://doi.org/10.48550/arXiv.1810.06111
[2] Ju, X., Murnane, D., et al. Performance of a geometric deep learning pipeline for HL-LHC particle tracking. Eur. Phys. J. C 81, 876 (2021). https://doi.org/10.1140/epjc/s10052-021-09675-8
[3] Hewes, J., Aurisano, A., et al. Graph Neural Network for Object Reconstruction in Liquid Argon Time Projection Chambers. EPJ Web of Conferences 251, 03054 (2021).
https://doi.org/10.1051/epjconf/202125103054
[4] Akram, A., & Ju, X. Track Reconstruction using Geometric Deep Learning in the Straw Tube Tracker (STT) at the PANDA Experiment. (2022) arXiv. https://doi.org/10.48550/arXiv.2208.12178
[5] Caillou, S., Calafiura, P. et al. ATLAS ITk Track Reconstruction with a GNN-based pipeline. (2022). ATL-ITK-PROC-2022-006. https://cds.cern.ch/record/2815578
[6] Lazar, A., Ju, X., et al. Accelerating the Inference of the Exa.TrkX Pipeline. (2022). arXiv. https://doi.org/10.48550/arXiv.2202.06929
[7] Wang, C., Ju, X., et al. Reconstruction of Large Radius Tracks with the Exa.TrkX pipeline. (2022). arXiv. https://doi.org/10.48550/arXiv.2203.08800
[8] Gumpula, K., et al., Graph Neural Network for Three Dimensional Object Reconstruction in Liquid Argon Time Projection Chambers. (2022). Presented at the Connecting the Dots 2022 workshop.
https://indico.cern.ch/event/1103637/contributions/4821839
[9] Acharya, N., Liu, E., Lucas, A., Lazar, A. Optimizing the Exa.TrkX Inference Pipeline for Manycore CPUs. (2022). Presented at the Connecting the Dots 2022 workshop. https://indico.cern.ch/event/1103637/contributions/4821918
[10] Liu, R., Murnane, D., et al. Hierarchical Graph Neural Networks for Particle Reconstruction. (2022). Presented at the ACAT 2022 conference. https://indico.cern.ch/event/1106990/contributions/4996236/
[11] Murnane, D., Caillou, S.,. Heterogeneous GNN for tracking. (2022). Presented at the Princeton Mini-workshop on Graph Neural Networks for Tracking. https://indico.cern.ch/event/1128328/contributions/4900744
The production of simulated datasets for use by physics analyses consumes a large fraction of ATLAS computing resources, a problem that will only get worse as increases in the instantaneous luminosity provided by the LHC lead to more collisions per bunch crossing (pile-up). One of the more resource-intensive steps in the Monte Carlo production is reconstructing the tracks in the ATLAS Inner Detector (ID), which takes up about 60% of the total detector reconstruction time [1]. This talk discusses a novel technique called track overlay, which substantially speeds up the ID reconstruction. In track overlay the pile-up ID tracks are reconstructed ahead of time and overlaid onto the ID tracks from the simulated hard-scatter event. We present our implementation of this track overlay approach as part of the ATLAS Fast Chain simulation, as well as a method for deciding in which cases it is possible to use track overlay in the reconstruction of simulated data without performance degradation.
[1] ATL-PHYS-PUB-2021-012 (60% refers to Run3, mu=50, including large-radius tracking, p11)
Machine learning has become one of the important tools for High Energy Physics analysis. As the size of the dataset increases at the Large Hadron Collider (LHC), and at the same time the search spaces become bigger and bigger in order to exploit the physics potentials, more and more computing resources are required for processing these machine learning tasks. In addition, complex advanced machine learning workflows are developed in which one task may depend on the results of previous tasks. How to make use of vast distributed CPUs/GPUs in WLCG for these big complex machine learning tasks has become a popular area. In this presentation, we will present our efforts on distributed machine learning in PanDA and iDDS (intelligent Data Delivery Service). We will at first address the difficulties to run machine learning tasks on distributed WLCG resources. Then we will present our implementation with DAG (Directed Acyclic Graph) and sliced parameters in iDDS to distribute machine learning tasks to distributed computing resources to execute them in parallel through PanDA. Next we will demonstrate some use cases we have implemented, such as Hyperparameter Optimization, Monte Carlo Toy confidence limits calculation and Active Learning. Finally we will describe some directions to perform in the future.
We present a new implementation of simulation-based inference using data collected by the ATLAS experiment at the LHC. The method relies on large ensembles of deep neural networks to approximate the exact likelihood. Additional neural networks are introduced to model systematic uncertainties in the measurement. Training of the large number of deep neural networks is automated using a parallelized workflow with distributed computing infrastructure integrated with cloud-based services. We will show an example workflow using the ATLAS PanDA framework integrated with GPU infrastructure from Google Cloud Platform. Numerical analysis of the neural networks is optimized with JAX and JIT. The novel machine-learning method and cloud-based parallel workflow can be used to improve the sensitivity of several other analyses of LHC data.
Predicting the performance of various infrastructure design options in complex federated infrastructures with computing sites distributed over a wide area that support a plethora of users and workflows, such as the Worldwide LHC Computing Grid (WLCG), is not trivial. Due to the complexity and size of these infrastructures, it is not feasible to deploy experimental test-beds at large scales merely for the purpose of comparing and evaluating alternate designs.
An alternative is to simulate the behaviours of these systems based on realistic simulation models. This approach has been used successfully in the past to identify efficient and practical infrastructure designs for High Energy Physics (HEP). A prominent example is the Monarc simulation framework, which was used to study the initial structure of the WLCG. However, new simulation capabilities are needed to simulate large-scale heterogeneous infrastructures with complex networks as well as application behaviours that include various data access and caching patterns.
In this context, a modern tool to simulate high energy physics workloads that execute on distributed computing infrastructures based on the SimGrid and WRENCH simulation frameworks is outlined. Studies of its accuracy and scalability are presented using HEP as a case-study.
InterTwin is an EU-funded project that started on the 1st of September 2022. The project will work with domain experts from different scientific domains in building a technology to support digital twins within scientific research. Digital twins are models for predicting the behaviour and evolution of real-world systems and applications.
InterTwin will focus on employing machine-learning techniques to create and train models that are able to quickly and accurately reflect their physical counterparts in a broad range of scientific domains. The project will develop, deploy and “road harden” a blueprint for supporting digital twins on federated resources. For that purpose, it will support a diverse set of science use-cases, in the domains of radio telescopes (Meerkat), particle physics (CERN/LHC and Lattice-QCD), gravitational waves (Virgo), as well as climate research and environment monitoring (e.g. prediction of flooding and other extreme weather due to climate change). The ultimate goal is to provide a flexible infrastructure that can accommodate the needs of many additional scientific fields.
In the talk, we will present an overview of the interTwin project along with the corresponding Digital Twin Engine (DTE) architecture for federating the different, heterogeneous resources available to the scientific use-cases (storage, HPC, HTC, quantum) when training and exploitation of digital twins within the different scientific domains. The challenges faced when designing the architecture will be described, along with the solutions being developed to address them. interTwin is required to be interoperable with other infrastructures, including EuroHPC-based Destination Earth Initiative (DestinE) and an infrastructure for accessing Copernicus satellite data, C-SCALE. We will also present our strategy for making DTE available within the European Open Science Cloud (EOSC). The details of all such interoperability will also be presented.
The IceCube Neutrino Observatory is a cubic kilometer neutrino telescope located at the geographic South Pole. To accurately and promptly reconstruct the arrival direction of candidate neutrino events for Multi-Messenger Astrophysics use cases, IceCube employs Skymap Scanner workflows managed by the SkyDriver service. The Skymap Scanner performs maximum-likelihood tests on individual pixels generated from the Hierarchical Equal Area isoLatitude Pixelation (HEALPix) algorithm. Each test is computationally independent, which allows for massive parallelization. This workload is distributed using the Event Workflow Management System (EWMS)—a message-based workflow management system designed to scale to trillions of pixels per day. SkyDriver orchestrates multiple distinct Skymap Scanner workflows behind a REST interface, providing an easy-to-use reconstruction service for real-time candidate, cataloged, and simulated events. Here, we outline the SkyDriver service technique and the initial development of EWMS.
A fast turn-around time and ease of use are important factors for systems supporting the analysis of large HEP data samples. We study and compare multiple technical approaches.
This presentation will be about setting up and benchmarking the Analysis Grand Challenge (AGC) [1] using CMS Open Data. The AGC is an effort to provide a realistic physics analysis with the intent of showcasing the functionality, scalability and feature-completeness of the Scikit-HEP Python ecosystem.
I will present the results of setting up the necessary software environment for the AGC and benchmarking the analysis' runtime on various computing clusters: the institute SLURM cluster at my home institute, LMU Munich, a SLURM cluster at LRZ (WLCG Tier-2 site) and the analysis facility Vispa [2], operated by RWTH Aachen.
Each site provides slightly different software environments and modes of operation which poses interesting challenges on the flexibility of a setup like that intended for the AGC.
Comparing these benchmarks to each other also provides insights about different storage and caching systems. At LRZ and LMU we have regular Grid storage (HDD) as well as and SSD-based XCache server and on Vispa a sophisticated per-node caching system is used.
[1] https://github.com/iris-hep/analysis-grand-challenge
[2] https://vispa.physik.rwth-aachen.de/
The Julia programming language was created 10 years ago and is now a mature and stable language with a large ecosystem including more than 8,000 third-party packages. It was designed for scientific programming to be a high-level and dynamic language as Python is, while achieving runtime performances comparable to C/C++ or even faster. With this, we ask ourselves if the Julia language and its ecosystem is ready now for its adoption by the High Energy Physics community. We will report on a number of investigations and studies of the Julia language that have been done for various representative HEP applications, ranging from computing intensive initial data processing of experimental data and simulation, to final interactive data analysis and plotting. Aspects of collaborative code development of large software within a HEP experiment has also been investigated: scalability with large development teams, continuous integration and code test, code reuse, language interoperability to enable a adiabatic migration of packages and tools, software installation and distribution, training of the community, benefit from development from industry and academia from other fields.
The evaluation of new computing languages for a large community, like HEP, involves comparison of many aspects of the languages' behaviour, ecosystem and interactions with other languages. In this paper we compare a number of languages using a common, yet non-trivial, HEP algorithm: the tiled $N^2$ clustering algorithm used for jet finding. We compare specifically the algorithm implemented in Python, using numpy, Julia and Rust, with respect to the reference implementation in C++, from Fastjet. As well as the speed of the implementation we describe the ergonomics of the language for the coder, as well as the efforts required to achieve the best performance, which can directly impact on code readability and sustainability.
With an increased dataset obtained during the Run-3 of the LHC at CERN and the even larger expected increase of the dataset by more than one order of magnitude for the HL-LHC, the ATLAS experiment is reaching the limits of the current data processing model in terms of traditional CPU resources based on x86_64 architectures and an extensive program for software upgrades towards the HL-LHC has been set up. The ARM architecture is becoming a competitive and energy efficient alternative. Some surveys indicate its increased presence in HPCs and commercial clouds, and some WLCG sites have expressed their interest. Chip makers are also developing their next generation solutions on ARM architectures, sometimes combining ARM and GPU processors in the same chip. Therefore it is important that the Athena software embraces the change and is able to successfully exploit this architecture.
We report on the successful port of the ATLAS experiment offline and online software framework Athena to ARM and the successful physics validation of simulation workflows. For this we have set up an ATLAS Grid site using ARM compatible middleware and containers on Amazon Web Services (AWS) ARM resources. The ARM version of Athena is fully integrated in the regular software build system and distributed like default software releases. In addition, the workflows have been integrated into the HepScore benchmark suite which is the planned WLCG wide replacement of the HepSpec06 benchmark used for Grid site pledges. In the overall porting process we have used resources on AWS, Google Cloud Platform (GCP) and CERN. A performance comparison of different architectures and resources will be discussed.
High Energy Physics software has been a victim of the necessity to choose one implementation language as no really usable multi-language environment existed. Even a co-existence of two languages in the same framework (typically C++ and Python) imposes a heavy burden on the system. The role of different languages was generally limited to well encapsulated domains (like Web applications, databases, graphics), with very limited connection to the central framework.
The new development in the domain of the compilers and run-time environments has enabled ways for creating really multilanguage frameworks, with seamless, user-friendly and high-performance inter-operation of many languages, which traditionally live in disconnected domains (like C-based languages vs JVM languages or Web languages).
Various possibilities and strategies for creation of the true multi-language frameworks will be discussed, emphasizing their advantages and possible road blocks.
A prototype of massively multilanguage application will be presented, using very wide spectrum of languages working together (C++, Python, JVM languages, JavaScript,...). Each language will be used in the domain where it offers a strong comparative advantage (speed, user-friendliness, availability of third-party libraries and tools, graphical and web capabilities).
The performance gain from the modern multi-language environments will be also demonstrated, as well as gains in the overall memory footprint.
Possibilities of converting existing HEP frameworks into multilanguage environments will be discussed in concrete examples and demonstrations.
A real life example of widely multilanguage environment will be demonstrated on the case of the multi-language access to the data storage of the LSST telescope Fink project.
Software and computing are an integral part of our research. According to the survey for the “Future Trends in Nuclear Physics Computing” workshop in September 2020, students and postdocs spent 80% of their time on the software and computing aspects of your research. For the Electron-Ion Collider, we are looking for ways to make software (and computing) "easier" to use. All scientists of all levels worldwide should be empowered to participate in Electron-Ion Collider simulations and analyses actively.
In this presentation, we will summarize our work on user-centered design for the Electron-Ion Collider. We have collected information on the community's specific software tools and practices on an annual basis. We have also organized focus group discussions with the broader community and developed user archetypes based on the feedback from the focus groups. The user archetypes represent a common class of users and provide input to software developers as to which users they are writing software for and help with structuring documentation.
The HSF/IRIS-HEP Software Training group provides software training skills to new researchers in High Energy Physics (HEP) and related communities. These skills are essential to produce high-quality and sustainable software needed to do the research. Given the thousands of users in the community, sustainability, though challenging, is the centerpiece of its approach. The training modules are open source and collaborative. Different tools and platforms, like GitHub, enable technical continuity, collaboration and nurture the sense to develop software that is reproducible and reusable. This contribution describes these efforts.
RooFit is a library for building and fitting statistical models that is part of ROOT. It is used in most experiments in particle physics, in particular, the LHC experiments. Recently, the backend that evaluates the RooFit likelihood functions was rewritten to support performant computations of model components on different hardware. This new backend is referred to as the "batch mode". So far, it supports GPUs with CUDA and also the vectorizing instructions on the CPU. With ROOT 6.28, the new batch mode is feature-complete and speeds up all use cases targeted by RooFit, even on a single CPU thread. The GPU backend further reduces the likelihood evaluation time, particularly for unbinned fits to large datasets. The speedup is most significant when all likelihood components support GPU evaluation. Still, if this is not the case, the backend will optimally distribute the computation on the CPU and GPU to guarantee a speedup.
RooFit is a very extensible library with a vast user interface to inject behavior changes at almost every point of the likelihood calculation, which the new heterogeneous computation backend must handle. This presentation discusses our approach and lessons learned when facing this challenge. The highlight of this contribution is showcasing the performance improvements for benchmark examples, fits from the RooFit tutorials, and real-world fit examples from LHC experiments. We will also elaborate on how users can implement GPU support for their custom probability density functions and explain the current limitations and future developments.
With the growing datasets of current and next-generation High-Energy and Nuclear Physics (HEP/NP) experiments, statistical analysis has become more computationally demanding. These increasing demands elicit improvements and modernizations in existing statistical analysis software. One way to address these issues is to improve parameter estimation performance and numeric stability using automatic differentiation (AD). AD's computational efficiency and accuracy is superior to the preexisting numerical differentiation techniques and offers significant performance gains when calculating the derivatives of functions with a large number of inputs, making it particularly appealing for statistical models with many parameters. For such models, many HEP/NP experiments use RooFit, a toolkit for statistical modeling and fitting that is part of ROOT.
In this talk, we report on the effort to support the AD of RooFit likelihood functions. Our approach is to extend RooFit with a tool that generates overhead-free C++ code for a full likelihood function built from RooFit functional models. Gradients are then generated using Clad, a compiler-based source-code-transformation AD tool, using this C++ code. We present our results from applying AD to the entire minimization pipeline and profile likelihood calculations of several RooFit and HistFactory models at the LHC-experiment scale. We show significant reductions in calculation time and memory usage for the minimization of such likelihood functions. We also elaborate on this approach's current limitations and explain our plans for the future.
This contribution combines R&D expertise from computer science applied at scale for HEP/NP analysis: we demonstrate that source-transformation-based AD can be incorporated into complex, domain-specific codes such as RooFit to give substantial performance and scientific capability improvements.
RooFit is a toolkit for statistical modeling and fitting, presented first at CHEP2003, and together with RooStats is used for measurements and statistical tests by most experiments in particle physics, particularly the LHC experiments.
As the LHC program progresses, physics analyses become more ambitious and computationally more demanding, with fits of hundreds of data samples to joint models with over a thousand parameters no longer an exception. While such complex fits can be robustly performed in RooFit, they may take many hours on a single CPU, significantly impeding the ability of physicists to interactively understand, develop and improve them. Here were present recent RooFit developments to address this, focusing on significant improvements of wall-time performance of complex fits.
A complete rewrite of the internal back-end of the RooFit likelihood calculation code in ROOT 6.28 now allows to massively parallelize RooFit likelihood fits in two ways. Gradients that are normally serially calculated inside MINUIT, and which dominate the total fit time, are now calculated in a parallel way inside RooFit. Furthermore, calculations of the likelihood in serial phases of the minimizer (initialization and gradient descent steps) are also internally parallelized. No modification of any user code is required to take advantage of these features.
A key to achieving good scalability for these parallel calculations is close to perfect load balancing over the workers, which is complicated by the fact that for realistic complex fit models the calculations to parallelize cannot be split in components of equal or even comparable size. As part of this update, instruments have been added to RooFit for extensive performance monitoring that allow the user to understand the effect of algorithmic choices in task scheduling and mitigate performance bottlenecks.
We will show that that with a new dynamic scheduling strategy and a strategic choice of ordering derivative calculations excellent scalability can be achieved, resulting in an order-of-magnitude wall-time speedups for complex realistic LHC fits such as the ATLAS Run-2 combined Higgs interpretation.
Minuit is a program implementing a function minimisation algorithm written at CERN more than 50 years ago. It is still used by almost all statistical analysis in High Energy Physics to find optimal likelihood and best parameter values. A new version, Minuit2, has been re-implemented the original algorithm in C++ a few years ago and it is provided as a ROOT library or a standalone C++ module. It is also available as a Python package, IMinuit.
This new version has been recently improved by adding some new features. These include support for external gradients and hessian, allowing the use of Automatic Differentiation techniques or parallel computation of the gradients and the addition of new minimisation algorithms such as BFGS and Fumili. We will present an overview of the new implementation showing the new added features and we will as well present a comparison with other existing minimisation packages, available in C++ or in the Python scientific ecosystem.
Collider physics analyses have historically favored Frequentist statistical methodologies, with some exceptions of Bayesian inference in LHC analyses through use of the Bayesian Analysis Toolkit (BAT). We demonstrate work towards an approach for performing Bayesian inference for LHC physics analyses that builds upon the existing APIs and model building technology of the pyhf and PyMC Python libraries and leverages pyhf’s automatic differentiation and hardware acceleration through its JAX computational backend. This approach presents a path toward unified APIs in pyhf that allow for users to choose a Frequentist or Bayesian approach towards statistical inference, leveraging their respective strengths as needed, without having to transition between using multiple libraries or fall back to using pyhf with BAT through the Julia programming language PyCall package. Examples of Markov chain Monte Carlo implementations using Metropolis-Hastings and Hamiltonian Monte Carlo are presented.
Many current analyses in nuclear and particle physics are in search for signals that are encompassed by irreducible background events. These background events, entirely surrounding a signal of interest, would lead to inaccurate results when extracting physical observables from the data, due to the inability to reduce the signal to background ratio using any type of selection criteria. By looking at a data set in multiple dimensions, the phase space of a desired reaction can be characterized by a set of coordinates, where a subset of these coordinates (known as reference coordinates) contains a distinguishable distribution where the signal and background can easily be determined. The approach then uses the space defined by the non-reference coordinates, to determine the k-nearest neighbors of an event, where these events can then be fit on the reference coordinates of these k-nearest neighbors (using an unbinned maximum likelihood fit, etc.). From the fit, a quality factor can be defined for each event in the data set that states the probability that it originates from the actual signal of interest. The unique aspect of this procedure requires no a priori information of the signal or background distributions within the phase space in the desired reaction. This and many other useful properties for this statistical weighting procedure makes this method more advantageous in certain analyses than other methods. A detailed overview of this procedure will be shown along with examples using Monte Carlo and GlueX data.
Managing a secure software environment is essential to a trustworthy cyberinfrastructure. Software supply chain attacks may be a top concern for IT departments, but they are also an aspect of scientific computing. The threat to scientific reputation caused by problematic software can be just as dangerous as an environment contaminated with malware. The issue of managing environments affects any individual researcher performing computational research but is more acute for multi-institution scientific collaborations, such as high energy physics experiments, as they often preside over complex software stacks and must manage software environments across many distributed computing resources. We discuss a new project, Securing an Open and Trustworthy Ecosystem for Research Infrastructure and Applications (SOTERIA), to provide the HEP community with a container registry service and provide additional capabilities to assist with vulnerability assessment, authorship and provenance, and distribution. This service is currently being used to deliver containers for a wide range of the OSG Fabric of Services, the Coffea-Casa analysis facility, and the Analysis Facility at the University of Chicago; we discuss both the functionality it currently provides and the operational experiences of running a critical service for scientific cyberinfrastructure.
New particle/nuclear physics experiments require a massive amount of computing power that is only achieved by using high performance clusters directly connected to the data acquisition systems and integrated into the online systems of the experiments. However, integrating an HPC cluster into the online system of an experiment means: Managing and synchronizing thousands of processes that handle the huge throughput. In this work, modular components that can be used to build and integrate such a HPC cluster in the experiment control systems (ECS) will be introduced.
The Online Device Control library (ODC) [1] in combination with the Dynamic Deployment System (DDS) [2, 3] and FairMQ [4] message queuing library offers a sustainable solution for integrating HPC cluster controls into an ECS.
DDS as part of the ALFA framework [5] is a toolset that automates and significantly simplifies a dynamic deployment of user-defined processes and their dependencies on any resource management system (RMS) using a given process graph (topology). Where ODC is the tool to control and communicate with a topology of FairMQ processes using DDS. ODC is designed to act as a broker between a high level experiment control system and a low level task management system e.g.: DDS.
In this presentation the architecture of both DDS and ODC will be discussed, as well as the design decisions taken based on the experience gained of using these tools on production by the ALICE experiment at CERN to deploy and control thousands of processes (tasks) on the Event Processing Nodes cluster (EPN) during Run3 as a part of the ALICE O2 software ecosystem [6].
References:
1. FairRootGroup, “ODC git repository”, Last accessed 14th of November 2022: https://github.com/FairRootGroup/ODC
2. FairRootGroup, “DDS home site”, Last accessed 14th of November 2022: http://dds.gsi.de
3. FairRootGroup, “DDS source code repository”, Last accessed 14th of November 2022: https://github.com/FairRootGroup/DDS
4. FairMQ, “FairMQ git repository”, Last accessed 14th of November 2022: https://github.com/FairRootGroup/FairMQ
5.https://indico.gsi.de/event/2715/contributions/11355/attachments/8580/10508/ALFA_Fias.pdf
5. ALICE Technical Design Report (2nd of June 2015), Last accessed 14th of November: https://cds.cern.ch/record/2011297/files/ALICE-TDR-019.pdf
PUNCH4NFDI, funded by the Germany Research Foundation initially for five years, is a diverse consortium of particle, astro-, astroparticle, hadron and nuclear physics embedded in the National Research Data Infrastructure initiative.
In order to provide seamless and federated access to the huge variaty of compute and storage systems provided by the participating communities covering their very diverse needs, the Compute4PUNCH and Storage4PUNCH concepts have been developed. Both concepts comprise state-of-the-art technolgies such as a token-based AAI for standardised access to compute and storage resources. The community supplied heterogenous HPC, HTC and Cloud compute resources are dynamically and transparently integrated into one federated HTCondor based overlay batch system using the COBaLD/TARDIS resource meta-scheduler. Traditional login nodes and a JupyterHub provide entry points into the entire landscape of available compute resources, while container technologies and the CERN Virtual Machine File System (CVMFS) ensure a scalable provisioning of community specific software environments. In Storage4PUNCH, community supplied storage systems mainly based on dCache or XRootD technology are being federated in a common infrastructure employing methods that are well established in the wider HEP community. Furthermore existig technologies for caching as well as metadata handling are being evaluated with the aim for a deeper integration. The combined Compute4PUNCH and Storage4PUNCH environment will allow a large variety of researchers to carry out resource-demanding analysis tasks.
In this contribution we will present the Compute4PUNCH and Storage4PUNCH concepts, the current status of the developments as well as first experiences with scientific applications being executed on the available prototypes.
Nowadays Machine Learning (ML) techniques are successfully used in many areas of High-Energy Physics (HEP) and will play a significant role also in the upcoming High-Luminosity LHC upgrade foreseen at CERN, when a huge amount of data will be produced by LHC and collected by the experiments, facing challenges at the exascale. To favor the usage of ML in HEP analyses, it would be useful to have a service allowing to perform the entire ML pipeline (in terms of reading the data, processing data, training a ML model, and serving predictions) directly using ROOT files of arbitrary size from local or remote distributed data sources. The MLaaS4HEP solution we have already proposed aims to provide such kind of service and to be HEP experiment agnostic. Recently new features have been introduced, such as the possibility to provide pre-processing operations, defining new branches, and applying cuts. To provide users with a real service and to integrate it into the INFN Cloud, we started working on MLaaS4HEP cloudification. This would allow to use cloud resources and to work in a distributed environment. In this work, we provide updates on this topic and discuss a working prototype of the service running on INFN Cloud. It includes an OAuth2 proxy server as authentication/authorization layer, a MLaaS4HEP server, an XRootD proxy server for enabling access to remote ROOT data, and the TensorFlow as a Service (TFaaS) service in charge of the inference phase. With this architecture a HEP user can submit ML pipelines, after being authenticated and authorized, using local or remote ROOT files simply using HTTP calls.
The OSG-operated Open Science Pool is an HTCondor-based virtual cluster that aggregates resources from compute clusters provided by several organizations. A user can submit batch jobs to the OSG-maintained scheduler, and they will eventually run on a combination of supported compute clusters without any further user action. Most of the resources are not owned by, or even dedicated to OSG, so demand-based dynamic provisioning is important for maximizing usage without incurring excessive waste.
OSG has long relied on GlideinWMS for most of its resource provisioning needs, but is limited to resources that provide a Grid-compliant Compute Entrypoint. To work around this limitation, the OSG software team had developed a pilot container that resource providers could use to directly contribute to the OSPool. The problem of that approach is that it is not demand-driven, relegating it to backfill scenarios only.
To address this limitation, a demand-driven direct provisioner of Kubernetes resources has been developed and successfully used on the PRP. The setup still relies on the OSG-maintained backfill container images, it just automates the provisioning matchmaking and successive requests. That provisioner has also been recently extended to support Lancium, a green computing cloud provider with a Kubernetes-like proprietary interface. The provisioner logic had been intentionally kept very simple, making this extension a low cost project.
Both PRP and Lancium resources have been provisioned exclusively using this mechanism for almost a year with great results.
Since 1984 the Italian groups of the Istituto Nazionale di Fisica Nucleare (INFN) and Italian Universities, collaborating with the
DOE laboratory of Fermilab (US) have been running a two-month summer training program for Italian university students. While
in the first year the program involved only four physics students of the University of Pisa, in the following years it was extended
to engineering students. This extension was very successful and the engineering students have been since then extremely well
accepted by the Fermilab Technical, Accelerator and Scientific Computing Division groups. Over the many years of its existence,
this program has proven to be the most effective way to engage new students in Fermilab endeavours. Many students have
extended their collaboration with Fermilab with their Master Thesis and PhD.
Since 2004 the program has been supported in part by DOE in the frame of an exchange agreement with INFN. Over its almost
40 years of history, the program has grown in scope and size and has involved more than 550 Italian students from more than
20 Italian Universities, A number of Institutes of Research, including ASI and INAF in Italy, and the ISSNAF Foundation in the
US, have provided additional financial support. Since the program does not exclude appropriately selected non-italian students,
a handful of students of European and non-European Universities were also accepted in the years.
Each intern is supervised by a Fermilab Mentor responsible for performing the training program. Training programs spanned
from Tevatron, CMS, Muon (g-2), Mu2e and Short Baseline Neutrino Experiments and DUNE design and experimental data
analysis, development of particle detectors (silicon trackers, calorimeters, drift chambers, neutrino and dark matter detectors),
design of electronic and accelerator components, development of infrastructures and software for tera-data handling, research
on superconductive elements and on accelerating cavities, theory of particle accelerators
Since 2010, within an extended program supported by the Italian Space Agency and the Italian National Institute of Astrophysics,
a total of 30 students in physics, astrophysics and engineering have been hosted for two months in summer at US space
science Research Institutes and laboratories.
In 2015 the University of Pisa included these programs within its own educational programs. Accordingly, Summer School
students are enrolled at the University of Pisa for the duration of the internship and are identified and ensured as such. At the
end of the internship the students are required to write summary reports on their achievements. After positive evaluation by a
University Examining Board, interns are acknowledged 6 ECTS credits for their Diploma Supplement.
Information on student recruiting methods, on training programs of recent years and on final student's evaluation process at
Fermilab and at the University of Pisa will be given in the presentation.
In the ears 2020 and 2021 the Program has been canceled due to the persisting effects of the sanitary emergency which
prevented researchers and students to travel to the United States. In 2022 the Program was successfully restarted and allowed
a cohort of 21 students in physics and engineering to be trained for nine weeks at Fermilab. In the talk we will provide a detailed descriptions of the program, which can be easily taken as a model that can be easily adopted by interested Laboratories.
Providing computing training to the next generation of physicists is the
principal driver for a biannual multi-day workshop hosted by the DUNE
Computing Consortium. Materials are cast in the Software Carpentries
templates, and to date topics have included storage space, data
management, LArSoft, grid job submission and monitoring. Moreover,
experts provide extended breakout sessions to demonstrate the
intricacies of the unique software used in HEP analysis. Each workshop
session uses live documents for real time correspondence, and are
captured on Zoom; afterwards, videos are embedded on the corresponding
webpages for review. As a GitHub repository, shared editing of the
learning modules is straightforward, and provides a trusted framework to
extend to other training topics in the future. An overview of the
machinery will be provided, post workshop statistics will be discussed,
with lessons learned will be the focus of this presentation.
The common form of inter-institute particle physics experiment collaborations generates unique needs for member management including paper authorship, shift assignments, subscription to mailing lists and access to 3rd party applications such as Github and Slack. For smaller collaborations, typically no facility for centralized member management is available and these needs are usually manually handled by long-term members in smaller collaborations but the management becomes tedious as collaborations grow. To automate many of these tasks for the expanding XENON collaboration, we developed the XENONnT User Management Website, a web application that stores and updates data related to the collaboration members through the use of NodeJs and MongoDB. The application allows for the scheduling of shifts for members to coordinate between institutes. User manipulation of 3rd party applications are implemented using REST API integration. The XENONnT User Management Website is open source and is a show case of quick implementation of utility application using the web framework.
We will discuss the training and on-boarding initiatives currently adopted by a range of High Energy Physics (HEP) experiments. On-boarding refers to the process by which new members of a collaboration gain the knowledge and skills needed to become effective members. Fast and efficient on-boarding is increasingly important for HEP experiments as physics analyses and, as a consequence, the related software becomes ever more complex with growing datasets. The HEP Software Foundation (HSF) held a meeting series in Summer 2022 where 6 LHC and non-LHC experiments showcased their initiatives. Here we summarise and analyse these initiatives and attempt to determine a set of best practices for current and future experiments.
Building successful multi-national collaborations is challenging. The scientific communities in a range of physical sciences have been learning how to build collaborations that build upon regional capabilities and interests over decades, iteratively with each new generation of large scientific facilities required to advance their scientific knowledge. Much of this effort has naturally focused on collaborations for the construction of hardware and instrumentation. Software has however also become a critical element to design and maximize the physics discovery potential of large data intensive science projects. To fully realize their discovery potential a new generation of software algorithms and approaches is required. Building these research software collaborations is challenging and inherently international, matching the international nature of the experimental undertakings themselves. Initiatives such as the HEP Software Foundation have been instrumental in establishing international research software collaborations in high-energy physics, in particular between European and North American researchers.
This talk is about a new initiative, HSF-India, aiming to implement new and impactful research software collaborations between India, Europe and the U.S. The experimental scope of this project is relatively broad, aiming to bring together researchers across facilities with common problems in research. The research and development scope is on three primary topics: analysis software and integrated facilities for analysis; simulation techniques including generators and Artificial Intelligence based approaches; and enabling open science. By exploiting national capabilities and strengths, an immediate mutual benefit of the international collaboration will be a training network that enables early-career researchers to pursue impactful research software initiatives in ways that advance their careers in experimental data-intensive science. In this presentation, we will describe the scope of this initiative, its mechanisms for fostering new collaborations, and ways for interested research groups to get involved. We will also discuss thoughts towards broadening our initiative to foster more general collaborations in research software projects between Asian researchers and European/North American researchers who are already jointly pursuing “team-science” endeavors in research software for high-energy, nuclear and astro-particle physics.
The Italian WLCG Tier-1 located in Bologna and managed by INFN-CNAF has a long tradition in supporting several research communities in the fields of High-Energy Physics, Astroparticle Physics, Gravitational Waves, Nuclear Physics and others, to which provides computing resources in the form of batch computing, both HPC, HTC and Cloud, and storage. Although the LHC experiments at CERN represent the main users of the Tier-1 resources, an increasing number of communities and experiments are also being supported in all of their computing activities. Due to this demanding user base, an efficient support system is needed in order to assure a smooth and appropriate exploitation of the computing infrastructure.
In this framework, such a role is played by the Tier-1 User Support group, which acts as the entry point for services, support requests, and problem reports. The group makes use of multiple systems to meet the different needs and specificities of the supported experiments. Moreover, the group continuously maintains detailed knowledge base in the form of an on-line user guide and develops tools to advertise specific informations about the services available to the communities in a form that is easy to access and use.
The communication channels are represented by ticketing systems and also by mailing lists used for a more direct communication, allowing to promptly notify maintenance interventions, downtimes and more in general all the new features and services provided by the center.
In this talk, the ticketing systems, tools, platforms and services that User Support offers, and the internal organization of the department will be described. Future workflow plans in view of the DATACLOUD project, which will require an increasing effort, will also be presented.
Hadronization is an important step in Monte Carlo event generators, where quarks and gluons are bound into physically observable hadrons. Today’s generators rely on finely-tuned empirical models, such as the Lund string model; while these models have been quite successful overall, there remain phenomenological areas where they do not match data well. In this talk, we present MLHad, a machine-learning-based alternative for generating hadronization chains, which we intend ultimately to be data-trainable. Latent-space vectors are encoded, trained to be distributed according to a user-defined distribution using the sliced-Wasserstein distance in the loss function, then decoded to simulate hadronization.
We show that generated pion multiplicities and cumulative kinematic distributions match those generated using Pythia (arXiv:2203.04983). We also present our more-recent work using normalizing flows to generate non-pion hadrons and to propagate errors through the encoder and decoder. Finally, we present comparisons with empirical data.
The calculation of particle interaction squared amplitudes is a key step in the calculation of cross sections in high-energy physics. These lengthy calculations are currently done using domain-specific symbolic algebra tools, where the time required for the calculations grows rapidly with the number of final state particles involved. While machine learning has proven to be highly successful in numerical calculations in high-energy physics, analytical calculations using machine learning are still in their beginning. We developed a transformer-based sequence-to-sequence model inspired by natural language processing that is able to accurately predict squared amplitudes of QCD and QED processes, respectively, when trained on symbolic sequence pairs. The goal of this work is to significantly reduce the computational time and, more importantly, build a model that scales well with the number of final state particles. To the best of our knowledge, this model (SYMBA) is the first model that encapsulates a wide range of symbolic squared amplitude calculations and, therefore, represents a potentially significant advance in using symbolic machine learning techniques for practical scientific computations.
The recent advances in Machine Learning and high-dimensional gradient-based optimization has led to increased interest in the question of whether we can use such methods to optimize the design of future detectors for high-level physics objectives. However this program faces a fundamental obstacle: The quality of a detector design must be judged on the physics inference it enables, but both simulation and reconstruction of events are to a large degree described by discrete and thus naively non-differentiable stochastic branching (e.g. particle showers, ) and clustering processes (e.g. jet algorithms). In this work we explore the use of gradient estimation techniques based on differentiable and probabilistic programming that provide sufficiently stable estimates such that they may be used in an optimization loop. We showcase the effectiveness of such methods in benchmark scenarios ranging from a few to many thousands of optimizable parameters and discuss current limitations and future directions.
We present a Multi-Module framework based on Conditional Variational Autoencoder (CVAE) to detect anomalies in the High Voltage Converter Modulators (HVCMs) which have historically been a cause of major down time for the Spallation Neutron Source (SNS) facility. Previous studies using machine learning techniques were to predict faults ahead of time in the SNS accelerator using a Single Modulator. Using the proposed methodology, we can detect faults in the power signals coming from multiple HVCMs that vary in design specifications and operating conditions. By conditioning the model according to the given modulator system, we can capture different representations of the normal waveforms for multiple systems. Our experiments with the SNS experimental data show that the trained model generalizes well to detecting several fault types for different systems, which can be valuable to improve the HVCM reliability and SNS as a result. We also explore several neural network architectures in our CVAE model by visualizing their loss landscapes to study the stability and generalization of the developed models and assist in hyper-parameter optimization and model selection to produce well-performed predictions.
Significant advances in utilizing deep learning for anomaly detection have been made in recent years. However, these methods largely assume the existence of a normal training set (i.e., uncontaminated by anomalies), or even a completely labeled training set. In many complex engineering systems, such as particle accelerators, labels are sparse and expensive; in order to perform anomaly detection in these cases, we must drop these assumptions and utilize a completely unsupervised method. Moreover, only identifying the anomaly is insufficient: operators of these complex systems need additional localization information to identify the root cause of the anomaly and make an informed response. In this paper, we introduce the Resilient Variational Autoencoder (ResVAE), a deep generative model that is designed for anomaly detection, is resilient to anomalies in the training data, and yields feature-level anomaly attribution. During training, the ResVAE learns the anomaly probability for each sample as a whole and for each individual feature, and uses those probabilities to ignore anomalous examples in the training data. We apply our method to detecting anomalies in the accelerator status at the SLAC Linac Coherent Light Source (LCLS). Using shot-to-shot data from the beam position monitoring system, we identify and characterize several types of anomalies apparent in the accelerator, including many instances of known failures modes (e.g., beam loss) that are missed by current detection methods.
The MoEDAL experiment at CERN (https://home.cern/science/experiments/moedal-mapp) carries out searches for highly ionising exotic particles such as magnetic monopoles. One of the technologies deployed in this task is the Nuclear Track Detector (NTD). In the form of plastic films, these are passive detectors that are low cost and easy to handle. After exposure to the LHC collision environment in the LHCb cavern at point 8 on the LHC ring, they are etched and scanned under a microscope to potentially reveal the etch-pit signature of the passage of an exotic highly ionising particle. The scanning process takes place using microscopes and expert human inspection. With several 10s of metres squared of deployed plastic, and large backgrounds complicating the analysis, the process is highly time consuming.
We have studied the use of AI to identify etch-pits in scanned images of NTDs. A specially prepared stack of NTD plastic films – where one layer has been exposed to the harsh LHC environment and the others have not – is placed in a heavy ion beam to simulate the passage of particles such as magnetic monopoles. The plastic is then etched and optically scanned. The images are used to prepare training and evaluation data sets for three different approaches: a deconvolution-convolution algorithm with machine learning based thresholding, a convolutional neural network, trained as a classifier and then used in a fully convolutional mode, and a convolutional neural network making use of a U-Net based technique.
We present an overview of MoEDAL and our study, the evaluation of the methods, and the prospects for further uses of AI in this area.
Next generation High-Energy Physics (HEP) experiments are presented with significant computational challenges, both in terms of data volume and processing power. Using compute accelerators, such as GPUs, is one of the promising ways to provide the necessary computational power to meet the challenge. The current programming models for compute accelerators often involve using architecture-specific programming languages promoted by the hardware vendors and hence limit the set of platforms that the code can run on. Developing software with platform restrictions is especially unfeasible for HEP communities as it takes significant effort to convert typical HEP algorithms into ones that are efficient for compute accelerators. Multiple performance portability solutions have recently emerged and provide an alternative path for using compute accelerators, which allow the code to be executed on hardware from different vendors.
We apply several portability solutions, such as Kokkos, SYCL, std::execution::par and Alpaka, on two mini-apps extracted from the mkFit project: p2z and p2r. These apps include basic kernels for a Kalman filter track fit, such as propagation and update of track parameters, for detectors at a fixed z or fixed r position, respectively. The two mini-apps explore different memory layout formats.
We report on the development experience with different portability solutions, as well as their performance on GPUs and many-core CPUs, measured as the throughput of the kernels from different GPU and CPU vendors such as NVIDIA, AMD and Intel.
INFN has been running for more than 20 years a distributed infrastructure (the Tier-1 at Bologna-CNAF and 9 Tier-2 centers) which currently offers about 140000 CPU cores, 120 PB of enterprise-level disk space and 100 PB of tape storage, serving more than 40 international scientific collaborations.
This Grid-based infrastructure was augmented in 2019 with the INFN Cloud: a production quality multi-site federated Cloud infrastructure, composed by a core backbone, and which is able to integrate other INFN sites and public or private Clouds as well. The INFN Cloud provides a customizable and extensible portfolio offering computing and storage services spanning the IaaS, PaaS and SaaS layers, with dedicated solutions to serve special purposes, such as ISO-certified regions for the handling of sensitive data.
INFN is now revising and expanding its infrastructure to tackle the challenges expected in the next 10 years of scientific computing adopting a “cloud-first” approach, through which all the INFN data centers will be federated via the INFN Cloud middleware and integrated with key HPC centers, such as the pre-exascale Leonardo machine at CINECA.
In such a process, which involves both the infrastructures and the higher level services, initiatives and projects such as the "Italian National Centre on HPC, Big Data and Quantum Computing" (funded in the context of the Italian "National Recovery and Resilience Plan") and the Bologna Technopole are precious opportunities that will be exploited to offer advanced resources and services to Universities, research institutions and industry.
In this paper we describe how INFN is evolving its computing infrastructure, with the ambition to create and operate a national vendor-neutral, open, scalable and flexible "data lake" able to serve much more than just INFN users and experiments.
RED-SEA (https://redsea-project.eu/) is a European project funded in the framework of the H2020-JTI-EuroHPC-2019-1 call that started in April 2021. The goal of the project is to evaluate the architectural design of the main elements of the interconnection networks for the next generation of HPC systems supporting hundreds of thousands of computing nodes enabling the Exa-scale for HPC, HPDA and AI applications, and to provide preliminary prototypes.
The main technological feature is the BXI network, originally designed and produced by ATOS (France). The plan is to integrate in the next release of the network – BXI3 – the architectural solutions and novel IPs developed within the framework of the RED-SEA project.
The consortium is composed of 11 well-established research teams across Europe, with extensive experience in interconnects, including network design, deployment and evaluation.
Within RED-SEA INFN is adopting a hardware/software co-design approach to design APEnetX, a scalable interconnect prototyped on latest generation Xilinx FPGAs, adding innovative components for the improvement of the performance and resiliency of the interconnect. APEnetX is an FPGA-based, PCIe Gen3/4 network interface card equipped with RDMA capabilities being the endpoint of a direct multidimensional toroidal network and suitable to be integrated in the BXI environment. APEnetX design will be benchmarked on project testbeds using real scientific applications like NEST, a spiking neural network simulator.
In this presentation we introduce the main scientific and technological motivations at the basis of the project, focusing on the current status of the development.
ICSC is one of the five Italian National Centres created in the framework of the Next Generation EU funding by the European Commission. The aim of ICSC, designed and approved through 2022 and eventually started in September 2022, is to create the national digital infrastructure for research and innovation, leveraging exixting HPC, HTC and Big Data infrastructures evolving towards a cloud datalake model. It will be accessible by the scientific and industrial communities through flexible and uniform cloud web interfaces, and will be relying on a high-level support team; as such, it will form a globally attractive ecosystem based on strategic public-private partnerships to fully exploit top level digital infrastructure for scientific and technical computing and promote the development of new computing technologies.
The ICSC IT infrastructure is built upon existing scientific digital infrastructures provided by the major national players: GARR, the Italian NREN, provides the network infrastructure, whose capacity will be upgraded to multiples of Tbps; CINECA hosts Leonardo, one of the world largest HPC systems, with a power of over 250 Pflops, that will be further increased and complemented with a quantum computer; INFN contributes with its distributed Big Data cloud infrastructure, built in the last decades to respond to the needs of the High Energy Physics community.
On top of the IT infrastructure, several thematic activities will be funded and will focus on the development of tools and applications in several research domains. Of particular relevance to this audience are the activities on "Fundamental Research and Space Economy" and "Astrophysics and Cosmos Observations", strictily aligned with the INFN and HEP core activities. Finally two technological research activities will foster research on "Future HPC and Big Data" and "Quantum Computing".
In this contribution, the organisation of the National Centre and its relevance for the HEP community will be presented.
The upcoming exascale computers in the United States and elsewhere will have diverse node architectures, with or without compute accelerators, making it a challenge to maintain a code base that is performance portable across different systems. As part of the US Exascale Computing Project (ECP), the USQCD collaboration has embarked on a collaborative effort to prepare the lattice QCD software suites for exascale, with a particular focus on achieving performance portability across diverse exascale architectures.
In this presentation, I will focus on efforts to use compiler directives, OpenMP and OpenACC, to port the Grid C++ lattice QCD library to AMD/Intel/NVIDIA GPUs and multi/many-core CPUs. Performance comparisons with architecture-native implementations in HIP, SYCL and CUDA will be given. I will also discuss the problems encountered and pros and cons of using compiler directives for performance portability.
Opticks is an open source project that accelerates optical photon simulation by
integrating NVIDIA GPU ray tracing, accessed via the NVIDIA OptiX 7 API, with
Geant4 toolkit based simulations. A single NVIDIA Turing architecture GPU has
been measured to provide optical photon simulation speedup factors exceeding
1500 times single threaded Geant4 with a full JUNO analytic GPU geometry
automatically translated from the Geant4 geometry. Optical physics processes of
scattering, absorption, scintillator reemission and boundary processes are
implemented in CUDA based on Geant4. Wavelength-dependent material and surface
properties as well as inverse cumulative distribution functions for reemission
are interleaved into GPU textures providing fast interpolated property lookup
or wavelength generation.
In this work we describe the near complete re-implementation of geometry and
optical simulation required to adopt the entirely new NVIDIA OptiX 7 API, with
the implementation now directly CUDA based with OptiX usage restricted to
providing intersects. The new Opticks features a modular many small header
design that provides fine grained testing both on GPU and CPU as well as
substantial code reductions from CPU/GPU sharing. Enhanced modularity has
enabled CSG tree generalization to support "list-nodes", similar to
G4MultiUnion, that improve performance for complex CSG solids. Recent addition
of support for interference effects in boundaries with multiple thin layers,
such as anti-reflection coatings and photocathodes, using CUDA compatible
transfer matrix method (TMM) calculations of reflectance, transmittance and
absorptance is also reported.
The Large Hadron Collider (LHC) experiments distribute data by leveraging a diverse array of National Research and Education Networks (NRENs), where experiment data management systems treat networks as a “blackbox” resource. After the High Luminosity upgrade, the Compact Muon Solenoid (CMS) experiment alone will produce roughly 0.5 exabytes of data per year. NREN Networks are a critical part of the success of CMS and other LHC experiments. However, during data movement, NRENs are unaware of data priorities, importance, or need for quality of service, and this poses a challenge for operators to coordinate the movement of data and have predictable data flows across multi-domain networks. The overarching goal of SENSE (The Software-defined network for End-to-end Networked Science at Exascale) is to enable National Labs and universities to request and provision end-to-end intelligent network services for their application workflows leveraging SDN (Software-Defined Networking) capabilities. This work aims to allow LHC Experiments and Rucio, the data management software used by CMS Experiment, to allocate and prioritize certain data transfers over the wide area network. In this paper, we will present the current progress of the integration of SENSE, Multi-domain end-to-end SDN Orchestration with QoS (Quality of Service) capabilities, with Rucio, the data management software used by CMS Experiment.
We present an NDN-based Open Storage System (OSS) plugin for XRootD instrumented with an accelerated packet forwarder, built for data access in the CMS and other experiments at the LHC, together with its current status, performance as compared to other tools and applications, and plans for ongoing developments.
Named Data Networking (NDN) is a leading Future Internet Architecture where data in the network is accessed directly by its name rather than the location of the data containers (hosts). NDN enables the joint design of multipath forwarding and caching to achieve superior latency and failover performance. The Caltech team, together with Northeastern University, UCLA, Tennessee Tech and other collaborators from the NDN for Data Intensive Science Experiments (N-DISE) project, has implemented (1) a small C++ NDN library (NDNc) to bridge the existing NDN libraries with the new high-throughput NDN-DPDK forwarder developed by NIST, (2) a corresponding NDN naming scheme for accessing datasets in the network, (3) two basic classes of entities for transferring data in NDN: consumer and producer, and (4) an NDN-based OSS plugin for XRootD.
The XRootD plugin offers implementation for all filesystem related calls (e.g., open, read, close) and it embeds the NDN consumer that translates these calls to NDN Interest packets using well-established naming conventions. For example, the Interest for a read operation for the third segment from a file at /path/to/foo location on disk has the corresponding name /ndnc/ft/path/to/foo/v=1/seg=3. Once Interest packets are assembled, they are passed to a proxy entity which forwards them to the local interface. The proxy provides reliable data fetching by handling timeouts and retransmissions, and can adopt different congestion control algorithms (e.g., fixed window size, or congestion-aware AIMD). The local interface implements a memif shared memory packet interface, providing high-performance packet transmission to and from the local NDN-DPDK forwarder. NDN Interest packets find nearest copies of requested data on the NDN network, from either in-network caches or data producers. Alongside this plugin, a corresponding producer has been implemented, which can communicate with multiple file systems (CEPH, HDFS); upon receiving Interest packets, the producer responds with data packets that encapsulate byte ranges at proper offsets from an existing file indicated by the segment numbers of received Interest packets.
In this paper we present the architecture of the NDNc library, the consumer application and the NDN-based XRootD plugin. We will also present the throughput performance of the plugin over a continental-scale wide area network testbed, in comparison with other tools and applications used for accessing data at the CMS experiment.
There is increasing demand for the efficiency and flexibility of data transport systems supporting data-intensive sciences. With growing data volume, it is essential that the transport system of a data-intensive science project fully utilize all available transport resources (e.g., network bandwidth); to achieve statistical multiplexing gain, there is an increasing trend that multiple projects share the same transport infrastructure, but the wide deployment of a shared infrastructure requires flexible resource control. In this talk, we first conduct a rigorous analysis of existing data transport systems and show that considering the infrastructures as a black box can limit efficiency and flexibility. We then introduce ALTO/TCN, a new architecture that introduces deep infrastructure visibility to achieve efficient, flexible data transport. We will provide additional details on 3 key components to realize the architecture: (1) how to achieve infrastructure visibility in multi-domain networks, using the Internet Engineering Task Force (IETF) Application-Layer Traffic Optimization (ALTO) protocol and the openalto.org visibility orchestrator; (2) how to integrate visibility into transport scheduling optimization, with zero-orde/first-order gradient and time-multiplexing control, using FTS integration as an example; and (3) how to integrate visibility into data selection orchestration, with general distances as a visibility abstraction, using Rucio integration as an example. We will report evaluation results and implementation lessons. We conclude with planning for the next steps, in particular, how the project complements existing related efforts in HEP, such as application awareness (e.g., packet marking) and adaptive networking resource allocation (e.g., NOTED/SENSE/AutoGOLE).
In 2029 the LHC will start the High-Luminosity LHC (HL-LHC) program, with a boost in the integrated luminosity resulting in an unprecedented amount of experimental and simulated data samples to be transferred, processed and stored in disk and tape systems across the Worldwide LHC Computing Grid (WLCG). Content delivery network (CDN) solutions are being explored with the purposes of improving the performance of the compute tasks reading input data via the Wide Area Network (WAN), and also to provide a mechanism for cost-effective deployment of lightweight storages supporting traditional or opportunistic compute resources. In this contribution we study the benefits of applying cache solutions for the CMS experiment, in particular the configuration and deployment of xCache serving data to two Spanish WLCG sites supporting CMS: the Tier-1 site at PIC and the Tier-2 site at CIEMAT. The deployment and configuration of the system and the developed monitoring tools will be shown, as well as data popularity studies in relation to the optimization of the cache configuration, the effects on CPU efficiency improvements for analysis tasks, and the cost benefits and impact of including this solution in the region.
The High-Energy Physics (HEP) and Worldwide LHC Computing Grid (WLCG) communities have faced significant challenges in understanding their global network flows across the world’s research and education (R&E) networks. When critical links, such as transatlantic or transpacific connections, experience high traffic or saturation, it is very challenging to clearly identify which collaborations are generating the traffic and what activity that traffic represents. Without knowing the owner and the purpose of the traffic, we are unable to alert them or mitigate the issue. In general, the HEP and WLCG communities found they have insufficient visibility into which experiments are creating the flows and their purpose. Having such visibility also allows new understanding of scientific workflows and their associated resource use, and allows organizations and network providers to demonstrate the value of their participation
The Research Networking Technical Working Group was formed in the spring of 2020, partially in response to this challenge. The first of its three working areas concerns network visibility; specifically, the use of packet marking or flow marking to identify the owner and associated activity of network traffic. The SciTags initiative was created to push this into production, not just for HEP/WLCG, but for any global users of R&E networks.
We will describe the status of the work to date, including the evolving architecture and tools, as well as our plans to get this capability into production before the next WLCG Network Data Challenge in early 2024.
The capture and curation of all primary instrument data is a potentially valuable source of added insight into experiments or diagnostics in laboratory experiments. The data can, when properly curated, enable analysis beyond the current practice that uses just a subset of the as-measured data. Complete curated data can also be input for machine learning and other data exploration tools. Conveniently storing and accessing instrument data requires that the instruments are connected to databases and users through a networking infrastructure. This infrastructure needs to accommodate a wide array of instruments which can range from single laboratory mounted probes for environment monitoring to computers managing multiple instruments. These resources may also include mobile devices on which researchers record instrument and experiment state related notes. These varied data sources bring with them the challenges of different communications capabilities and protocols as well as the primary data typically being produced in proprietary formats. These challenges are further compounded when the instruments need to operate in secure environments such as required in national laboratories.
We will discuss the SmartLab, an ongoing effort to set up a system for instrument and simulation data curation at NASA Langley Research Center. We will outline the challenges faced in managing the data sources required for ongoing research activities and the solutions that are being considered and implemented to address those challenges.
The CMS collaboration has chosen a novel high granularity calorimeter (HGCAL) for the endcap regions as part of its planned upgrade for the high luminosity LHC. The calorimeter will have fine segmentation in both the transverse and longitudinal directions and will be the first such calorimeter specifically optimised for particle flow reconstruction to operate at a colliding-beam experiment. The calorimeter data will be part of the Level 1 trigger of the CMS experiment and, together with tracking information that will also be available, will allow particle-flow techniques to be used as part of this trigger. The trigger has tight constraints on latency and rate, and will need to be implemented in hardware. The high granularity results in around six million readout channels in total, reduced to one million that are used at 40 MHz as part of the Level 1 trigger, presenting a significant challenge in terms of data manipulation and processing for the trigger system; the trigger data volumes will be an order of magnitude above those currently handled at CMS. In addition, the high luminosity will result in an average of 140 (or more) interactions per bunch crossing that give a huge background rate in the forward region and these will need to be efficiently rejected by the trigger algorithms. Furthermore, reconstruction of the particle clusters to be used for particle flow in events with high hit rates is also a complex computational problem for the trigger. The status of the cluster reconstruction algorithms developed to tackle these major challenges, as well as the associated trigger architecture, will be presented.
Fast, efficient and accurate triggers are a critical requirement for modern high energy physics experiments given the increasingly large quantities of data that they produce. The CEBAF Large Acceptance Spectrometer (CLAS12) employs a highly efficient Level 3 electron trigger to filter the amount of data recorded by requiring at least one electron in each event, at the cost of a low purity in electron identification. However, machine learning algorithms are increasingly employed for classification tasks such as particle identification due to their high accuracy and fast processing times. In this article we show how a convolutional neural network could be deployed as a Level 3 electron trigger at CLAS12. We demonstrate that the AI trigger would achieve a significant data reduction compared to the traditional trigger, whilst preserving a 99.5% electron identification efficiency. The AI trigger purity also improves relative to the traditional trigger with increased luminosity, as the AI trigger can achieve a reduction in recorded data with respect to the traditional trigger that increases at a rate of 0.32% per nA whilst keeping a stable efficiency above 99.5%.
Long-lived particles (LLPs) are very challenging to search for with current detectors and computing requirements, due to their very displaced vertices. This study evaluates the ability of the trigger algorithms used in the Large Hadron Collider beauty (LHCb) experiment to detect long-lived particles and attempts to adapt them to enhance the sensitivity of this experiment to undiscovered long-lived particles. One of the challenges in the track reconstruction is to deal with the large amount of combinatorics of hits. A dedicated algorithm has been developed to cope with the large data output. When fully implemented, this algorithm would greatly increase the available statistics for any long-lived particle search in the forward region, for the Standard Model of particle physics and beyond.
The Phase-2 Upgrade of the CMS Level-1 Trigger will reconstruct particles using the Particle Flow algorithm, connecting information from the tracker, muon, and calorimeter detectors, and enabling fine-grained reconstruction of high level physics objects like jets. We have developed a jet reconstruction algorithm using a cone centred on an energetic seed from these Particle Flow candidates. The implementation is designed to find up to 16 jets in each Xilinx Ultrascale+ FPGA, with a latency of less than 1 μs, and event throughput of 6.7 MHz to fit within the L1T system constraints. Pipelined processing enables reconstruction of jet collections with different cone sizes for little additional resource cost. The design of the algorithm also provides a platform for additional computation using the jet constituents, such as jet tagging using neural networks. In this talk we will describe the implementation, its jet reconstruction performance, computational metrics, and the developments towards jet tagging.
The CMS experiment has greatly benefited from the utilization of the particle-flow (PF) algorithm for the offline reconstruction of the data. The Phase II upgrade of the CMS detector for the High Luminosity upgrade of the LHC (HL-LHC) includes the introduction of tracking in the Level-1 trigger, thus offering the possibility of developing a simplified PF algorithm in the Level-1 trigger. We present the logic of the algorithm, along with its inputs and its firmware implementation. We show that this implementation is capable of operating under the limited timing and processing resources available in the Level-1 trigger environment. The expected performance and physics implications of such an algorithm are shown using Monte Carlo samples with hιgh pile-up, simulating the harsh conditions of the HL-LHC. New calorimeter features allow for better performance under high pileup (PU) to be achieved, provided that careful tuning and selection of the prompt clusters has been made. Additionally, advanced pile-up techniques are needed to preserve the physics performance in the high-intensity environment. We present a method that combines all information yielding PF candidates and performs Pile-Up Per Particle Identification (PUPPI) capable of running in the low latency level-1 trigger environment. Demonstration of the algorithm on dedicated hardware relying on ATCA platform is presented
The current and future programs for accelerator-based neutrino imaging detectors feature the use of Liquid Argon Time Projection Chambers (LArTPC) as the fundamental detection technology. These detectors combine high-resolution imaging and precision calorimetry to enable the study of neutrino interactions with unparalleled capabilities. However, the volume of data from LArTPCs will exceed 25 Petabytes each year for DUNE (Deep Underground Neutrino Experiment) and event reconstruction techniques are complex, requiring significant computational resources. These aspects of LArTPC data make utilization of real-time event triggering and event filtering algorithms that can distinguish signal from background important, but still challenging to accomplish with reasonable efficiency especially for low energy neutrino interactions. At Fermilab, we are developing a machine-learning-based trigger and filtering algorithm for the lab's flagship experiment DUNE, to extend the sensitivity of the detector, particularly for low energy neutrinos that do not come from an accelerator beam. Building off of recent research in machine learning to improve artificial intelligence, this new trigger algorithm will employ software to optimize data collection, pre-processing, and to make a final event selection decision. Development and testing of the trigger decision system will leverage data from MicroBooNE, ProtoDUNE, and Short Baseline Neutrino (SBN) LArTPC detectors, and will also provide benefits to the physics programs of those experiments.
This talk will focus on application of a Convolutional Neural Network (CNN) to MicroBooNE data and will study performance metrices such as memory usage and latency. We will also discuss progress towards applying a Semantic Segmentation with Sparse Convolutional Network (SparseCNN) on the same data and compare the performance of the two algorithms.
The AGATA project (1) aims at building a 4pi gamma-ray spectrometer consisting of 180 germanium crystals, each crystal being divided into 36 segments. Each gamma ray produces an electrical signal within several neighbouring segments, which is compared with a data base of reference signals, enabling to locate the interaction. This step is called Pulse-Shape Analysis (PSA).
In the execution chain leading to the PSA, we observe successive data conversions : the original 14 bits integers given by the electronics are finally converted to 32-bit floats. This made us wonder about the real numerical accuracy of the results, and investigate the use of shorter floats, with the hope to speedup the computation, and also reduce a major cache-miss problem previously identified with the Perf (2) tool.
Our proposed talk would first report about the numerical validation of the C++ PSA code, thanks to the Discrete Stochastic Arithmetic implemented in the CADNA library (3). After the code being properly instrumented, CADNA performs each computation three times with a random rounding mode. This allows, for each operation, to evaluate the number of exact significant digits using a Student test with 95% confidence threshold.
In a second step, we will report our successes and challenges while refactoring the code so to mix different numerical formats, using high precision only when necessary, and taking benefit of hardware speedup elsewhere. Such mixed-precision appears as a promising option for high performance computation in the next years, provided we use tools such as CADNA so to keep control of the accuracy of the computed results.
(1) https://www.agata.org/about
(2) https://perf.wiki.kernel.org/index.php/Main_Page
(3) http://cadna.lip6.fr
Track reconstruction, also known as tracking, is a vital part of the HEP event reconstruction process, and one of the largest consumers of computing resources. The upcoming HL-LHC upgrade will exacerbate the need for efficient software able to make good use of the underlying heterogeneous hardware. However, this evolution should not imply the production of code unintelligible to most of its maintainers, hence the need to provide good usability to both end users and developers.
C++ has been a language of choice for efficient scientific computing tasks. The Generative Programming paradigm [CZAR98], which relies on heavy type based template meta-programming, provides a powerful solution for supporting multiple execution contexts[MASL16]. Yet, the templates are usually blamed for binary bloat, high code complexity and unreadable error messages.
In this presentation, we will discuss recent developments made to the C++ language, helping to define a new process for constructing libraries both efficient and easy to use, using a streamlined Generative Programming process:
• easier code selection at compile time using “if constexpr”
• better error reporting using “Concepts”, i.e. compile-time type constraints
• easier meta-programming with Non-Type Template Parameters
We will then introduce Kiwaku[KWK22], a new multidimensional arrays library taking advantage of the most recent C++ usability improvements, yet providing portable performance on various execution contexts (CPU, GPU). We will finally discuss a few proofs of concept, based on use-cases borrowed from the ACTS toolkit[ACTS22]: magnetic field computation, clustering and seeding.
References:
[ACTS22] Ai, X., Allaire, C., Calace, N. et al. A Common Tracking Software Project. Comput Softw Big Sci 6, 8 (2022). https://doi.org/10.1007/s41781-021-00078-8
[CZAR98] Krzysztof Czarnecki, Ulrich W. Eisenecker, Robert Glück, David Vandevoorde, Todd L. Veldhuizen: "Generative Programming and Active Libraries". Generic Programming 1998: 25-39
[KWK22] Kiwaku main repository - https://github.com/jfalcou/kiwaku/
[MASL16] Ian Masliah, Marc Baboulin, Joel Falcou: "Meta-programming and Multi-stage Programming for GPGPUs". 2016 IEEE 10th International Symposium on Embedded Multicore/Many-core Systems-on-Chip (MCSOC)
The LHCb software stack is developed in C++ and uses the Gaudi framework for event processing and DD4hep for the detector description. Numerical computations are done either directly in the C++ code or by an evaluator used to process the expressions embedded in the XML describing the detector geometry.
The current system relies on conventions for the physical units used (identical as what is used in the Geant4 simulation framework) and it is up to the developers to ensure that the correct factors are applied to the values entered. Physical units are not primary entities in the framework, it is therefore not possible to check the dimensional consistency of the computation performed. In this paper we investigate the possibilities to add physical units and dimensions to the existing evaluator or to replace it by a more suitable system, and how this would integrate with the possible tools to express units in C++ code (such as boost::units).
Applying graph-based techniques, and graph neural networks (GNNs) in particular, has been shown to be a promising solution to the high-occupancy track reconstruction problems posed by the upcoming HL-LHC era. Simulations of this environment present noisy, heterogeneous and ambiguous data, which previous GNN-based algorithms for ATLAS ITk track reconstruction could not handle natively. We present a range of upgrades to the so-called GNN4ITk pipeline that allow detector regions to be handled heterogeneously, ambiguous and shared nodes to be reconstructed more rigorously, and tracks-of-interest to be treated with more importance in training. With these improvements, we are able to present for the first time apples-to-apples comparisons with existing reconstruction algorithms on a range of physics metrics, including reconstruction efficiency across particle type and pileup condition, jet reconstruction performance in dense environments, displaced tracking, and track parameter resolutions. We also demonstrate that our results are robust to misalignment of ITk modules, showing the GNN4ITk approach to perform well under changing experimental conditions. By integrating this solution with the offline ATLAS Athena framework, we also explore a range of reconstruction chain configurations, for example by using the GNN4ITk pipeline to build regions-of-interest while using traditional techniques for track cleaning and fitting.
The Belle II experiment has been accumulating data since 2019 at the SuperKEKB $e^+e^-$ accelerator in Tsukuba, Japan. The accelerator operates at the $\Upsilon(4S)$ resonance and is an excellent laboratory for precision flavor measurements and dark sector searches. The accumulated data are promptly reconstructed and calibrated at a dedicated calibration center in an automated process based on a directed acyclic graph to resolve dependencies in the calibration using selected prescaled data skims. After calibration, the raw data are reconstructed on the GRID and provided in an analysis-oriented format (mDST) on the GRID for the collaboration.
In this talk we will present the calibration data flow from raw data to mDST production. We will discuss the physical principles behind the calibrations and how we tune the calibration data samples accordingly. We will show performance metrics which underpin the importance of the data calibration for our precision physics results.
Development of the EIC project detector "ePIC" is now well underway and this includes the "single software stack" used for simulation and reconstruction. The stack combines several non-experiment-specific packages including ACTS, DD4hep, JANA2, and PODIO. The software stack aims to be forward looking in the era of AI/ML and heterogeneous hardware. A formal decision making process was implemented to choose the components that involved everyone in the collaboration that was interested. This talk will present an overview of the software stack currently used for development of the ePIC detector and on which we expect to execute the experiment.
IDEA (Innovative Detector for an Electron-positron Accelerator) is an innovative general-purpose detector concept, designed to study electron-positron collisions at future e$^+$e$^-$ circular colliders (FCC-ee and CEPC).
The detector will be equipped with a dual read-out calorimeter able to measure separately the hadronic component and the electromagnetic component of the showers initiated by the impinging hadrons.
Particle flow algorithms (PFAs) have become the paradigm of detector design for the high energy frontier and this talk discusses a project to build a Particle Flow algorithm for the IDEA detector using Machine Learning (ML) techniques. Machine Learning is used for particle reconstruction and identification profiting of the high granularity of the fiber-based dual-readout calorimeter. Neural Networks (NN) are built for electron, pions, neutral kaons, muons reconstruction and identification inside the calorimeter and for the jet reconstruction. The performances of the algorithm using several NN architectures will be shown, with particular attention to the layer setup and the activation function choices. The performances will be evaluated on the resolution function of the reconstructed particles and of the reconstructed jet. The algorithm will be trained using both parallel CPUs and GPU, and the time performances and the memory usage of the two approaches will be systematically compared.
Finally, the aim of the project is to develop the NN algorithm inside the Pandora PFA framework.
PARSIFAL (PARametrized SImulation) is a software tool that can reproduce the complete response of both triple-GEM and micro-RWELL based trackers. It takes into account the involved physical processes by their simple parametrization and thus in a very fast way. Existing software as GARFIELD++ are robust and reliable, but very CPU time consuming. The implementation of PARSIFAL was driven by the necessity to reduce the processing time, without losing the precision of a full simulation. A series of parameters, that can be extracted from the GARFIELD++ simulation, are set as input to PARSIFAL, which then runs independently from GARFIELD++. PARSIFAL can simulate samples with high statistics much faster, taking into account the various steps (ionization, diffusion, multiplication, signal induction and electronics) from the simple sampling from parameterized distributions. In the case of the micro-RWELL MPGD, the effect of the high resistivity layer on the charge spread on the anode was introduced, following M.S. Dixit and A. Rankin treatment.
PARSIFAL was used to simulate triple-GEM chambers and the results were tuned to match experimental data from testbeams. In this case the adopted electronics was APV-25 readout by SRS system, which has been simulated in the code. The same procedure was later applied to micro-RWELL chambers, readout this time by the TIGER ASIC and the GEMROC system. This new electronics was added to PARSIFAL code and a tuning of the simulated-to-real data was performed. A presentation of the full code will be given in this contribution, setting the focus on the latest implementations and on a first comparison with experimental data from micro-RWELL.
AtlFast3 is the new, high-precision fast simulation in ATLAS that was deployed by the collaboration to replace AtlFastII, the fast simulation tool that was successfully used for most of Run2. AtlFast3 combines a parametrization-based Fast Calorimeter Simulation and a new machine-learning-based Fast Calorimeter Simulation based on Generative Adversarial Networks (GANs). The new fast simulation can reproduce the Geant4 inputs with higher accuracy than the old AtlFast2. In particular, the simulation of jets of particles reconstructed with large radii and the detailed description of their substructure are significantly improved in AtlFast3. Results will be presented on the performance of the new AtlFast3 that will be deployed for the simulation of the majority of events in Run3; these changes are crucial for achieving the precision needed by analyses that will need to rely mainly on fast simulation.
The Large Field Low-energy X-ray Polarization Detector (LPD) is a gas photoelectric effect polarization detector designed for the detailed study of X-ray temporary sources in high-energy astrophysics. Previous studies have shown that the polarization degree of gamma ray bursts (GRBs) is generally low or unpolarized. Considering the spatial background and other interferences, We need high modulation algorithms to observe low polarization GRB. For this purpose, moment analysis, graph theory, neural network algorithms are studied for the reconstruction of photoelectron emission angle. Combined with experimental and simulation data, the reconstruction performance of different algorithms at various energy and incident angles is evaluated.
Moment analysis algorithm finds out the large angle scattering point of photoelectron and remove the zone. Photoelectron track after cutting can be reconstructed. However, on the one hand, when track length is large, the performance of moment analysis algorithm becomes worse. On the other hand, for short cases, the track information loss caused by cutting is more serious, and the performance of moment analysis algorithm will also be degraded. In order to address these problems, graph theory algorithm and neural network are studied. Graph theory algorithm improves the reconstruction performance by precisely positioning the photoelectric action point through the trunk endpoint, which is more effective for longer tracks. Training samples of neural network algorithm are from the simulation platform built based on Geant4 in which photoelectric interaction, ionization diffusion, signal digitization and other processes on the detector are simulated as real as possible. Two typical neural networks, CNN and GNN, are studied. The results show that both neural networks predict high modulation and stability in designed energy range. In order to carefully evaluate the performance of the algorithm, the simulation should be as close to the real situation as possible.
Detailed detector simulation is the major consumer of CPU resources at LHCb, having used more than 80% of the total computing budget during Run 2 of the Large Hadron Collider at CERN. As data is collected by the upgraded LHCb detector during Run 3 of the LHC, larger requests for simulated data samples are necessary, and will far exceed the pledged resources of the experiment, even with existing fast simulation options. An evolution of technologies and techniques to produce simulated samples is mandatory to meet the upcoming needs of analysis to interpret signal versus background and measure efficiencies. In this context, we propose Lamarr, a Gaudi-based framework designed to offer to LHCb the fastest solution for simulations.
Lamarr consists of a pipeline of modules parametrizing both the detector response and the reconstruction algorithms of the LHCb experiment. Most of the parameterizations are made of Deep Generative Models and Gradient Boosted Decision Trees trained on simulated samples or alternatively, where possible, on real data. Embedding Lamarr in the general LHCb Gauss Simulation framework allows combining its execution with any of the available generators in a seamless way.
Lamarr has been validated by comparing key reconstructed quantities with Detailed Simulation. Good agreement of the simulated distributions is obtained with two-order-of-magnitude speed-up of the simulation phase.
Modern high energy physics experiments fundamentally rely on accurate simulation- both to characterise detectors and to connect observed signals to underlying theory. Traditional simulation tools are reliant upon Monte Carlo methods which, while powerful, consume significant computational resources. These computing pressures are projected to become a major bottleneck at the high luminosity stage of the LHC and for future colliders. Deep generative models hold promise to potentially offer significant reductions in compute times, while maintaining a high degree of physical fidelity.
This contribution provides an overview of a growing body of work focused on simulating showers in highly granular calorimeters, which is making significant strides towards realising fast simulation tools based on deep generative models. Progress on the simulation of both electromagnetic and hadronic showers, as well further steps to address challenges faced when broadening the scope of these simulators, will be reported. A particular focus will be placed on the high degree of physical fidelity achieved, as well as the performance after interfacing with reconstruction algorithms.
The Jiangmen Underground Neutrino Observatory (JUNO) is a multipurpose neutrino experiment and the determination of the neutrino mass hierarchy is its primary physics goal. JUNO is going to take data in 2024 with 2PB raw data each year and use distributed computing infrastructure for simulation, reconstruction and analysis tasks. The JUNO distributed computing system has been built up based on DIRAC since 2018. The official Monte Carlo production has started to run in the system and PBs of massive MC data has been shared among JUNO data centers through this system since last year. In this paper, an overview of the JUNO distributed computing system will be presented, including workload management system, data management system and calibration data access system. Also the progress of adapting the system to the token-based AAI and WebDAV TPC will be reported. The paper will also describe the preparations for the coming data-taking, and how we will arrange JUNO data processing activities in this platform for data-taking.
The discovery of gravitational waves, first observed in September 2015 following the merger of a binary black hole system, has already revolutionised our understanding of the Universe. This was further enhanced in August 2017, when the coalescence of a binary neutron star system was observed both with gravitational waves and a variety of electromagnetic counterparts; this joint observation marked the beginning of gravitational multi-messenger astronomy. The Einstein Telescope, a proposed next-generation ground-based gravitational-wave observatory, will dramatically increase the sensitivity to sources: the number of observations of gravitational waves is expected to increase from roughly 100 per year to roughly 100’000 per year, and signals may be visible for hours at a time, given the low frequency cutoff of the planned instrument. This increase in the number of observed events, and the duration with which they are observed, is hugely beneficial to the scientific goals of the community, but poses a number of significant computing challenges. Moreover, the currently used computing algorithms do not scale to this new environment, both in terms of the amount of resources required and the speed with which each signal must be characterised.
This contribution will discuss the Einstein Telescope's computing challenges, and the activities that are underway to prepare for them. Available computing resources and technologies will greatly evolve in the years ahead, and those working to develop the Einstein Telescope data analysis algorithms will need to take this into account. The availability of huge parallel HPC systems and ubiquitous Cloud computing will also be important to factor into the initial development of the experiment's computing model; the design of the model will also, for the first time, include the environmental impact as one of the optimisation metrics.
The LIGO, VIRGO and KAGRA Gravitational-wave (GW) observatories are getting ready for their fourth observational period, O4, scheduled to begin in March 2023, with improved sensitivities and thus higher event rates.
GW-related computing has both large commonalities with HEP computing, particularly in the domain of offline data processing and analysis, and important differences, for example in the fact that the amount of raw data doesn’t grow much with the instrument sensitivity, or the need to timely generate and distribute “event candidate alerts” to EM and neutrino observatories, thus making gravitational multi-messenger astronomy possible.
Data from the interferometers are exchanged between collaborations both for low-latency and offline processing; in recent years, the three collaborations designed and built a common distributed computing infrastructure to prepare for a growing computing demand, and to reduce the maintenance burden of legacy custom-made tools, by increasingly adopting tools and architectures originally developed in the context of HEP computing. So for example HTCondor is used for workflow management, Rucio for many data management needs, CVMFS for code and data distribution, and more.
We will present GW computing use cases and report about the architecture of the computing infrastructure as will be used during O4, as well as some planned upgrades for the subsequent observing run O5.
The HL-LHC run is anticipated to start at the end of this decade and will pose a significant challenge for the scale of the HEP software and computing infrastructure. The mission of the U.S. CMS Software & Computing Operations Program is to develop and operate the software and computing resources necessary to process CMS data expeditiously and to enable U.S. physicists to fully participate in the physics of CMS. We have developed a strategic plan to prioritize R&D efforts to reach this goal for the HL-LHC. This plan includes four grand challenges: modernizing physics software and improving algorithms, building infrastructure for exabyte-scale datasets, transforming the scientific data analysis process and transitioning from R&D to operations. We are involved in a variety of R&D projects that fall within these grand challenges. In this talk, we will introduce our four grand challenges and outline the R&D program of the U.S. CMS Software & Computing Operations Program.
The computing challenges at HL-LHC require fundamental changes to the distributed computing models that have served experiments well throughout LHC. ATLAS planning for HL-LHC computing started back in 2020 with a Conceptual Design Report outlining various challenges to explore. This was followed in 2022 by a roadmap defining concrete milestones and associated effort required. Today, ATLAS is proceeding further with a set of "demonstrators" with focussed R&D in specific topics described in the roadmap. The demonstrators cover areas such as optimised tape writing and access, data recreation on-demand and the use of commercial clouds. This paper presents an overview of the demonstrators, detailing the plans, timelines and expected impact of the work.
In this talk, we discuss the evolution of the computing model of the ATLAS experiment at the LHC. After LHC Run 1, it became obvious that the available computing resources at the WLCG were fully used. The processing queue could reach millions of jobs during peak loads, for example before major scientific conferences and during large scale data processing. The unprecedented performance of the LHC during Run 2 and subsequent large data volumes required more computing power than the WLCG consortium pledged. In addition to unpledged/opportunistic resources available through the grid, the integration of resources such as supercomputers and cloud computing with the ATLAS distributed computing model has led to significant changes in both the workload management system and the data management system, thereby changing the computing model as a whole. The implementation of the data carousel model and data on-demand, cloud and HPC integration, and other innovations expanded the physics capabilities of experiments in the field of high energy physics and made it possible to implement bursty data simulation and processing. In the past few years ATLAS, and many other High Energy (HEP) or Nuclear Physics (NP) and Astroparticle experiments, evaluated commercial clouds as an additional part of their computing resources. In this talk, we will briefly describe the ATLAS-Google and ATLAS-Amazon projects and how they were fully integrated with the ATLAS computing model. We will try to answer a fundamental question about the future computing model for experiments with large data volumes and distributed computing resources by considering three possible options:
- HEP/NP experiments will continue to own and use pledged resources
- HEP/NP experiments will buy resources from commercial providers
- HEP/NP experiments will own core resources and buy additional resources from commercial providers.
The Deep Underground Neutrino Experiment (DUNE) has historically represented data using a combination of custom data formats and those based on ROOT I/O. Recently, DUNE has begun using the Hierarchical Data Format (HDF5) for some of its data storage applications. HDF5 provides high-performance, low-overhead I/O in DUNE’s data acquisition (DAQ) environment. DUNE will use HDF5 to record raw data from the ProtoDUNE Horizontal Drift (HD), ProtoDUNE Vertical Drift (VD) and ICEBERG detectors, and the HD and VD coldbox test stands. Dedicated I/O modules have been developed to read the HDF5 data from these detectors into the offline framework for reconstruction directly and via XRootD. HDF5 is also very commonly used on High Performance Computers (HPCs) and is well-suited for use in AI/ML applications. The DUNE software stack contains modules that export data from an offline job in HDF5 format, so that they can be processed by external AI/ML software. The collaboration is also developing strategies to incorporate HDF5 in the detector simulation chains.
ROOT's TTree data structure has been highly successful and useful for HEP; nevertheless, alternative file formats now exist which may offer broader software tool support and more-stable in-memory interfacing. We present a data serialization library that produces a similar data structure within the HDF5 data format; supporting C++ standard collections, user-defined data types, and schema evolution of those types. This HDF5-based serialization shows improved performance compared to a similar ROOT-based serialization library when embedded into an event processing framework for a HEP experiment and opens the door to using other software that struggled to interface with the ROOT format.
The RNTuple I/O subsystem is ROOT's future event data file format and access API. It is driven by the expected data volume increase at upcoming HEP experiments, e.g. at the HL-LHC, and recent opportunities in the storage hardware and software landscape such as NVMe drives and distributed object stores. RNTuple is a redesign of the TTree binary format and API and has shown to deliver substantially faster data throughput and better data compression both compared to TTree and to industry standard formats. In order to let HENP computing workflows benefit from RNTuple's superior performance, however, the I/O stack needs to connect efficiently to the rest of the ecosystem, from grid storage to (distributed) analysis frameworks to (multithreaded) experiment frameworks for reconstruction and ntuple derivation. With the RNTuple binary format arriving at version 1.0, we present RNTuple's feature set, integration efforts, and its performance impact on the time-to-solution. We show the latest performance figures of RDataFrame analysis code of realistic complexity, comparing RNTuple and TTree as data sources. We discuss RNTuple's approach to functionality critical to the HENP I/O (such as multithreaded writes, fast data merging, schema evolution) and we provide an outlook on the road to its use in production.
After using ROOT TTree for over two decades and storing more than an exabyte of compressed data, advances in technology have motivated a complete redesign, RNTuple, that breaks backward-compatibility to take better advantage of these storage options. The RNTuple I/O subsystem has been designed to address performance bottlenecks and shortcomings of ROOT's current state of the art TTree I/O subsystem. Specifically, it comes with an updated, more compact binary data format, that can be stored both in ROOT files and natively in object stores, on performance engineering for modern storage hardware (e.g. high-throughput low-latency NVMe SSDs), and robust and easy to use interfaces.
RNTuple is scheduled to become production grade in 2024; recently it became mature enough to start exploring the integration into experiments' software. In particular, in this contribution we analyze the challenges and discuss their solutions on the way to supporting the ATLAS Analysis Event Data Model (based on xAOD data format) in Athena, part of the software stack for the ATLAS experiment.
Analysis performance has a significant impact on the productivity of physicists. The vast majority of analyses use ROOT (https://root.cern). For a few years now, ROOT has offered an analysis interface called RDataFrame which helps getting the best performance for analyses, ideally making them I/O limited, i.e. with their performance limited by the throughput of reading the input data.
The CERN IT department has recently noted (https://doi.org/10.5281/zenodo.6337728) that for the analysis activities (that they heuristically identified as such) there was no apparent performance CPU nor I/O bottleneck as seen from their point of view. We will report on our investigation in collaboration with USCMS and the CERN IT department to understand better where the inefficiencies that gave rise to this situation come from and the improvements that were made in ROOT to significantly reduce those inefficiencies. We will also describe additional logging and tagging facilities introduced to help distinguish the type of workload and help correlate the information gathered on the server side with the activities carried out by the users’ analysis.
RDataFrame is ROOT's high-level interface for Python and C++ data analysis. Since it first became available, RDataFrame adoption has grown steadily and it is now poised to be a major component of analysis software pipelines for LHC Run 3 and beyond. Thanks to its design inspired by declarative programming principles, RDataFrame enables the development of high-performance, highly parallel analyses without requiring expert knowledge of multi-threading and I/O: user logic is expressed in terms of self-contained, small computation kernels tied together via a high-level API. This design completely decouples analysis logic from its actual execution, and opens several interesting avenues for workflow optimization. In particular, in this work we explore the benefits of moving internal data processing from an event-by-event to a bulk-by-bulk loop: it dramatically reduces framework's performance overheads; in collaboration with the I/O layer it improves data access patterns; it exposes information that optimizing compilers might use to auto-vectorize the invocation of user-defined computations; finally, while existing user-facing interfaces remain unaffected, it becomes possible to additionally offer interfaces that explicitly expose bulks of events, useful e.g. for the injection of GPU kernels into the analysis workflow. Design challenges useful to inform future R&D will be presented, as well as an investigation of the relevant time-memory tradeoffs backed by novel performance benchmarks.
The Vera C. Rubin observatory is preparing for the execution of the most ambitious astronomical survey ever attempted, the Legacy Survey of Space and Time (LSST). Currently, in its final phase of construction in the Andes mountains in Chile and due to start operations in late 2024 for 10 years, its 8.4-meter telescope will nightly scan the southern sky and collect images of the entire visible sky every 4 nights using a 3.2 Gigapixel camera, the largest imaging device ever built for astronomy. Automated detection and classification of celestial objects will be performed by sophisticated algorithms on high-resolution images to progressively produce an astronomical catalog eventually composed of 20 billion galaxies and 17 billion stars and their associated physical properties.
In this contribution, we will briefly present the infrastructure deployed at the French Rubin data facility (operated by the IN2P3 computing center) to deploy the Rubin Science Platform, a set of web-based services to provide effective and convenient access to LSST data for scientific analysis.
We will describe the main services of the platform, the components that provide those services and our deployment model as well as some feedback collected by end users. We will also present the Kubernetes-based infrastructure we are experimenting with for hosting LSST astronomical catalog, a multi-petabyte relational database developed for the specific needs of the project.
The increasingly larger data volumes that the LHC experiments will accumulate in the coming years, especially in the High-Luminosity LHC era, call for a paradigm shift in the way experimental datasets are accessed and analyzed. The current model, based on data reduction on the Grid infrastructure, followed by interactive data analysis of manageable size samples on the physicists’ individual computers, will be superseded by the adoption of Analysis Facilities. This rapidly evolving concept is converging to include dedicated hardware infrastructures and computing services optimized for the effective analysis of large HEP data samples. This contribution will describe the actual implementation of this new analysis facility model at the CIEMAT institute, in Spain, to support the local CMS experiment community. Our presentation will report on the deployment of dedicated highly-performant hardware, the operation of data staging and caching services, that ensure prompt and efficient access to CMS physics analysis datasets, and the integration and optimization of a custom analysis framework, based on ROOT's RDataFrame and CMS NanoAOD format. Finally, performance results obtained by benchmarking the deployed infrastructure and software against a full CMS reference analysis workflow will be presented.
Prior to the start of the LHC Run 3, the US ATLAS Software and Computing operations program established three shared Tier 3 Analysis Facilities (AFs). The newest AF was established at the University of Chicago in the past year, joining the existing AFs at Brookhaven National Lab and SLAC National Accelerator Lab. In this paper, we will describe both the common and unique aspects of these three AFs, and the resulting distributed facility from the user’s perspective, including how we monitor and measure the AFs. The common elements include enabling easy access via Federated ID, file sharing via EOS, provisioning of similar Jupyter environments using common Jupyter kernels and containerization, and efforts to centralize documentation and user support channels. The unique components we will cover are driven in turn by the requirements, expertise and resources at each individual site. Finally, we will highlight how the US AFs are collaborating with other ATLAS and LHC wide (IRIS-HEP and HSF) user analysis support activities, evaluating tools like ServiceX and new file formats such as DAOD PHYSLITE.
Effective analysis computing requires rapid turnaround times in order to enable frequent iteration, adjustment, and exploration, leading to discovery. An informal goal of reducing 10TB of experimental data in about ten minutes using campus-scale computing infrastructure is an achievable goal, just considering raw hardware capability. However, compared to production computing, which seeks to maximize throughput at a massive scale over the timescale of weeks and months, analysis computing requires different optimizations in terms of startup latency, data locality, scalability limits, and long-tail behavior. At Notre Dame, we have developed substantial experience with running scalable analysis codes on campus infrastructure on a daily basis. Using the TopEFT application, based on the Coffea data analysis framework and the Work Queue distributed executor, we reliably process 2TB of data, 375 CPU-hours analysis codes to completion in about one hour on hundreds of nodes, albeit with a high variability due to competing system loads. The python environment needed in the compute nodes is setup and cached on the fly if needed (300MB as tarball sent to worker nodes, 1GB unpacked). In this talk, we present our analysis of the performance limits of the current system, taking into account software dependencies, data access, result generation, and fault tolerance. We present our plans for attacking the ten minute goal through a combination of hardware evolution, improved storage management, and application scheduling.
The INFN Cloud project was launched at the beginning of 2020, aiming to build a distributed Cloud infrastructure and provide advanced services for the INFN scientific communities. A Platform as a Service (PaaS) was created inside INFN Cloud that allows the experiments to develop and access resources as a Software as a Service (SaaS), and CYGNO is the beta-tester of this system. The aim of the CYGNO experiment is to realize a large gaseous Time Projection Chamber based on the optical readout of the photons produced in the avalanche multiplication of ionization electrons in a GEM stack. To this extent, CYGNO exploits the progress in commercial scientific Active Pixel Sensors based on Scientific CMOS for Dark Matter search and Solar Neutrino studies. CYGNO, like many other astroparticle experiments, requires a computing model to acquire, store, simulate and analyze data typically far from High Energy Physics (HEP) experiments. Indeed, astroparticle experiments are typically characterized by the fact to be less demanding from computing resources with respect to HEP one but have to deal with unique and unrepeatable data, sometimes collected in extreme conditions, with extensive use of templates and Montecarlo, and are often re-calibrated and reconstructed many times for a given data sets. Moreover, the varieties and the scale of computing models and requirements are extremely large. In this scenario, the Cloud infrastructure with standardized and optimized services offered to the scientific community could be a useful solution able to match the requirements of many small/medium size experiments. In this work, we will present the CYGNO computing model based on the INFN cloud infrastructure where the experiment software, easily extendible to similar experiments to similar applications on other similar experiments, provides tools as a service to store, archive, analyze, and simulate data.
The recent evolutions of the analysis frameworks and physics data formats of the LHC experiments provide the opportunity of using central analysis facilities with a strong focus on interactivity and short turnaround times, to complement the more common distributed analysis on the Grid. In order to plan for such facilities, it is essential to know in detail the performance of the combination of a given analysis framework, of a specific analysis and of the installed computing and storage resources. This contribution describes performance studies performed at CERN, using the EOS disk-based storage, either directly or through an XCache instance, from both batch resources and high-performance compute nodes which could be used to build an analysis facility. A variety of benchmarks, both synthetic and based on real-world physics analyses and their corresponding input datasets, are utilized. In particular, the RNTuple format from the ROOT project is put to the test and compared to the latest version of the TTree format, and the impact of caches is assessed. In addition, we assessed the difference in performance between the use of storage system specific protocols, like XRootd, and FUSE. The results of this study are intended to be a valuable input in the design of analysis facilities, at CERN and elsewhere.
Machine learning (ML) has become an integral component of high energy physics data analyses and is likely to continue to grow in prevalence. Physicists are incorporating ML into many aspects of analysis, from using boosted decision trees to classify particle jets to using unsupervised learning to search for physics beyond the Standard Model. Since ML methods have become so widespread in analysis and these analyses need to be scaled up for HL-LHC data, neatly integrating ML training and inference into scalable analysis workflows will improve the user experience of analysis in the HL-LHC era.
We present the integration of ML training and inference into the IRIS-HEP Analysis Grand Challenge (AGC) pipeline to provide an example of how this integration can look like in a realistic analysis environment. We also utilize Open Data to ensure the project’s reach to the broader community. Different approaches for performing ML inference at analysis facilities are investigated and compared, including performing inference through external servers. Since ML techniques are applied for many different types of tasks in physics analyses, we showcase options for ML integration that can be applied to various inference needs.
The ML_INFN initiative (“Machine Learning at INFN”) is an effort to foster Machine Learning activities at the Italian National Institute for Nuclear Physics (INFN).
In recent years, AI inspired activities have flourished bottom-up in many efforts in Physics, both at the experimental and theoretical level.
Many researchers have procured desktop-level devices, with consumer oriented GPUs, and have trained themselves in a variety of ways, from webinars, books, tutorials.
ML_INFN aims to help and systematize such effort, in multiple ways: by offering state-of-the art hardware for Machine Learning, leveraging on the INFN-Cloud provisioning solutions and thus sharing more efficiently GPU-like resources and leveling the access to such resources to all INFN researchers, and by organizing and curating Knowledge Bases with production grade examples from successful activities already in production.
Moreover, training events have been organized for beginners, based on existing INFN ML research and focussed on flattening the learning curve.
In this contribution we will update the status of the project reporting in particular on the development of tools to take advantage of High-Performance computing resources provisioned by CINECA for interactive and batch support to machine learning activities and on the organization of the first in-person advanced-level training event, with a GPU-equipped cloud-based envioronment provided to each participant.
Over the last few years, Cloud Sync&Share platforms have become go-to services for collaboration in scientific, academic and research environments, providing users with coherent and simple ways to access their data assets. Collaboration within those platforms, between local users on local applications, has been demonstrated in various settings, with visible improvements in the research production process. However, extending this paradigm beyond the borders of local and regional services has shown to be a challenge.
The EU-funded CS3MESH4EOSC Project aims to address that problem, by providing a bridge between local data and applications, and remote users, in what can be described as a "mesh" of interconnected services. The ScienceMesh, a pan-European federated network of interoperable services, is the main outcome of this Project.
We will present the architecture of the ScienceMesh and how it can be leveraged to extend local functionalities to remote users in other institutions, extending HEP beyond national frontiers and boosting cross-disciplinary research. We will then explain its technical foundations, from the APIs and protocols used in its design to the workflows which underlie its operations. We will also discuss the challenges faced during the implementation of the project, especially the integration with the two major open-source Sync&Share products on the market (ownCloud and Nextcloud). We will finish by explaining how we plan to extend the ScienceMesh to other areas and geographies.
Zenodo has over the past 10 years grown from a proof of concept to being the world's largest general-purpose research repository, cementing CERN’s image as a pioneer and leader in Open Science. We will review key challenges faced over the past 10 years and how we overcame them, from getting off the ground, over building trust to securing funding.
Growing Zenodo was an enriching and learning experience on how CERN technology can be put at the service of everyone across all research disciplines. We will show how Zenodo helped shape Open Science as we know it and became an essential component of the future European and global Open Science infrastructure.
After 10 successful years, we are getting ready for the next decade. Zenodo is going through a transformation that will make CERN technology even more reachable and useful to the world-wide research community. We will show a glimpse of what’s coming and look ahead to key challenges such as governance, data publishing ethics and how Zenodo can help continue to grow and support the adoption of open science practices, not only within physics but also across the globe’s research communities.
The "A Large Ion Collider Experiment" (ALICE), one of the four large experiments at the European Organization for Nuclear Research (CERN), is responsible for studying the physics of strongly interacting matter and the quark-gluon plasma.
In order to ensure the full success of ALICE operation and data taking during the Large Hadron Collider Runs 3 and 4, a list of tasks identified as Service Work is established and maintained, which concerns detector maintenance, operation, calibration, quality control, data processing and outreach, as well as coordination and managerial roles in ALICE.
The ALICE Glance Service Work system is a tool developed in a cooperation between the Federal University of Rio de Janeiro and the ALICE Collaboration that serves as the link between the user interaction and thousands of database entries. In this poster we describe the development process of this system and its functionalities that ranges from planning the entire year of work for hundred of tasks to individually assigning these tasks to members of the collaboration.
The system is divided into two distinct environments that communicates to generate a service. The first is a REST API written in modern PHP with its source code composed of bounded contexts following the Domain Driven Design paradigm, making the code very adaptable to different interfaces, be it a HTTP controller, in our case the Slim framework or a CLI command. The second is a responsive and clean web page made with the Vue.js framework, responsible to communicate with the user and to provide them with the means to make the requests to the API.
Our database versioning is managed by the PHP Doctrine library, making it easy to semi-automatic deploy our development changes to production.
In November 2022, the HEP Software Foundation (HSF) and the Institute for Research and Innovation for Software in High-Energy Physics (IRIS-HEP) organized a workshop on the topic of “Software Citation and Recognition in HEP”. The goal of the workshop was to bring together different types of stakeholders whose roles relate to software citation and the associated credit it provides, in order to engage the community in a discussion of: 1) the ways in which HEP experiments handle citation of software; 2) recognition for software efforts that enable physics results disseminated to the public; and 3) how the scholarly publishing ecosystem supports these activities. We heard from the publication board leadership of ATLAS, CMS, and LHCb in order to understand the current practice of these experiments; various open source community organizations (ROOT, Scikit-HEP, MCnet) discussed how they prefer their software to be cited; talks from publishers (Elsevier, JOSS) recognized the issue and showed an openness to following the wishes of the community; and discussions with tool providers (INSPIRE, Zenodo) covered new standards and tools for citation. The workshop made a number of tensions clear, for example between citations being used for credit and for reproducibility, and between supporting the immediate (and possibly contradictory) desires of software producers that lead to credit in today's culture and actions that might positively change the culture to better recognize the work of these developers. This talk will present highlights from the workshop as well as findings and recommendations documented in the workshop report.
Abstract
We present results on Deep Learning applied to Amplitude and Partial Wave Analysis (PWA) for spectroscopic analyses. Experiments in spectroscopy often aim to observe strongly-interacting, short-lived particles that decay to multi-particle final states. These particle decays have angular distributions that our deep learning model has been trained to identify. Working with TensorFlow and Keras libraries we have developed several neural network architectures that will be presented. One architecture that will be highlighted is our “Hybrid” Autoencoder (AE) architecture that has the best performance by far as it is able to resolve ambiguities. This AE is an unsupervised regressor that constrains the latent space variables to represent physically relevant quantities such as production amplitudes. As the training needs to be performed in a large amount of simulated data, a novel on-the-fly generation techniques is also used. Results of performed mass-independent and mass-dependent amplitude analyses using this technique will be presented.
One common issue in vastly different fields of research and industry is the ever-increasing need for more data storage. With experiments taking more complex data at higher rates, the data recorded is quickly outgrowing the storage capabilities. This issue is very prominent in LHC experiments such as ATLAS where in five years the resources needed are expected to be many times larger than the storage available (assuming a flat budget model and current technology trends) [1]. Since the data formats used are already highly compressed, storage constraints could require more drastic measures such as lossy compression, where some data accuracy is lost during the compression process.
In our work, following from a number of undergraduate projects [2,3,4,5,6,7], we have developed an interdisciplinary open-source tool for machine learning-based lossy compression. The tool utilizes an autoencoder neural network, which is trained to compress and decompress data based on correlations between the different variables in the dataset. The process is lossy, meaning that the original data values and distributions cannot be reconstructed precisely. However, for certain variables and observables where the precision loss is tolerable, the high compression ratio allows for more data to be stored yielding greater statistical power.
[1] - https://cerncourier.com/a/time-to-adapt-for-big-data/
[2] - http://lup.lub.lu.se/student-papers/record/9049610
[3] - http://lup.lub.lu.se/student-papers/record/9012882
[4] - http://lup.lub.lu.se/student-papers/record/9004751
[5] - http://lup.lub.lu.se/student-papers/record/9075881
[6] - https://zenodo.org/record/5482611#.Y3Yysy2l3Jz
[7] - https://zenodo.org/record/4012511#.Y3Yyny2l3Jz
The Super Tau Charm Facility (STCF) proposed in China is a new-generation electron–positron collider with center-of-mass energies covering 2-7 GeV. In STCF, the discrimination of high momentum hadrons is a challenging and critical task for various physics studies. In recent years, machine learning methods have gradually become one of the mainstream methods in the PID field of high energy physics experiments, with the advantage of big data processing.
In this work, targeting at the pion/kaon identification problem at STCF, we have developed a convolutional neural network (CNN) in the endcap PID system, which is a time-of-flight detector based on detection of internally reflected Cherenkov light (DTOF). By combining the hit position and arrival time of each Cherenkov photon at multi-anode microchannel plate photomultipliers, a two dimensional pixel map is constructed as the CNN input. The preliminary results show that the CNN model has a promising performance against the pion/kaon identification problem. In addition, based on the traditional CNN, a quantum convolution neural network (QCNN) is developed as well, as a proof-of-concept work exploring possible quantum advantages provided by quantum machine learning methods.
The main focus of the ALICE experiment, quark-gluon plasma measurements, requires
accurate particle identification (PID). The ALICE detectors allow identifying particles over a broad momentum interval ranging from about 100 MeV/c up to 20 GeV/c.
However, hand-crafted selections and the Bayesian method do not perform well in the
regions where the particle signals overlap. Moreover, an ML model can explore more
detector information. During LHC Run 2, preliminary studies with Random Forests obtained much higher efficiencies and purities for selected particles than standard techniques.
For Run 3, we investigate Domain Adaptation Neural Networks that account for the
discrepancies between the Monte Carlo simulations and the experimental data. Preliminary studies show that domain adaptation improves particle classification. Moreover, the solution is extended with Feature Set Embedding to give the network more flexibility to train on data with various sets of detector signals.
PID ML is already integrated with the ALICE Run 3 Analysis Framework. Preliminary results for the PID of selected particle species, including real-world analyzes, will be discussed as well as the possible optimizations.
Analyses in HEP experiments often rely on large MC simulated datasets. These datasets are usually produced with full-simulation approaches based on Geant4 or exploiting parametric “fast” simulations introducing approximations and reducing the computational cost. With our work we created a prototype version of a new “fast” simulation that we named “flashsim” targeting analysis level data tiers (such as CMS NanoAOD). Such a simulation software is based on Machine Learning, in particular exploiting the Normalizing Flows generative model. We will present the physics results achieved with this prototype, currently simulating only a few physics objects collections, in terms of: 1) accuracy of object properties, 2) correlations among paris of observables, 3) comparisons of analysis level derived quantities and discriminators between full-simulation and flash-simulation of the very same events. The speed up obtained with such an approach is of several orders of magnitude, so that when using flashsim the simulation bottleneck is represented by the “generator” (e.g. Pythia) step. We further investigated upsampling techniques, reusing the same “generated event” passing it multiple times through the detector simulation, in order to understand the increase in statistical precision that could be ultimately achieved. The results achieved with the current prototype show a higher physics accuracy and a lower computing cost compared to other fast simulation approaches such as CMS standard fastsim and Delphes based simulations.
AtlFast3 is the new ATLAS fast simulation that exploits a wide range of ML techniques to achieve high-precision fast simulation. The latest version of the AtlFast3 used in Run3 deploys FastCaloGANV2 which consists of 500 Generative Adversarial Networks used to simulate the showers of all particles in the ATLAS calorimeter system. The Muon Punch Through tool has also been completely rewritten using deep NN for the classification of events. An additional deep network is used to predict and correct the longitudinal position of the hits in the calorimeter layer based on the energy deposited by each shower in the calorimeter layers. These tools have been instrumental in improving the performance of AtlFast3.
CaTS is a Geant4 advanced example that is part of Geant4[1] since version 11.0. It demonstrates the use of Opticks[2] to offload the simulation of optical photons to GPUs. Opticks interfaces with the Geant4 toolkit to collect all the necessary information to generate and trace optical photons, re-implements the optical physics processes to be run on the GPU, and automatically translates the Geant4 geometry into a GPU appropriate format. To trace the photons Opticks
uses NVIDIA® OptiX7™ [3]. In this presentation we shall describe CaTS and the work performed to integrate Opticks with Geant4 using the tasking mechanism and the work to include CaTS in the software framework used by liquid Argon TPC neutrino experiments. We shall demonstrate that the generation and tracing of optical photons represents an ideal application to be offloaded to GPUs, fully utilizing the high degree of available parallelism. In a typical liquid Argon TPC simulation, a speedup of several hundred times compared to single threaded Geant4 is observed.
[1]https://geant4.web.cern.ch/
[2]https://doi.org/10.1051/epjconf/202125103009
[3]https://developer.nvidia.com/rtx/ray-tracing/optix
Keywords: Simulation of optical photons, GPUs.
Madgraph5_aMC@NLO is one of the workhorses for Monte Carlo event generation in the LHC experiments and an important consumer of compute resources. The software has been reengineered to maintain the overall look-and-feel of the user interface while achieving very large overall speedups. The computationally intensive part (the calculation of "matrix elements") is offloaded to new implementations optimized for GPUs and for vector CPUs, using event-level data parallelism. In this contribution, we will report on the first experience with the alpha release of the software supporting leading-order QCD processes. The achieved performance speedups and the potential for further improvements will be discussed in detail.
An important area of HEP studies at the LHC currently concerns the need for more extensive and precise comparison data. Important tools in this realm are event reweighting and the evaluation of more precise next-to-leading order (NLO) physics processes via Monte Carlo (MC) event generators, especially in the context of the upcoming High Luminosity LHC phase. Current event generators need to improve their throughput for these studies. MadGraph5_aMC@NLO (MGaMC) is an event generator being used heavily by LHC experiments which has been accelerated considerably with a GPU and vector CPU port, but as of yet only for leading order processes. In this contribution, a prototype for event reweighting using the accelerated MGaMC software package, as well as plans for the implementation of NLO calculations, will be presented.
The IceCube Neutrino Observatory is a cubic kilometer neutrino telescope
located at the Geographic South Pole. For every observed neutrino event,
there are over 10^6 background events caused by cosmic-ray air shower
muons. In order to properly separate signal from background, it is
necessary to produce Monte Carlo simulations of these air showers.
Although to-date, IceCube has produced large quantities of background
simulation, these studies remain statistics limited. The most
significant impediment to producing more simulation is complicated
computing requirements: the first stage of the simulation, air shower
and muon propagation, needs to be run on CPUs while the second stage,
photon propagation, can only be performed efficiently on GPUs.
Processing both of these stages on the same node will result in an
underutilized GPU but using different nodes will encounter bandwidth
bottlenecks. Furthermore, due to the power-law energy spectrum of cosmic
rays, the memory footprint of the detector response often exceeded the
limit in unpredictable ways. In this talk, I will present new
client/server code which parallelizes the first stage onto multiple CPUs
on the same node and then passes it on to the GPU for photon
propagation. This results in GPU utilization of greater than 90% as well
as more predictable memory usage and an overall factor of 20 improvement
in speed over previous techniques.
Celeritas is a new Monte Carlo detector simulation code designed for computationally intensive applications (specifically, HL-LHC simulation) on high-performance heterogeneous architectures. In the past two years Celeritas has advanced from prototyping a simple, GPU-based, single-physics-model infinite medium to implementing a full set of electromagnetic physics processes in complex geometries. The latest release of Celeritas has incorporated full VecGeom device-based navigation, an event loop in the presence of magnetic fields, and detector hit scoring. The new Acceleritas library provides a scheduler to offload electromagnetic physics to the GPU within a Geant4 driven simulation, enabling integration of Celeritas into HEP experimental frameworks such as CMSSW. Finally, we are collaborating with the AdePT team to design a suite of benchmarks to verify the correctness and evaluate the performance of GPU-enabled detector simulations. We present an overview of these new capabilities in Celeritas and show the performance results on both standalone and Geant4-integrated detector simulation benchmarks on both Nvidia and AMD GPU-based architectures.
Instead of focusing on the concrete challenges of incremental changes to HEP driven by AI/ML, it is perhaps a useful exercise to think through more radical, speculative changes. What might be enabled if we embraced a dramatically different approach? What would we lose? How would those changes impact the computational, organizational, and epistemological nature of the field?
Simulation is a critical component of high energy physics research, with a corresponding computing footprint. Generative AI has emerged as a promising complement to intensive full simulation with relatively high accuracy compared to existing classical fast simulation alternatives. Such algorithms are naturally suited to acceleration on coprocessors, potentially running fast enough to match the high data volumes at next-generation experiments. Numerous techniques are currently being explored, each with its own advantages and challenges. Looking beyond the next generation, foundational building blocks of AI such as automatic differentiation and gradient descent are now being incorporated into fully differentiable programming. This new paradigm will provide revolutionary tools for designing and optimizing future experiments.
A Dark Matter Science Project is being developed in the context of the ESCAPE project as a collaboration between scientists in European Research Infrastructures and experiments seeking to explain the nature of dark matter (such as HL-LHC, KM3NeT, CTA, DarkSide).
The goal of this ESCAPE Science Project is to highlight the synergies between different dark matter communities and experiments, by producing new scientific results as well as by making the necessary data and software tools fully available.
As part of this Science Project, we use experimental data and software algorithms from selected direct detection, indirect detection, and particle collider experiments involved in ESCAPE as prototypes for end-to-end analysis pipelines on a Virtual Research Environment that is being prepared as one of the building blocks of the European Open Science Cloud (EOSC).
This contribution focuses on the implementation of the workflows on the Virtual Research Environment using ESCAPE tools (such as the Data Lake and REANA), and on the prospects for data management, data analysis and computing in the EOSC-Future project.
The EU-funded ESCAPE project has brought together the ESFRI and other world class Research Infrastructures in High Energy and Nuclear Physics, Astro-Particle Physics, and Astronomy. In the 3 years of the project many synergistic and collaborative aspects have been highlighted and explored, from pure technical collaboration on common solutions for data management, AAI, and workflows, through development of new tools, such as AI/ML, and in education and training, for example in the area of Research Software. In addition, the project has shown that the communities have a lot in common, and can act as a single voice towards the funding agencies, the EC, and other key developments such as the European Open Science Cloud. ESCAPE is one of five such "cluster" projects, and the communities involved have found that the cluster concept is extremely useful in structuring the overall scientific community, and with many cross-domain commonalities are very important in acting together towards various political and funding bodies. Consequently we consider forming a long-term ESCAPE collaboration, that would exist independently of specific project funding, that can maintain the synergistic aspects of the ESCAPE scientific communities, while bringing new ones into the forum, and coordinate the interaction of those communities with the broader scientific and funding landscape. This talk will justify such a collaboration, outline some of its goals, and discuss the possible forms that it can take.
One of the objectives of the EOSC (European Open Science Cloud) Future Project is to integrate diverse analysis workflows from Cosmology, Astrophysics and High Energy Physics in a common framework. The project’s development relies on the implementation of the Virtual Research Environment (VRE), a prototype platform supporting the goals of Dark Matter and Extreme Universe Science Projects in the respect of FAIR data policies. It makes use of a common AAI system, and exposes the experiments’ data (ATLAS, Fermi-LAT, CTA, Darkside, Km3Net, Virgo, LOFAR) in a reliable distributed storage infrastructure for multi-science: the Data Lake. The entry point of such a platform is a jupyterhub instance deployed on top of a scalable Kubernetes infrastructure, providing an interactive graphical interface for researchers to access, analyse and share data. The data access and browsability is enabled through API calls to the high level data management and storage orchestration software (Rucio). In this contribution we will provide an overview of the VRE and present our recent work to improve its usability and functionality. The improvements include a software repository plug-in enabling researchers to directly select computational environments from Docker images and the integration of a re-analysis platform (Reana) supporting various distributed computing backends. The final goal of the VRE project, bringing together data and software access, workflow reproducibility and enhanced user interface, is to facilitate scientific collaboration, ultimately accelerating research in various fields.
The Energy Sciences Network (ESnet) is the high performance network of the US Department of Energy Office of Science. Over its 36-year span, ESnet has evolved to meet the requirements of ever changing scientific workflows. This presentation will provide a brief history of ESnet's generational changes and highlight the capabilities of its current generation network ESnet6. This presentation will also provide a glimpse into a future ESnet(7) and the requirements driving its design.
The large data volumes expected from the High Luminosity LHC (HL-LHC) present challenges to existing paradigms and facilities for end-user data analysis. Modern cyberinfrastructure tools provide a diverse set of services that can be composed into a system that provides physicists with powerful tools that give them straightforward access to large computing resources, with low barriers to entry. The coffea-casa analysis facility provides an environment for end users enabling the execution of increasingly complex analyses such as those demonstrated by the Analysis Grand Challenge (AGC) and capturing the features that physicists will need for the HL-LHC.
We describe the development progress of the coffea-casa facility featuring its modularity while demonstrating the ability to port and customize the facility software stack to other locations. The facility also facilitates the support of different backends to other batch systems while staying Kubernetes-native.
We present evolved architecture of the facility, such as the integration of advanced data delivery services (e.g. ServiceX) and making data caching services (e.g. XCache) available to end users of the facility.
We also highlight the composability of modern cyberinfrastructure tools. To enable machine learning pipelines at coffee-casa analysis facilities, a set of industry ML solutions adopted for HEP columnar analysis were integrated on top of existing facility services. These services also feature transparent access for user workflows to GPUs available at a facility via inference servers while using Kubernetes as enabling technology.
The Xrootd S3 Gateway is a universal high performance proxy service that can be used to access S3 portals using existing HEP credentials (e.g. JSON Web Tokens and x509). This eliminates one of the biggest roadblocks to using public cloud storage resources. This paper describes how the S3 Gateway leverages existing HEP software (e.g. Davix and XRootD) to provide a familiar scalable service that works with public (i.e. AWS, GCS, etc) and private (i.e. CEPH, MinIO, etc.) S3 portal available to the HEP community, and to seamlessly integrate them into the WLCG storage and data transfer ecosystem. The test was conducted at an ATLAS site and ATLAS installation in GCP and AWS.
There has been a significant increase in data volume from various large scientific projects, including the Large Hadron Collider (LHC) experiment. The High Energy Physics (HEP) community requires increased data volume on the network, as the community expects to produce almost thirty times annual data volume between 2018 and 2028 [1]. To mitigate the repetitive data access issue and network overloading, regional data caching mechanism [2], [3], or in-network cache has been deployed in Southern California for the US CMS, and its effectiveness has been studied [4], [5]. With the number of redundant data transfers over the wide-area network decreasing, the caching approach improves overall application performance as well as network traffic savings.
In this work, we examined the trends in data volume and data throughput performance from the Southern California Petabyte Scale Cache (SoCal Repo) [6], which includes 24 federated caching nodes with approximately 2.5PB of total storage. From the trends, we also determined how much a machine learning model can predict the network access patterns for the regional data cache. The fluctuation in the daily cache utilization, as shown in Figure 1, is high, and it is challenging to build a learning model to follow the trends.
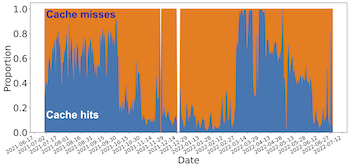
Figure 1: Daily proportion of cache hits volume and cache misses volume from July 2021 to June 2022, with 8.02 million data access records for 8.2PB of traffic volume for cache misses and 4.5PB of traffic volume for cache hits. 35.4% of the total traffic has been saved from the cache.
The daily and hourly study also modeled the cache utilization and data throughput performance, with 80% of the training data and 20% of the testing data. Figure 2 shows the samples of our hourly study results. The root-mean-square error (RMSE) is measured and compared to the standard deviation of the input data values to provide a reference to determine how large the errors of predictions are. The relative error, ratio of testing RMSE and standard deviation, is less than 0.5, indicating the predictions are pretty accurate.
Figure 2 (a): Hourly volume of cache misses; training set RMSE=0.16, testing set RMSE=0.40, std.dev=1.42
Figure 2 (b): Hourly throughput of cache misses; training set RMSE=25.90, testing set RMSE=18.93, std.dev=121.36
The study results can be used to optimize the cache utilization, network resources, and application workflow performance, and become the base for exploring characteristics of other data lakes as well as examining longer term network requirements for the data caches.
References
[1] B. Brown, E. Dart, G. Rai, L. Rotman, and J. Zurawski, “Nuclear physics network requirements review report,” Energy Sciences Network, University of California, Publication Management System Report LBNL- 2001281, 2020. [Online]. Available: https://www.es.net/assets/Uploads/ 20200505- NP.pdf
[2] X. Espinal, S. Jezequel, M. Schulz, A. Sciaba`, I. Vukotic, and F. Wuerthwein, “The quest to solve the hl-lhc data access puzzle,” EPJ Web of Conferences, vol. 245, p. 04027, 2020. [Online]. Available: https://doi.org/10.1051/epjconf/202024504027
[3] E. Fajardo, D. Weitzel, M. Rynge, M. Zvada, J. Hicks, M. Selmeci, B. Lin, P. Paschos, B. Bockelman, A. Hanushevsky, F. Wu ̈rthwein, and I. Sfiligoi, “Creating a content delivery network for general science on the internet backbone using XCaches,” EPJ Web of Conferences, vol. 245, p. 04041, 2020. [Online]. Available: https://doi.org/10.1051/epjconf/202024504041
[4] E. Copps, H. Zhang, A. Sim, K. Wu, I. Monga, C. Guok, F. Wurthwein, D. Davila, and E. Fajardo, “Analyzing scientific data sharing patterns with in-network data caching,” in 4th ACM International Workshop on System and Network Telemetry and Analysis (SNTA 2021), ACM. ACM, 2021.
[5] R. Han, A. Sim, K. Wu, I. Monga, C. Guok, F. Wurthwein, D. Davila, J. Balcas, and H. Newman, “Access trends of in-network cache for scientific data,” in 5th ACM International Workshop on System and Network Telemetry and Analysis (SNTA 2022), ACM. ACM, 2022.
[6] E. Fajardo, A. Tadel, M. Tadel, B. Steer, T. Martin, and F. Wu ̈rthwein, “A federated xrootd cache,” Journal of Physics: Conference Series, vol. 1085, p. 032025, 2018.
Current and future distributed HENP data analysis infrastructures rely increasingly on object stores in addition to regular remote file systems. Such file-less storage systems are popular as a means to escape the inherent scalability limits of the POSIX file system API. Cloud storage is already dominated by S3-like object stores, and HPC sites are starting to take advantage of object stores for the next generation of supercomputers. In light of this, ROOT's new I/O subsystem RNTuple has been engineered to support object stores alongside (distributed) file systems as first class citizens, while also addressing performance bottlenecks and interface shortcomings of its predecessor, TTree I/O.
In this contribution, we describe the improvements around RNTuple’s support for object stores, expounding on the challenges and insights toward efficient storage and high-throughput data transfers. Specifically, we introduce RNTuple’s native backend for the Amazon S3 cloud storage and present the latest developments in our Intel DAOS backend, demonstrating RNTuple’s integration with next-generation HPC sites.
Through experimental evaluations, we compare the two backends in single node and distributed end-to-end analyses using ROOT’s RDataFrame, proving Amazon S3 and Intel DAOS as viable HENP storage providers.
At Brookhaven National Lab, the dCache storage management system is used as a disk cache for large high-energy physics (HEP) datasets primarily from the ATLAS experiment[1]. Storage space on dCache is considerably smaller than the full ATLAS data collection. Therefore, a policy is needed to determine what data files to keep in the cache and what files to evict. A good policy is to keep frequently needed files in the future. In this work, we use the current and past file access information to predict the number of file accesses in the next day. The analysis tasks from the ATLAS experiment often access a predefined dataset as a group. Therefore, this study predicts how many times a dataset will be accessed in the future rather than each individual file.
HEP collaborations like ATLAS generate files in groups known as datasets and each of these groups (datasets) is produced by a task (such as an physical exepriement and a simulation) with a Task ID, or TID. The dCache system operators are considering policies specified in TIDs rather than individual files. For example, if a dataset (with a specific TID) is expected to be very popular in the next few days, it might make sense to ping all files of the dataset in disk.
To investigate how datasets tend to be accessed, we first performed K-means clustering on 9 months’ worth of dCache operational logs. Figure 1 shows the results of clustering the datasets according to their present and next day access counts. The cluster corresponding to datasets with less than 10^4 accesses is extremely large, whereas the clusters corresponding to higher numbers of accesses are small. This indicates that the majority of datasets are accessed relatively few times, and that there is also a small number of highly popular datasets. Pinging the small group of very popular datasets in dCache would achieve our goal of a popularity-based cache policy.
![]()
Figure 1: K-means clustering with k=4. A small number of datasets are accessed much more frequently than others and their access counts might be predictable.
The neural network was trained using a dataset containing information for 9 months’ worth of dCache transactions. We process the raw dCache logs into daily access statistics with the next day’s access count as the target variable for learning. The neural network was built using PyTorch; it uses 2 dense layers, the Tanh activation function, and the ADAM optimizer.
Figure 2: Predicted vs. actual access counts in the next day. The 100 most popular datasets sorted according to their actual access counts.
Figure 2 shows the predicted access values vs the actual access values for the 100 most popular datasets. The most popular dataset is accessed much more than the second most popular dataset, while the access counts of the next ten most popular datasets follow a power law with the exponent of -0.57, and an RMSE of 5.7 × 10^5. The access counts of many commonly accessed datasets follow the same power law show in Figure 2 for the majority of the top 100 popular datasets. This power law has an exponent of -0.47, and an RMSE of 2.0 × 10^6. This corroborates the pattern shown in Figure 1, where there is a small group of highly popular datasets, and their accesses are more predictable. Since the most popular few datasets are accessed much more frequently than others, pinging them in the disk cache could simplify the cache replacement decisions without sacrificing the overall disk cache effectiveness.
In summary, our results show that the popularity of the most popular datasets are predictable. It is therefore possible to ping these datasets in dCache, yielding a more effective cache policy. Future work will develop, simulate, and benchmark cache policies based off of the method presented here.
The PDF version of the extended abstract is available on https://sdm.lbl.gov/students/chep23/CHEP23_dCache_ext_abstract.pdf
In this talk, we present a novel data format design that obviates the need for data tiers by storing individual event data products in column objects. The objects are stored and retrieved through Ceph S3 technology, and a companion metadata system handles tracking of the object lifecycle. Performance benchmarks of data storage and retrieval will be presented, along with scaling tests of the data and metadata system.
Rucio is a software framework that provides scientific collaborations with the ability to organise, manage and access large volumes of data using customisable policies. The data can be spread across globally distributed locations and across heterogeneous data centres, uniting different storage and network technologies as a single federated entity. Rucio offers advanced features such as distributed data recovery or adaptive replication, and is highly scalable, modular, and extensible. Rucio has been originally developed to meet the requirements of the high-energy physics experiment ATLAS, and is being continuously extended to support LHC experiments and other diverse scientific communities. In recent years several R&D projects in these communities have started to evaluate the integration of both private and commercially-provided cloud storage systems. As they are using Rucio, new functionality has been developed to make the integration as seamless as possible. In addition the underlying systems, FTS and GFAL/Davix, have been extended for these use cases. In this contribution we detail the technical aspects of this work. In particular the challenges when building a generic interface to self-hosted cloud storage such as MinIO or CEPH S3 Gateway, to established providers such as Google Cloud Storage and Amazon Simple Storage Service, as well as upcoming decentralised clouds such as SEAL. We will highlight aspects such as authentication and authorisation, direct and remote access, throughput and cost estimation, and give experiences on daily operations.
The ATLAS jet trigger is instrumental in selecting events both for Standard Model measurements and Beyond the Standard Model physics searches. Non-standard triggering strategies, such as saving only a small fraction of trigger objects for each event, avoids bandwidth limitations and increases sensitivity to low-mass and low-momentum objects. These events are used by Trigger Level Analyses, which can reach regions of parameter space that would otherwise be inaccessible. To this end, the calibration of trigger-level jets is imperative both to ensure good trigger performance across the ATLAS physics programme and to provide well-measured jets for Trigger Level Analysis. This contribution presents an introduction to the ATLAS jet trigger for Run-3 of the LHC and discusses the performance of the trigger jet calibration. These studies will allow us to commission a Run-3 trigger jet calibration that provides excellent performance across a broad jet transverse momentum range as low as 25 GeV.
The LHCb experiment started taking data with an upgraded detector in the Run 3 of the LHC, reading at 30 MHz full detector data with a software-only trigger system. In this context, live data monitoring is crucial to ensure that the quality of the recorded data is optimal. Data from the experiment control system, as well as raw detector data and the output of the software trigger, is used as input to the monitoring system. Plots of important quantities are delivered to the so called data manager shifter, present permanently in the control room. In addition, the same system is used to evaluate the quality of the data for future physics analyses. The presentation will describe the tools involved in the online monitoring: the infrastructure, the data processing, the plot visualisation applications and the various reporting tools available for experts to diagnose and follow problems arising during data taking.
The CMS Online Monitoring System (OMS) aggregates and integrates different sources of information into a central place and allows users to view, compare and correlate information. It displays real-time and historical information.
The tool is heavily used by run coordinators, trigger experts and shift crews, to achieve optimal trigger and efficient data taking. It provides aggregated information for many use cases including data certification.
OMS is the successor of WBM, the Web Based Monitoring which was in use during Run 1 and Run 2 of the LHC.
WBM started as a small tool and grew substantially over the years so that maintenance became challenging. OMS was developed from scratch following several design ideas: to strictly separate the presentation layer from the data aggregation layer; to use a well-defined standard for the communication between presentation layer and aggregation layer; and to employ widely used frameworks from outside the HEP community.
A report on our experience of the operation of OMS for the first year of data taking of Run 3 in 2022 is presented.
Hydra is a system which utilizes computer vision to monitor data quality in near real time. Currently, it is deployed in all of Jefferson Lab’s experimental halls and lightens the load on shift takers by autonomously monitoring diagnostic plots in near real time. Hydra is constructed from “off-the-shelf” technologies and is backed up by a full MySQL database. To aid with both labeling and monitoring of Hydra’s inference, web apps have been developed, lowering the barrier to entry. Hydra connects with the EPICS alarm system and includes full history recording. This has enabled it to spot issues that were missed by shift takers. When issues are spotted a natural first question is “Why does Hydra think there is a problem?”. To answer this question Hydra uses gradCAM to highlight regions of an image which are most important in inference classification. This provides a level of interpretability/trustworthiness; essential for any operational system in science. This talk will describe the Hydra system, the technologies employed as well as in situ results. The sociological hurdles in deploying such a system will also be discussed.
ALICE (A Large Ion Collider Experiment) has undertaken a major upgrade during the Long Shutdown 2. The increase in the detector data rates, and in particular the continuous readout of the TPC, led to a hundredfold increase in the input raw data, up to 3.5 TB/s. To cope with it, a new common Online and Offline computing system, called O2, has been developed and put in production.
The online Data Quality Monitoring (DQM) and the offline Quality Assurance (QA) are critical aspects of the data acquisition and reconstruction software chains. The former intends to provide shifters with precise and complete information to quickly identify and overcome problems while the latter aims at selecting good quality data for physics analyses. Both DQM and QA typically involve the gathering of data, its distributed analysis by user-defined algorithms, the merging of the resulting objects and their visualization.
This paper discusses the final architecture and design of the QC, which runs synchronously to the data taking and asynchronously on the Worldwide LHC Computing Grid. Following the successful first year of data taking with beam, we will present our experience and the lessons we learned, before and after the LHC restart, when monitoring the data quality in a real-world and challenging environment. We will finally illustrate the wide range of usages people make of this system by presenting a few, carefully picked, use cases.
One critical step on the path from data taking to physics analysis is calibration. For many experiments this step is both time consuming and computationally expensive. The AI Experimental Calibration and Control project seeks to address these issues, starting first with the GlueX Central Drift Chamber (CDC). We demonstrate the ability of a Gaussian Process to estimate the gain correction factor (GCF) of the GlueX CDC accurately, and also the uncertainty of this estimate. Using the estimated GCF, the developed system infers a new high voltage (HV) setting that stabilizes the GCF in the face of changing environmental conditions. This happens in near real time during data taking and produces data which are already approximately gain-calibrated, eliminating the cost of performing those calibrations which vary by up to 30% with fixed HV. We also demonstrate an implementation of an uncertainty aware system which exploits a key feature of a Gaussian process.
The EPIC collaboration at the Electron-Ion Collider recently laid the groundwork for its software infrastructure. Large parts of the software ecosystem for EPIC mirror the setup from the Key4hep project, for example DD4hep for geometry description, and EDM4hep/PODIO for the data model. However, other parts of the EPIC software ecosystem diverge from Key4hep, for example for the event processing framework (JANA2 for EPIC versus Gaudi for Key4hep). The algorithms initiative by the EPIC collaboration tries to foster cross-community collaboration and algorithm-sharing by providing a framework- and experiment-independent approach to digitization and reconstruction algorithms. In this talk we will focus on the design choices behind Algorithms and showcase real-world integration of algorithms with both JANA2 and Gaudi.
The reconstruction of charged particles’ trajectories is one of the most complex and CPU-consuming event processing chains in high energy physics (HEP) experiments. Meanwhile, the precision of track reconstruction has direct and significant impact on vertex reconstruction, physics flavour tagging and particle identfication, and eventually on physics precision, in particular for HEP experiments at the precison frontier, such as the Super τ-Charm facility (STCF).
With an electron-positron collider operating at center-of-mass-energy 2∼7 GeV and a peak luminosity above 0.5 × 10^35 cm^−2 s^−1, the STCF physics program will provide an unique platform for in-depth studies of hadron structure and non-perturbative strong interaction, as well as probing physics beyond the Standard Model at the τ-Charm sector suceeding the present Being Electron-Positron Collider II (BEPCII). To fulfill the physics targets and to further maximize the physics potential at the STCF, the charged particles with momentum down to 50 MeV must be detected and reconstructed, and an excellent momentum and angular resolution of the charged particles must be achieved. Therefore, development of a highly-performant and maintenable tracking software is very curcial for the design, construction and operation of STCF.
Based on the tracking experience at LHC, the project, A Common Tracking Software (ACTS), aims to provide an open-source experiment-independent and framework-independent software designed for modern computing architectures. It provides a set of high-level performant track reconstruction tools which are agnostic to the details of the detection technologies and magnetic field configuration, and tested for strict thread-safety to support multi-threaded event processing. ACTS has been used as a tracking toolkit at experiments such as ATLAS, sPHENIX, ALICE etc. and has shown very promising tracking performance in terms of both physics performance and time performance. However, its applications so far are mainly focusing on silicon-based tracking systems and are often less concerned with charged tracks with momentum below a few hundreds of MeV.
In this talk, I will report on development of the STCF track reconstrcon software based on the detection information from a Silicon (or uRWELL)-based Inner Tracker and a Main Drift Chamber using the Kalman Filter based track finding and fitting algorithms of ACTS. This is the first application of ACTS for a drift chamber and shows very promising performance. Therefore, the efforts on tuning its performance, in particular for charged tracks with low momentum down to 50 MeV, will be highlighted.
ACTS is an experiment independent toolkit for track reconstruction, which is designed from the ground up for thread-safety and high performance. It is built to accommodate different experiment deployment scenarios, and also serves as community platform for research and development of new approaches and algorithms.
The Event Data Model (EDM) is a critical piece of the tracking library that is visible to clients. Until this point, ACTS was mostly focused on an internal EDM, targeting data interchange betweens various components in the toolkit.
This contribution reports on a new and improved client EDM for ACTS. For an experiment-agnostic toolkit like ACTS, this requires strong abstractions of potentially experiment-specific details, including event context data like sensor alignments, and tracking inputs like measurements. By applying similar abstraction strategies, the presented EDM can be an expressive, low-overhead abstraction over experiment-specific backends, and seamlessly integrates into an experiment framework and IO model.
The presented EDM includes the ACTS track class, the main data type which tracking clients interact with. It is designed to be interfaced with different IO backends, and also flexible enough to support dynamic information required by various track fitters. At the same time, careful design ensures it can seamlessly serve as a key data object in experiment reconstruction data flows.
In this contribution, the interaction of this centerpiece of the example workflows in ACTS with the standalone ROOT IO, as well as the integration with the EDM4hep package will be shown, and key performance characteristics discussed.
For Run 3, ATLAS redesigned its offline software, Athena, so that the
main workflows run completely multithreaded. The resulting substantial
reduction in the overall memory requirements allows for better use
of machines with many cores. This talk will discuss the performance
achieved by the multithreaded reconstruction as well as the process
of migrating the large ATLAS code base and tools and techniques
that were useful in debugging threading-related problems.
During the long shutdown between LHC Run 2 and 3, a reprocessing of 2017 and 2018 CMS data with higher granularity data quality monitoring (DQM) harvesting was done. The time granularity of DQM histograms in this dataset is increased by 3 orders of magnitude. In anticipation of deploying this higher granularity DQM harvesting in the ongoing Run 3 data taking, this dataset is used to study the application of Machine Learning (ML) techniques to data certification with the goal of developing tools for online monitoring and offline certification. In this talk, we will discuss the challenges and present some of the results, illustrating the tools developed for CMS Tracker Data Quality Monitoring and Certification. Studies consider both the use case of anomaly detection in the context of reprocessing campaigns, when all the data is available, and in the context of continuous data taking, when conditions are constantly changing and models need to be trained on data previously collected with similar conditions. Data augmentation is pursued, including information from the CMS Online Monitoring System (luminosity, pile-up, LHC fill, run and trigger), from the CMS Run Registry (sub-detector certification flags), from the CMS conditions database (calibrations). The status of the web application integrating data sources and facilitating development, testing and benchmarking of ML models will be presented using a few test cases.
We present a collection of tools and processes that facilitate onboarding a new science collaboration onto the OSG Fabric of Services. Such collaborations typically rely on computational workflows for simulations and analysis that are ideal for executing on OSG's distributed High Throughput Computing environment (dHTC). The produced output can be accumulated and aggregated at available ephemeral storage for inspection and then distribution to other facilities for long-term storage and further analysis. This work focuses on matching workflow requirements to tools and services that provide job management, automation (Pegasus WMS), and delivery of collaboration-specific software and input data to Execution Points (EP) using the Open Science Data Federation (OSDF) or Rucio. We describe best-supported practices to transfer data products to remote facilities at runtime or after the job completion. We emphasize the importance of early planning that meets the goals of the typically long life cycle of HEP experiments and advocate for an engagement model where the collaboration eventually becomes self-reliant in workload and data management.
There is no lack of approaches for managing the deployment of distributed services – in the last 15 years of running distributed infrastructure, the OSG Consortium has seen many of them. One persistent problem has been each physical site has its style of configuration management and service operations, leading to a partitioning of the staff knowledge and inflexibility in migrating services between sites.
Recently, the team has been migrating the OSG Fabric of Services to be deployed via Kubernetes which provides a common service orchestration fabric across all sites. However, this leaves open a question - how does the team interact with Kubernetes? To coordinate this new style of deployment among geographically distributed clusters and team members, the team has adopted "GitOps", an operational model that uses Git version control repositories to drive service updates. Git-driven operations provides all the benefits of version control such as recording the who, what, when, and why of any given change. But, more powerfully, automated agents synchronize the current state of the Git repository with the current state of the Kubernetes clusters, streamlining the ability to redeploy services from scratch or transfer services between clusters. In this paper, we will describe the setup that enables GitOps deployments of central OSG services and the lessons learned along the way, including rebuilding a suite of services after a critical failure and our experiences with providing high-availability services across multiple Kubernetes clusters.
The CernVM File System (CVMFS) provides the software distribution backbone for High Energy and Nuclear Physics experiments and many other scientific communities in the form of a globally available shared software area. It has been designed for the software distribution problem of experiment software for LHC Runs 1 and 2. For LHC Run 3 and even more so for HL-LHC (Runs 4-6), the complexity of the experiment software stacks and their build pipelines is substantially larger. For instance, software is being distributed for several CPU architectures, often in the form of containers which includes base and operating system libraries, the number of external packages such as machine learning libraries has multiplied, and there is a shift from C++ to more Python-heavy software stacks that results in more and smaller files needing to be distributed. For CVMFS, the new software landscape means an order of magnitude increase of scale in key metrics such as number of files, number of system calls, and number of concurrent processes accessing the file system client. In this contribution, we report on the performance and reliability engineering on the file system client to sustain current and expected future software access load. Concretely, we show the impact of the newly designed file system cache management, including upstreamed improvements to the fuse kernel module itself, improved utilization of network links and caches (such as line optimization, prefetching, and proxy sharding), and operational improvements on network failure handling, error reporting, and integration with container runtimes. Overall, the new CVMFS client is designed to sustain applications with more than one million file lookups during startup, nodes with hundreds of cores, and thousands of concurrent processes accessing software from the file system client.
The increasing computational demand in High Energy Physics (HEP) as well as increasing concerns about energy efficiency in high performance/throughput computing are driving forces in the search for more efficient ways to utilize available resources. Since avoiding idle resources is key in achieving high efficiency, an appropriate measure is sharing of idle resources of under-utilized sites with fully occupied sites. The software COBalD/TARDIS can automatically, transparently and dynamically (dis)integrate such resources in an opportunistic manner.
Sharing resources however also requires accounting. In this work we introduce AUDITOR (AccoUnting DatahandlIng Toolbox for Opportunistic Resources), a flexible and extensible accounting system that is able to cover a wide range of use cases and infrastructure. AUDITOR gathers accounting data via so-called collectors which are designed to monitor batch systems, COBalD/TARDIS, cloud schedulers or other sources of information. The data is stored in a database and provided to so-called plugins, which take an action based on accounting records. An action could for instance be creating a bill or computing the CO2 footprint, adjusting parameters of a service (for instance priorities in a batch system) or forwarding accounting information to other accounting systems. Depending on the use case, a suitable collector and plugin are selected from a growing ecosystem of collectors and plugins. Libraries for interacting with AUDITOR are provided to facilitate the development of collectors and plugins by the community.
This contribution gives insights into the design of AUDITOR and how it integrates into a number of different use cases.
The JIRIAF project aims to combine geographically diverse computing facilities into an integrated science infrastructure. This project starts by dynamically evaluating temporarily unallocated or idled compute resources from multiple providers. These resources are integrated to handle additional workloads without affecting local running jobs. This paper describes our approach to launch best-effort batch tasks which exploit these underutilized resources. Our system measures the real-time behavior of jobs running on a machine and learns to distinguish typical performance from outliers. Unsupervised ML techniques are used to analyze hardware-level performance measures, followed by a real-time cross-correlation analysis to determine which applications cause performance degradation. We then ameliorate bad behavior by throttling these processes. We demonstrate that problematic performance interference can be detected and acted on, which makes it possible to continue to share resources between applications and simultaneously maintain high utilization levels in a computing cluster. For a case study, we relocate the CLAS12 data processing workflow to a remote data center, preventing file migration and temporal data persistency.
The Worldwide LHC Computing Grid (WLCG) is a large-scale collaboration which gathers the computing resources of around 170 computing centres from more than 40 countries. The grid paradigm, unique to the realm of high energy physics, has successfully supported a broad variety of scientific achievements. To fulfil the requirements of new applications and to improve the long-term sustainability of the grid middleware, more versatile solutions are being investigated. Cloud computing is becoming increasingly popular among open-source and commercial players. The HEP community has also recognized the benefits of integrating cloud technologies into the legacy grid-based workflows. Since March 2021, INFN has entered the field of cloud computing establishing the INFN Cloud infrastructure. Large data centers of the INFN National Computing Center, connected to a nation-wide backbone maintained by the GARR Consortium, are gathered into a redundant and federated infrastructure. This cloud service supports scientific computing, software development and training, and serves as an extension of local computing and storage resources. Among available services, INFN Cloud administrators can create virtual machines, Docker-based deployments or Kubernetes clusters. These options allow the creation of customized environments, both for individual users and for scientific collaborations. This study investigates the feasibility of an automated, cloud-based data analysis workflow for the ATLAS experiment using INFN Cloud resources. The concept is designed as a Platform-as-a-Service (PaaS) solution, based on a Centos 7 Docker image. The customized image is responsible for the provisioning of CERN’s CVMFS and EOS shared filesystems, from which a standardized ATLAS environment can be loaded. The end user’s only responsibility is to provide a working application capable of retrieving and analysing data, and to export the results to a persistent storage. The analysis code can be sourced either from remote git repositories or from a local Docker bind mount. As a final step in the automation workflow, a Kubernetes cluster will be configured within the INFN Cloud infrastructure to allow dynamic resource allocation and the interoperability with batch systems, such as HTCondor, will be investigated.
CERN hosts more than 1200 websites essential for the mission of the Organization, internal and external collaboration and communicaiton as well as public outreach. The complexity and scale of CERN’s online presence is very diverse with some websites, like https://home.cern/
, accommodating more than one million unique visitors in a day.
However, regardless of their diversity, all websites are created using the Drupal content management system (CMS), and are self-hosted directly in the CERN Datacenter on a dedicated infrastructure that runs on Kubernetes
. Workflows like provisioning, deleting, cloning, upgrading, and similar are fully automated and managed by a customised Kubernetes controller. By leveraging the custom controller, the infrastrucutre has proven highly reliant with minimal, manual intervention necessary. In order to further automate deployments and improve goverance, we run a customised version of Drupal called the CERN Drupal Distribution. Supported by end-to-end integration tests and automated browser simulation, our setup enables us to propagate security and feature updates seamlessly to all websites without any downtime.
In this paper, we outline the architecture allowing us to build, test, and distribute updates to a large number of websites without any downtime. We further share our experiences and learnings from managing such a service at CERN with a lean team.
The Jiangmen Underground Neutrino Observatory (JUNO), under construction in South China, primarily aims to determine the neutrino mass hierarchy and the precise measure oscillation parameters. The data-taking is expected to start in 2024 and plans to run for more than 20 years. The development of JUNO offline software (JUNOSW) started in 2012, and it is quite challenging to maintain the JUNOSW for such a long time. In the last ten years, tools such as Subversion, Trac, and CMT had been adopted for software development. However, there are some new requirements, such as how to reduce the building time for the whole project, how to deploy offline algorithms to an online environment, and how to improve the code quality with code review and continuous integration. To meet the further requirements of software development, modern development tools are evaluated for JUNOSW, such as Git, GitLab, CMake, Docker, and Kubernetes. This contribution will present the software development system based on these modern tools for JUNOSW and the functionalities we have achieved: CMake macros are developed to simplify the build instructions for users; CMake generator expressions are used to control the build flags for the online and offline environments; a tool named git-junoenv is developed to help users partially checkout and build the software; a script is used to build and deploy the software on the CVMFS server; a Docker image with CVMFS client installed is created for continuous integration; a GitLab agent is set up to manage GitLab runners in Kubernetes with all the configurations in a GitLab repository. In late 2022, the migration had been done.
The ATLAS Continuous Integration (CI) System is the major component of the ATLAS software development infrastructure, synchronizing efforts of several hundred software developers working around the world and around the clock. Powered by 700 fast processors, it is based on the ATLAS GitLab code management service and Jenkins CI server and performs daily up to 100 ATLAS software builds probing the code changes proposed in merge requests. The system uses Operational Intelligence methods to shorten development cycles and lower operating costs. The paper describes these methods, such as removal of redundant operations, compilation and testing parallelization, usage of the directed acyclic graph (DAG) approach in CI pipelines as well as reports achieved improvements.
The ALICE experiment at CERN uses a cluster consisting of virtual and bare-metal machines to build and test proposed changes to the ALICE Online-Offline (O2) software in addition to building and publishing regular software releases.
Nomad is a free and open-source job scheduler for containerised and non-containerised applications developed by Hashicorp. It is integrated into an ecosystem of related software, including Consul and Vault, providing a consistent interface to orchestration, monitoring and secret storage. At ALICE, it recently replaced Apache Mesos, Aurora and Marathon as the primary tool for managing our computing resources.
First, we will describe the architecture of the build cluster at the ALICE experiment. After giving an overview of the advantages that Nomad gives us in managing our computing workload, and our reasons for switching away from the Mesos software stack, we will present concrete examples of improvements in monitoring and automatic configuration of web services that we are already benefiting from. Finally, we will discuss where we see opportunities for future work in integrating the ALICE build infrastructure more deeply with Nomad, in order to take advantage of its larger feature set compared to Mesos.
GitLab has been running at CERN since 2012. It is a self-service code hosting application based on Git that provides collaboration and code review features, becoming one of the key infrastructures at CERN. It is being widely used at CERN, with more than 17 000 active users, hosting more than 120 000 projects and triggering more than 5 000 jobs per hour.
On its initial stage, a custom-made solution has been deployed that, aligned with the exponential increase of projects, workflows and continuous integrations, made the GitLab infrastructure hard and complex to scale and to maintain.
The recent migration performed, adopting a new supported Cloud Hybrid infrastructure, has contributed CERN to line up the GitLab infrastructure with both industry standards and best practices, to make the new infrastructure much more robust and performant, obtaining notable benefits in the whole deployment process.
This paper will address how this deployment process, on the road to success, has presented a series of challenges and pitfalls that have been faced during this complex migration process.
The usage of Deep Neural Networks (DNNs) as multi-classifiers is widespread in modern HEP analyses. In standard categorisation methods, the high-dimensional output of the DNN is often reduced to a one-dimensional distribution by exclusively passing the information about the highest class score to the statistical inference method. Correlations to other classes are hereby omitted.
Moreover, in common statistical inference tools, the classification values need to be binned, which relies on the researcher's expertise and is often non-trivial. To overcome the challenge of binning multiple dimensions and preserving the correlations of the event-related classification information, we perform K-means clustering on the high-dimensional DNN output to create bins without marginalising any axes.
We evaluate our method in the context of a simulated cross section measurement at the CMS experiment, showing an increased expected sensitivity over the standard binning approach.
The search for the dimuon decay of the Standard Model (SM) Higgs boson looks for a tiny peak on top of a smoothly falling SM background in the dimuon invariant mass spectrum 𝑚(𝜇𝜇). Due to the very small signal-to-background ratio, which is at the level of 0.2% in the region 𝑚(𝜇𝜇) = 120–130 GeV for an inclusive selection, an accurate determination of the background is of paramount importance. The 𝑚(𝜇𝜇) background spectrum is parameterised by analytic functions that can describe this distribution at the per-mill level to avoid a significant bias in the extracted signal yields. The criteria used to select the background functions are based on the spurious signal, which measures the residual signal events obtained from signal-plus-background fits to background-only MC templates. Therefore, these MC templates have to be derived from events with very high statistics in order to reduce possible fluctuations. Computationally, it is extremely expensive, if not impossible, to generate the Drell-Yan 𝑍/𝛾∗ → 𝜇𝜇 background events with detailed simulation. Our study focuses on the use of generative models, trained on the existing fully simulated events of the ATLAS experiment in order to generate billions of events using GPUs for the spurious signal study, and to test the statistical independence of these events. This study presents an interesting alternative procedure in for the generation of events with high statistical power that could be used in the future by default in many analyses at the LHC.
We present New Physics Learning Machine (NPLM), a machine learning-based strategy to detect data departures from a Reference model, with no prior bias on the source of discrepancy. The main idea behind the method is to approximate the optimal log-likelihood-ratio hypothesis test parametrising the data distribution with a universal approximating function, and solving its maximum-likelihood fit as a machine learning problem with a customised loss function [1]. The method returns a $p$-value that measures the compatibility of the data with the Reference model. The most interesting potential applications are model-independent New Physics searches, validation of new Monte Carlo event generators and data quality monitoring. Using efficient large-scale implementations of kernel methods as universal approximators [2], the NPLM algorithm can be deployed on a GPU-based data acquisition system and be exploited to explore online the readout of an experimental setup. This would allow to spot out detectors malfunctioning or, possibly, unexpected anomalous patters in the data. One crucial advantage of the NPLM algorithm over standard goodness-of-fit tests routinely used in many experiments is its capability of inspecting multiple variables at once, taking care of correlations in the process. It also identifies the most discrepant region of the phase-space and it reconstructs the multidimensional data distribution, allowing for further inspection and interpretation of the results.
Finally, a way for dealing with systematic uncertainties affecting the knowledge of the Reference model has been developed in a neural network framework [3] and is under construction for kernel methods.
Data-driven methods are widely used to overcome shortcomings of Monte Carlo (MC) simulations (lack of statistics, mismodeling of processes, etc.) in experimental High Energy Physics. A precise description of background processes is crucial to reach the optimal sensitivity for a measurement. However, the selection of the control region used to describe the background process in a region of interest biases the distribution of some physics observables, rendering the use of such observables impossible in a physics analysis. Rather than discarding these events and/or observables, we propose a novel method to generate physics objects compatible with the region of interest and properly describing the correlations with the rest of the event properties. We use generative adversarial networks (GAN) for this task, as GAN are among the best performing generator models for various machine learning applications. The method is illustrated by generating a new misidentified photon for the $\mathrm{\gamma+Jets}$ background of the $\mathrm{H\rightarrow\gamma\gamma}$ analysis at the CERN LHC, thanks to CMS Open Data simulated samples. We demonstrate that the GAN is able to generate a coherent object within the region of interest and still correlated with the different properties of the rest of the event.
Many theories of Beyond Standard Model (BSM) physics feature multiple BSM particles. Generally, these theories live in higher dimensional phase spaces that are spanned by multiple independent BSM parameters such as BSM particle masses, widths, and coupling constants. Fully probing these phase spaces to extract comprehensive exclusion regions in the high dimensional space is challenging. Constraints on person-power and computational resources can limit analyses to focus only on one- or two-dimensional regions of the relevant parameter spaces. Nonetheless, fully comprehensive exclusion regions, even for complex theory phase spaces, are generally desirable to maximize the utility of such BSM searches.
We are presenting an advanced analysis workflow composed of an integrated pipeline and active learning that enables such a comprehensive exclusion. The integrated pipeline automatically executes all steps of an analysis from event generation through to limit setting. Active learning is a technique to guide the sampling of the multi-dimensional phase space to find the exclusion contours in an iterative process: the sampled theory phase space points are selected such that the vicinity of the exclusion region is prioritized, reducing the sampling density in the less interesting areas. As a result, it allows searches over a larger space at the same precision, or reduces the resources required for the same search-space. We will present the implementation of the workflow with the Production and Distributed Analysis system (PanDA system) and intelligent Data Delivery Service (iDDS) in ATLAS, and showcase its abilities and utility in an extended search for a dark Z-boson using events with four-lepton final states.
The matrix element method (MEM) is a powerful technique that can be used for the analysis of particle collider data utilizing an ab initio calculation of the approximate probability density function for a collision event to be due to a physics process of interest. The most serious difficulty with the ME method, which has limited its applicability to searches for beyond-the-SM physics and precision measurements at colliders, is that it is computationally expensive. Complex final states can take minutes per event or more to calculate the probability densities. ML methods can be used to speed up the numerical evaluation dramatically. In this work, we explore Deep Learning based solutions to approximate MEM calculations and compare their performance with respect to existing computational benchmarks.
Computational science, data management and analysis have been key factors in the success of Brookhaven National Laboratory's scientific programs at the Relativistic Heavy Ion Collider (RHIC), the National Synchrotron Light Source (NSLS-II), the Center for Functional Nanomaterials (CFN), and in biological, atmospheric, and energy systems science, Lattice Quantum Chromodynamics (LQCD) and Materials Science, as well as our participation in international research collaborations, such as the ATLAS Experiment at Europe's Large Hadron Collider (LHC) at CERN (Switzerland) and the Belle II Experiment at KEK (Japan). The construction of a new data center is an acknowledgement of the increasing demand for computing and storage services at BNL in the near term and enable the Lab to address the needs of the future experiments at the High-Luminosity LHC at CERN and the Electron-Ion Collider (EIC) at BNL in the long term. The Computing Facility Revitalization (CFR) project is aimed at repurposing the former National Synchrotron Light Source (NSLS-I) building as the new data center for BNL. The construction of the new data center was finished in 2021Q3, and it was delivered for production in early FY2022 for all collaborations supported by the Scientific Data and Computing Center (SDCC), including: STAR, PHENIX and sPHENIX experiments at RHIC collider at BNL, the Belle II Experiment at KEK (Japan), and the Computational Science Initiative at BNL (CSI). The extension of the central network systems into the new data center and the migration of a significant portion of IT load and services from the existing data center to the new data center has been underway for the duration of the first year of operations. The deployment of four new IBM TS4500 tape libraries was carried out in FY2022 as well for BNL ATLAS Tier-1 Site and sPHENIX experiment at RHIC for which the first period of data taking is expected to be carried out later in FY2023. This presentation will highlight the key mechanical, electrical, and networking components of the new data center in its final configuration as used in production since 2021Q4. Also, we will overview the IT payload deployment operations performed so far in the new data and describe plans to complete the gradual IT equipment replacement and migration from the old data center into the new one to be completed by the end of FY2023 (Sep 30, 2023). We will also show the expected state of occupancy and infrastructure utilization for the new data center up to FY2027 and further upgrade steps for its infrastructure needed in that period.
Moving towards Net-Zero requires robust information to enable good decision making at all levels: covering hardware procurement, workload management and operations, as well as higher level aspects encompassing grant funding processes and policy framework development.
The IRISCAST project is a proof-of-concept study funded as part of the UKRI Net-Zero Scoping Project. We have performed an audit of carbon costs across a multi-site heterogenous infrastructure by collecting and analysing snapshots of actual usage across different facilities within the IRIS community (https://iris.ac.uk). This combines usage information with an analysis of the embodied costs and careful mapping and consideration of the underlying assumptions to produce an estimate of the overall carbon cost, the key elements that contribute to it, and the important metrics needed to measure it. We present our key findings, lessons learned, and recommendations.
LUX-ZEPLIN (LZ) is a direct detection dark matter experiment currently operating at the Sanford Underground Research Facility (SURF) in Lead, South Dakota. The core component is a liquid xenon time projection chamber with an active mass of 7 tonnes.
To meet the performance, availability, and security requirements for the LZ DAQ, Online, Slow Control and data transfer systems located at SURF, we have developed and implemented a standalone IT infrastructure. It consists of a fully redundant 10 Gigabit network spanning underground and surface locations with hybrid virtual/physical data centers in both places. We employ virtualization, redundant firewalls, central authentication and user management, a web portal, 2-factor authentication for all remote access, VPN, fine-grained authorization and role management via a central directory, SAML identity and service providers, central configuration management, logging, monitoring, multiple relational databases, and frequent on-site and offsite backups. We exclusively use Open Source tools to provide these services.
Data is sent from SURF to the National Energy Sciences Computer Center (NERSC) in Berkeley, California which provides CPU and storage for reconstruction and analysis.
The system has been running reliably since its installation at SURF in 2019. We currently manage about 100 physical and virtual servers and almost 300 user accounts with 10-20 users online at any time.
This presentation will give an overview of the system and report on the operational experience.
Recent years have seen an increasing interest in the environmental impact, especially the carbon footprint, generated by the often large scale computing facilities used by the communities represented at CHEP. As this is a fairly new requirement, this information is not always readily available, especially at universities and similar institutions which do not necessarily see large scale computing provision as their core competency. Here we present the results of a survey of a large WLCG Tier 2 with respect to power usage and carbon footprint leveraging all sources of information available to us: Power usage data collected from built-in host level monitoring and external aggregates from the power distribution units at rack level; data sheets provided by the hardware manufacturers and the specifics of data centre that hosts our infrastructure.
We show that it is possible to estimate the environmental impact without having to invest in dedicated monitoring equipment, but also discuss the limitations of this approach.
The INFN Tier1 data center is currently located in the premises of the Physics Department of the University of Bologna, where CNAF is also located. During 2023 it will be moved to the “Tecnopolo”, the new facility for research, innovation, and technological development in the same city area; the same location is also hosting Leonardo, the pre-exascale supercomputing machine managed by CINECA, co-financed as part of the EuroHPC Joint Undertaking, 4th ranked in the top500 November 2022 list.
The construction of the new CNAF data center consists of two phases, corresponding to the computing requirements of LHC: Phase 1 involves an IT power of 3 MW, and Phase 2, starting from 2025, involves an IT power up to 10 MW.
The new datacenter is designed to cope with the computing requirements of the data taking of the HL-LHC experiments, in the time spanning from 2026 to 2040 and will provide, at the same time, computing services for several other INFN experiments and projects, not only belonging to the HEP domain. The co-location with Leonardo opens wider possibilities to integrate HTC and HPC resources and the new CNAF datacenter will be tightly coupled with it, allowing access from a single entrypoint to resources located at CNAF and provided by the supercomputer. Data access from both infrastructures will be transparent to users.
In this presentation we describe the new data center design, providing a status update on the migration, and we focus on the Leonardo integration showing the results of the preliminary tests to access it from the CNAF access points.
Queen Mary University of London (QMUL) as part of the refurbishment of one of its's data centres has installed water to water heat pumps to use the heat produced by the computing servers to provide heat for the university via a district heating system. This will enable us to reduce the use of high carbon intensity natural gas heating boilers, replacing them with electricity which has a lower carbon intensity due to the contribution from wind, solar, hydroelectric, nuclear, biomass sources of power sources.
The QMUL GridPP cluster today provides 15PB of storage and over 20K jobs slots mainly devoted to the ATLAS experiment. The data centre that houses the QMUL GridPP cluster, was originally commissioned in 2004. By 2020 it was in significant need of refurbishment. The original design had a maximum power capacity of 200KW, no hot/cold aisle containment, down flow air conditioning units using refrigerant cooling and no raised floor or ceiling plenum.
The main requirements of the refurbishment are: To significantly improve the energy efficiency and reduce the carbon usage of the University; Improve the availability and reliability of the power and cooling; Increase the capacity of the facility to provide for future expansion; Provide a long term home for the GridPP cluster to support the computing needs of the LHC and other new large science experiments (SKA/LSST) into the next decade.
After taking into account the future requirements and likely funding allocation, floor space in the datacentre and the space available to house the cooling equipment the following design was chosen: A total power capacity of 390KW with redundant feeds to each rack; 39 racks with an average of 10KW of power per rack (flexable up to 20KW); An enclosed hot aisle design with in row cooling units using water cooling; water to water heat pumps connected to the universities district heating system
An overview of the project, it's status and expected benefits in power and carbon saving are presented.
Synergies between MAchine learning, Real-Time analysis and Hybrid architectures for efficient Event Processing and decision making (SMARTHEP) is a European Training Network with the aim of training a new generation of Early Stage Researchers to advance real-time decision-making, effectively leading to data-collection and analysis becoming synonymous.
SMARTHEP will bring together scientists from the four major LHC collaborations which have been driving the development of real-time analysis (RTA) and key specialists from computer science and industry. By solving concrete problems as a community, SMARTHEP will bring forward a more widespread use of RTA techniques, enabling future HEP discoveries and generating impact in industry.
The students will contribute to European growth, leveraging their hands-on experience machine learning and accelerators towards concrete commercial deliverables in fields that can most profit from RTA, such as transport, manufacturing, and finance.
This contribution presents the training and outreach plan for the network, as well as some of its early results, and is intended as an opportunity for further collaboration and feedback from the CHEP community.
In this contribution we describe the 2022 reboot of the ScienceBox project, the containerised SWAN/CERNBox/EOS demonstrator package for CERN storage and analysis services. We evolved the original implementation to make use of Helm charts across the entire dependency stack. Charts have become the de-facto standard for application distribution and deployment in managed clusters (e.g., Kubernetes, OpenShift), providing developers and operators with a rich ecosystem of tools to benefit from, as well as the handles to configure applications and rollout changes in a programmatic way.
At the same time, we incorporated in ScienceBox the major architectural update to CERNBox, replacing the previous PHP backend with distributed microservices based on Reva. Besides enhancing our existing use cases, the new CERNBox implementation enables and streamlines interoperability with additional applications and sites deployed under the same technology.
We present this update as a self-contained and easy-to-use package with minimal dependencies and with the same goals as the original ScienceBox: Provide a sandbox to evaluate the storage, sharing, and analysis services we run at CERN on external premises to non-CERN users. We believe there is not only a great value in releasing and contributing back to the open source projects that sustain these services, but also in describing the configuration and artifacts that make operating such complex software systems at scale possible.
In the frame of the German NFDI (National Research Data Infrastructure), by now 27 consortia across all domains of science have been setup in order to enhance the FAIR usage and re-usage of scientific data. The consortium PUNCH4NFDI, composed of the German particle, astroparticle, hadron&nuclear, and astrophysics communities, has been approved for initially 5 years of significant funding.
On its way towards its still visionary science data platform – a biotope for the entire lifecycle of digital research products – PUNCH4NFDI has already made substantial achievements. To provide a federated infrastructure for the involved communities, prototypes of the Computer4PUNCH and Storage4PUNCH servers have been setup that employ established components and middleware from the WLCG community. Existing workflow execution engines are evaluated and adopted for an increasing number of usecases from the participating science disciplines. Work on overarching metadata schemata and related services is ongoing. Furthermore, a set of outreach and education & training activities is being devised, and the integration of the consortium and the disciplines represented by it into the greater German “National Research Data Infrastructure” is progressing, respecting European and international boundary conditions and efforts.
This contribution lays out the plan of the consortium and presents what it could contribute to the joint effort of the international HEP community.
Planned EOSC-CZ projects will significantly improve data management in many scientific fields in the Czech Republic. Several calls for projects are under preparation according to the implementation architecture document created in 2021. Emerging National data infrastructure will build basic infrastructure with significant storage capacity for long term archive of scientific data and their accessibility from computing resources. National metadata directory project covers findability and interoperability of data. National repository platform project will operate storage services and related services like authentication and authorization. The system will support already existing data repositories to avoid data duplication, but still to ensure unified access to data. Another project will cover education of researchers and specialists for data curation. About eight additional projects will cover different scientific fields.
The prepared project for physical sciences will bring together small groups producing data on apparatuses in different laboratories with large projects from high energy physics. Many HEP projects are well advanced in ensuring FAIR principles in data management. Some of their data management tools can be used by small groups if sufficient support is available. We present several examples of differences in requirements on data volumes, their structure and description via metadata together with planned solution how to spread FAIR standards to all participating physics projects.
High Energy Physics experiments at the Large Hadron Collider generate petabytes of data that go though multiple transformation before final analysis and paper publication. Recording the provenance of these data is therefore crucial to maintain the quality of the final results. While the tools are in place within LHCb to keep this information for the common experiment-wide transforms, analysts have to implement solutions themselves for the steps dealing with ntuples. The gap between centralised and interactive processing can become problematic. In order to facilitate the task, ntuples extracted by LHCb analysts via so-called “Analysis Productions” are tracked in the experiment bookkeeping database and can be enriched with extra information about their meaning and intended use. This information can then be used to access the data more easily: a set of Python tools allow locating the files based on their metadata and integrating their processing within analysis workflows. The tools are designed with the intention of ensuring analysis code continues to be functional into the future and are robust against evolutions in how data is accessed. This paper presents the integration of these new tools within the LHCb codebase and demonstrates how they will be used in LHCb data processing and analysis.
The increasingly pervasive and dominant role of machine learning (ML) and deep learning (DL) techniques in High Energy Physics is posing challenging requirements to effective computing infrastructures on which AI workflows are executed, as well as demanding requests in terms of training and upskilling new users and/or future developers of such technologies.
In particular, a growth in the request for training opportunities to become proficient in exploiting programmable hardware capable of delivering low latencies and low energy consumption, like FPGAs, is observed. While training opportunities on generic ML/DL concepts is rich and quite wide in the coverage of sub-topics, a gap is observed in the delivery of hands-on tutorials on ML/DL on FPGAs that can scale to a relatively large number of attendants and that can give access to a relatively diverse set of ad-hoc hardware with different hardware specs.
A pilot course on ML/DL on FPGAs - born from the collaboration of INFN-Bologna, the University of Bologna and INFN-CNAF - has been successful in paving the way for the creation of a line of work dedicated to maintaining and expanding an ad-hoc scalable toolkit for similar courses in the future. The practical sessions are based on virtual machines (for code development, no FPGAs), in-house cloud platforms (INFN-cloud infrastructure equipped with AMD/Xilinx Alveo FPGA), Amazon AWS instances for project deployment on FPGAs - all complemented by docker containers with the full environments for the DL frameworks used, as well as Jupyter Notebooks for interactive exercises. The current results and plans of work along the consolidation of such a toolkit will be presented and discussed.
Finally, a software ecosystem called Bond Machine, capable of dynamically generate computer architectures that can be synthesised in FPGA, is being considered as a suitable alternative to teach FPGA programming without entering into the low-level details, thanks to the hardware abstraction it offers which can simplify the interaction with FPGAs.
Future e+e- colliders are crucial to extend the search for new phenomena possibly related to the open questions that the Standard Model presently does not explain. Among the major physics programs, the flavor physics program requires particle identification (PID) performances well beyond that of most detectors designed for the current generation. The cluster counting, which measures the number of primary ionizations (dN/dx) instead of the energy loss (dE/dx) along the particle trajectory in a gaseous detector, represents the most promising breakthrough in PID. The Poissonian nature of the dN/dx offers a more statistically significant way of ionization measurement, which makes the dN/dx potentially has a resolution two times better than the dE/dx. Drift chamber (DC) with cluster counting has been proposed as the future advanced detector candidates for Circular Electron Positron Collider (CEPC) and Future Circular Collider (FCC).
Machine learning (ML) algorithms, which are designed to exploit large datasets to reduce complexity and find new features in data, are the state-of-the-art in PID. The reconstruction of dN/dx measurement needs to determine the number of peaks associated with the primary ionizations in the induced current waveform in a DC cell. The major challenges of the reconstruction are to detect peaks in the highly pileup and noisy situations, and to discriminate the peaks formed by the primary and secondary ionizations. Traditional method, such as taking derivatives, can hardly reach the required efficiency due to the inefficient use of the information. In this study, a two-step ML based algorithm is developed for the dN/dx reconstruction. The algorithm consists of an RNN-based peak finding model, and a CNN-based discrimination model. According to the simulated results, the performance of the ML algorithm surpasses the derivative algorithm in terms of detection efficiency and resolution. The algorithm is further demonstrated by analyzing the test beam data taken at CERN and preliminary results will be presented.
Recent inroads in Computer Vision (CV), enabled by Machine Learning (ML), have motivated a new approach to the analysis of particle imaging detector data. Unlike previous efforts which tackled isolated CV tasks, this paper introduces an end-to-end, ML-based data reconstruction chain for Liquid Argon Time Projection Chambers (LArTPCs), the state-of-the-art in precision imaging at the intensity frontier of neutrino physics. The chain is a multi-task network cascade which combines voxel-level feature extraction using Sparse Convolutional Neural Networks and particle superstructure formation using Graph Neural Networks. Each individual algorithm incorporates physics-informed inductive biases, while their collective hierarchy enforces a causal relashionship between them. The output is a comprehensive description of an event that may be used for high-level physics inference. The chain is end-to-end optimizable, eliminating the need for time-intensive manual software adjustments. The ICARUS detector, part of the short baseline neutrino (SBN) program at Fermilab, is the largest LArTPC built and operated to date and is used to assess the performance of this reconstruction chain in a realistic setting.
I will introduce a new neural algorithm -- HyperTrack, designed for exponentially demanding combinatorial inverse problems of high energy physics final state reconstruction and high-level analysis at the LHC and beyond. Many of these problems can be formulated as clustering on a graph resulting in a hypergraph. The algorithm is based on a machine learned geometric-dynamical input graph constructor and a neural network operating on that graph. The neural model is built using a graph neural network and a set transformer, which are end-to-end optimized under a fusion loss function targeting simultaneously the graph node, edge and clustering objectives. The clustering procedure can be changed according to the problem complexity requirements, from a greedy diffusion like iteration to a more computationally demanding but powerful Monte Carlo search based. I will demonstrate the scalability and physics performance of this cutting-edge approach with simulations and discuss possible future directions towards a hybrid quantum computer algorithm.
Modern neutrino experiments employ hundreds to tens of thousands of photon detectors to detect scintillation photons produced from the energy deposition of charged particles. A traditional approach of modeling individual photon propagation as a look-up table requires high computational resources, and therefore it is not scalable for future experiments with multi-kiloton target volume.
We propose a new approach using SIREN, an implicit neural representation with periodic activation functions, to model the look-up table as a 3D scene. It reproduces the acceptance map with high accuracy using orders of magnitude less number of parameters than the look-up table. As a continuous and differentiable parameterization, SIREN also represents a smooth gradient surface. As such, it allows downstream applications such as inverse problem-solving and gradient-based optimizations. We demonstrate a data-driven method to optimize the SIREN model and an application of reconstruction using data collected from the Deep Underground Neutrino Experiment's (DUNE) near detector prototype.
The Deep Underground Neutrino Experiment (DUNE) will operate four large-scale Liquid-Argon Time-Projection Chambers (LArTPCs) at the far site in South Dakota, producing high-resolution images of neutrino interactions.
LArTPCs represent a step-change in neutrino interaction imaging and the resultant images can be highly detailed and complex. Extracting the maximum value from LArTPC hardware requires correspondingly sophisticated pattern-recognition software to interpret signals from the detectors as physically meaningful objects that form the inputs to physics analyses. A critical component is the identification of the neutrino interaction vertex, which is non-trivial due to the interaction occurring at any point within the detector volume. Subsequent reconstruction algorithms use this location to identify the individual primary particles and ensure they each result in a separate reconstructed particle.
A new vertex-finding procedure presented in this talk integrates a U-Net performing hit-level classification into the multi-algorithm approach used by the Pandora pattern recognition framework to identify the neutrino interaction vertex. The machine learning solution is seamlessly integrated into a chain of traditional pattern-recognition algorithms incorporating knowledge of the detector, demonstrating that traditional and machine learning methods need not be mutually exclusive in leveraging the potential of machine learning for neutrino physics.
The Exa.TrkX team has developed a Graph Neural Network (GNN) for reconstruction of liquid argon time projection chamber (LArTPC) data. We discuss the network architecture, a multi-head attention message passing network that classifies detector hits according to the particle type that produced them. By utilizing a heterogeneous graph structure with independent subgraphs for each 2D plane’s hits and for 3D space points, the model achieves a consistent description of the neutrino interaction across all planes.
Performance results will be presented based on publicly available samples from MicroBooNE. These will include both physics performance metrics, achieving ~95% accuracy when integrated over all particle classes, and computational metrics for training on single or distributed GPU systems and for inference on CPU or GPU.
We will discuss applications of the network for additional LArTPC reconstruction tasks, such as event classification, cosmic rejection and particle instance segmentation. Prospects for integration in the data processing chains of experiments will also be presented.
High energy physics is facing serious challenges in the coming decades due to the projected shortfall of CPU and storage resources compared to our anticipated budgets. In the past, HEP has not made extensive use of HPCs, however the U.S. has had a long term investment in HPCs and it is the platform of choice for many simulation workloads, and more recently, data processing for projects such as LIGO, the light sources, sky surveys, as well as for many AI and ML tasks. By mid to late decade, we expect on the order of 10 exaflops of peak power to be available in HPCs, and an order of magnitude more in the following decade. This is at least two orders of magnitude more than HEP requires, but it would be a significant challenge for HEP experiments to use, especially since most of the cycles will be provided by accelerators like GPUs. Can the HEP community leverage these resources to address our computational shortfalls?
The High Energy Physics Center for Computational Excellence (HEP-CCE), a 3 year pilot project which started in 2020, was formed to investigate this challenge, and provide strategies for HEP experiments to make use of HPC and other massively parallel resources. HEP-CCE functions in close co-operation with the stakeholder experiments, and is split into 4 parts. The first is to investigate Portable Parallelization Strategies, to make use of the massive available parallelism in GPU enabled HPCs, and to engineer portable coding solutions that allow single source software to run on all architectures. The second is to tackle fine grained I/O and the related storage issues on HPCs, by enhancing the existing Darshan HPC I/O monitoring tool to handle HEP workflows and characterize those for ATLAS, CMS & DUNE, developing a I/O mimicking framework allowing scalability studies for different I/O implementations (including ROOT, HDF5) in regimes not yet accessible to HEP production jobs, using HDF5 via ROOT serialization with parallel I/O and investigating new data model with more performant I/O and offloading to GPU resources. The third looks at Event Generators, such as MadGraph and Sherpa, to convert them to run efficiently on GPUs. And the last is to understand how we can map our Complex Workflows onto HPC resources, which are very different from normal HPC workflows.
In this submission we present the results of our 3 year investigations from all 4 domains and give an outlook on recommendations for current and future HEP experiments on how to best use the U.S. HPC environment.
The INFN-CNAF Tier-1 located in Bologna (Italy) is a center of the WLCG e-Infrastructure providing computing power to the four major LHC collaborations and also supports the computing needs of about fifty more groups - also from non HEP research domains. The CNAF Tier1 center has been historically very active putting effort in the integration of computing resources, proposing and prototyping solutions both for extension through Cloud resources, public and private, and with remotely owned sites, as well as developing an integrated HTC+HPC system with the PRACE CINECA supercomputer center located 8Km far from the CNAF Tier-1 located in Bologna. In order to meet the requirements for the new Tecnopolo center, where the CNAF Tier-1 will be hosted, the resource integration activities keep progressing. In particular, this contribution will detail the challenges that have recently been addressed, providing opportunistic access to non standard CPU architectures, such as PowerPC and hardware accelerators (GPUs). We explain the strategy adopted to both transparently provision x86_64, ppc64le and nVidia V100 GPUs from the Marconi 100 HPC cluster managed by CINECA and to access data from the Tier1 storage system at CNAF. Finally we will discuss the results of the early experience.
The computing and storage requirements of the energy and intensity frontiers will grow significantly during the Run 4 & 5 and the HL-LHC era. Similarly, in the intensity frontier, with larger trigger readouts during supernovae explosions, the Deep Underground Neutrino Experiment (DUNE) will have unique computing challenges that could be addressed by the use of parallel and accelerated data-processing capabilities. Most of the requirements of the energy and intensity frontier experiments rely on increasing the role of high performance computing (HPC) in the HEP community. In this presentation, we will describe our ongoing efforts that are focused on using HPC resources for the next generation HEP experiments. The HEP-CCE (High Energy Physics-Center for Computational Excellence) IOS (Input/Output and Storage) group has been developing approaches to map HEP data to the HDF5 , an I/O library optimized for the HPC platforms to store the intermediate HEP data. The complex HEP data products are ROOT serialized before mapping into the HDF5 format. The mapping of the data products can be designed to optimize parallel I/O. Similarly, simpler data can be directly mapped into the HDF5, which can also be suitable for offloading into the GPUs directly. We will present our works on both complex and simple data model models.
Random number generation is key to many applications in a wide variety of disciplines. Depending on the application, the quality of the random numbers from a particular generator can directly impact both computational performance and critically the outcome of the calculation.
High-energy physics applications use Monte Carlo simulations and machine learning widely, which both require high-quality random numbers. In recent years, to meet increasing performance requirements, many high-energy physics workloads leverage GPU acceleration. While on a CPU, there exist a wide variety of generators with different performance and quality characteristics, the same cannot be stated for GPU and FPGA accelerators.
On GPUs, the most common implementation is provided by cuRAND - an NVIDIA library that is not open source or peer reviewed by the scientific community. The highest-quality generator implemented in cuRAND is a version of the Mersenne Twister. Given the availability of better and faster random number generators, high-energy physics moved away from Mersenne Twister several years ago and nowadays MixMax is the standard generator in Geant4 via CLHEP.
The MixMax original design supports parallel streams with a seeding algorithm that makes it especially suited for GPU and FPGA where extreme parallelism is a key factor. In this study we implement the MixMax generator on both architectures and analyze its suitability and applicability for accelerator implementations. We evaluated the results against “Mersenne Twister for a Graphic Processor” (MTGP32) on GPUs which resulted in 5, 13 and 14 times higher throughput when a 240, 17 and 8 sized vector space was used respectively. The MixMax generator coded in VHDL and implemented on Xilinx Ultrascale+ FPGAs, requires 50% fewer total LUTs compared to a 32-bit Mersenne Twister (MT-19337), or ~75% fewer LUTs per output bit.
In summary, the state-of-the art MixMax pseudo random number generator has been implemented on GPU and FPGA platforms and the performance benchmarked.
Large-scale high-energy physics experiments generate petabytes or even exabytes of scientific data, and high-performance data IO is required during their processing. However, computing and storage devices are often separated in large computing centers, and large-scale data transmission has become a bottleneck for some data-intensive computing tasks, such as data encoding and decoding, compression, sorting, etc. Data transfer can take up to 30% of the entire computing process. The more data is called in a compute task, the more obvious this cost becomes. One attractive solution to this problem is to offload some of the data processing to the storage layer. However, modifying legacy storage systems to support compute offloading is often tedious and requires an extensive understanding of the internals.
Therefore, we have designed a new software framework XkitS for building computational storage systems by extending the existing storage system, EOS. The framework is deployed on EOS FTS storage servers and offloads computing tasks by calling the computing power (including CPU, FPGA, etc.) on FST. XkitS can embed multiple data processing methods into the storage layer, which can be implemented in scripting languages or evolved independently of the storage system in the form of containers. On the storage server side, XkitS implements an XRootD plugin that executes first when FTS receives a file access request. It calls the target program on the storage server by parsing the parameters of the command to open file. At this point, the input file is on the FTS storage server, and the output file is also written on it. At the end of the task execution, the file is automatically registered with the MGM metadata server. On the storage client side, XkitS is fully compatible with XRootD's API and EOS commands. Users can add tasks and parameters to be performed in the open option. XkitS processing is black-box for users, and they get the same results as they normally would, but jobs are processed faster and queues are avoided. At present, it has been tested and applied in the data processing of the Large High Altitude Air Shower Observatory (LHAASO), and the results show that the efficiency of data decoding is more than 5 times higher than the original method.
The IceCube experiment has substantial simulation needs and is in continuous search for the most cost-effective ways to satisfy them. The most CPU-intensive part relies on CORSIKA, a cosmic ray air shower simulation. Historically, IceCube relied exclusively on x86-based CPUs, like Intel Xeon and AMD EPYC, but recently server-class ARM-based CPUs are also becoming available, both on-prem and in the cloud.
In this paper we present our experience in running a sample CORSIKA simulation on both ARM and x86 CPUs available through Google Kubernetes Engine (GKE). We used the production binaries for the x86 instances, but had to build the binaries for ARM instances from source code, which turned out to be mostly painless. Our benchmarks show that ARM-based CPUs in GKE are not only the most cost-effective but are also the fastest in absolute terms in all the tested configurations. While the advantage is not drastic, about 20% in cost-effectiveness and less than 10% in absolute terms, it is still large enough to warrant an investment in ARM support for IceCube.
The goal of the “HTTP REST API for Tape” project is to provide a simple, minimalistic and uniform interface to manage data transfers between Storage Endpoints (SEs) where the source file is on tape. The project is a collaboration between the developers of WLCG storage systems (EOS+CTA, dCache, StoRM) and data transfer clients (gfal2, FTS). For some years, HTTP has been growing in popularity as the preferred data transfer protocol between many WLCG SEs. However — unlike other protocols such as XRootD and SRM — HTTP does not include a method to stage files from tape to disk prior to transfer, forcing the use of workarounds such as hybrid protocols (different protocols used for the “stage” and “transfer” parts of the operation). The HTTP REST API offers a simple and consistent solution, by extending the HTTP protocol to include staging operations. It provides clients with a common and consistent API across different storage systems to manage and monitor the disk and tape residency of stored files. In this contribution, we present the history and motivation of the HTTP REST API project, the specification of version 1 of the API and implementation details in the various storage and data transfer systems. We also describe our experiences of its deployment and use for LHC Run-3 operations. We conclude with a discussion of possible future work.
CDS (Custodial Disk Storage), a disk-based custodial storage powered by CERN EOS storage system, has been operating for the ALICE experiment at the KISTI Tier-1 Centre since November 2021. The CDS replaced existing tape storage operated for almost a decade, after its stable demonstration in the WLCG Tape Challenges in October 2021. We tried to challenge the economy of tape storage in the aspects of data protection and storage capacity by purchasing cheap off-the-shelf disk enclosures and applying four-parity mode of EOS RAIN (Redundant Array of Independent Nodes) layout. In order to get a brief picture of the TCO (Total Cost of Ownership) of the CDS comparing with tape storage, we tried to conduct an estimation of acquisition, operation and other costs on both tape and disk-based custodial storages. A detailed discussion will be presented including capital and operating expenses over time for the custodial storages such as initial purchases and their expansions (with some predictions on the CDS), spaces, installation, software and hardware licenses, maintenance and power consumption.
The High Luminosity upgrade to the LHC (HL-LHC) is expected to deliver scientific data at the multi-exabyte scale. In order to address this unprecedented data storage challenge, the ATLAS experiment launched the Data Carousel project in 2018. Data Carousel is a tape-driven workflow whereby bulk production campaigns with input data resident on tape are executed by staging and promptly processing a sliding window to disk buffer such that only a small fraction of inputs are pinned on disk at any one time. Data Carousel is now in production for ATLAS in Run3. In this paper, we will provide updates on recent Data Carousel R&D projects, including data-on-demand and tape smart writing. Data-on-demand removes from disk data that has not been accessed for a predefined period, when users request them, they will be either staged from tape or recreated by following the original production steps. Tape smart writing employs intelligent algorithms for file placement on tape in order to retrieve data back more efficiently, which is our long term strategy to achieve optimal tape usage in Data Carousel.
The CERN IT Department is responsible for ensuring the integrity and security of data stored in the IT Storage Services. General storage backends such as EOSHOME/PROJECT/MEDIA and CEPHFS are used to store data for a wide range of use cases for all stakeholders at CERN, including experiment project spaces and user home directories.
In recent years a backup system, CBACK, was developed based on the open source backup program Restic. CBACK is currently used to backup all CERNBox data (about 18PB) stored on disks in the CERN Computing Centre to a disk based S3 service instance in the Prevessin Nethub.
To significantly increase the reliability and security of the backups and reduce the storage costs, by limiting the amount of data on disk, we have added a tape storage backend to CBACK. Tape backup also offers a better protection against potential ransomware attacks. To achieve this we have created a transparent interface to the CERN Tape Archive (CTA) service.
With this addition CBACK can reliably be extended to new use cases. CBACK has already been extended to backup CephFS Manila shares and in principle can be used to back up any local mountable file system, such as EOS, CephFS, NFS or DFS. Furthermore, CBACK can potentially serve as a replacement for certain use cases currently covered by IBM Spectrum Protect, including the backup of PCs belonging to individual users.
In this presentation we will describe the architecture and implementation of CBACK with the new tape storage backend and a number of developments planned for the near future.
The CERN Tape Archive (CTA) was conceived as the successor to CASTOR and as the tape back-end to EOS, designed for the archival storage of data from LHC Run-3 and other experimental programmes at CERN. In the wider WLCG, the tape software landscape is quite heterogenous, but we are now entering a period of consolidation. This has led to a number of sites in WLCG (and beyond) reevaluating their options and choosing CTA for their future tape archival storage needs. However, the original mandate for CTA created a number of design constraints which are not necessarily optimal for other sites beyond CERN Tier-0. In this contribution, we discuss how the CTA team has engaged with the wider HEP community and collaborated on changes to the software to allow it to be adopted more widely. In particular, we describe community contributions to CTA to allow it to be used as the tape backend for dCache, and to allow migrations from other tape systems such as Enstore. In addition, we discuss improvements to the building and packaging of CTA to remove CERN-specific dependencies and to facilitate easy distribition to other sites, and describe the schema upgrade procedure for the CTA Catalogue database. Finally, we present a roadmap for the community edition of CTA.
The Large Hadron Collider (LHC) will be upgraded to High-luminosity LHC, increasing the number of simultaneous proton-proton collisions (pile-up, PU) by several-folds. The harsher PU conditions lead to exponentially increasing combinatorics in charged-particle tracking, placing a large demand on the computing resources. The projection on required computing resources exceeds the computing budget with the current algorithms running on single-thread CPUs. Motivated by the rise of heterogeneous computing in high-performance computing centers, we present Line Segment Tracking (LST), a highly parallelizeable algorithm that can run efficiently on GPUs and has been integrated to the CMS experiment central software. The usage of Alpaka framework for the algorithm implementation allows better portability of the code to run on different types of commercial parallel processors allowing flexibility on which processors to purchase for the experiment in the future. To verify a similar computational performance with a native solution, the alpaka implementation is compared with a cuda one on a NVIDIA Tesla V100 GPU. The algorithm creates short track segments in parallel, and progressively form higher level objects by linking segments that are consistent with genuine physics track hypothesis. The computing and physics performance are on par with the latest, multi-CPU versions of existing CMS tracking algorithms.
The LHCb experiment is currently taking data with a completely renewed DAQ system, capable for the first time of performing a full real-time reconstruction of all collision events occurring at LHC point 8.
The Collaboration is now pursuing a further upgrade (LHCb "Upgrade-II"), to enable the experiment to retain the same capability at luminosities an order of magnitude larger than the maximum planned for the current Run 3. To this purpose, a vigorous R&D program is ongoing to boost the real-time processing capability of LHCb, needed to cope both with the luminosity increase and the adoption of correspondingly more granular and complex detectors.
New heterogeneous computing solutions are being explored, with the aim of moving reconstruction and data reduction to the earliest possible stages of processing. In this talk we describe the results obtained from a realistic demonstrator for a high-throughput reconstruction of tracking detectors, operated parasitically on real LHCb data from Run 3 in a purposedly built testbed facility. This demonstrator is based on a extremely parallel, 'artificial retina' architecture, implemented in commercial, PCIe-hosted FPGA cards interconnected by fast optical links, and encompasses a sizable fraction of the LHCb VELO pixel detector. The implications of the results in view of potential applications in HEP are discussed.
The High-Luminosity LHC (HL-LHC) will provide an order of magnitude increase in integrated luminosity and enhance the discovery reach for new phenomena. The increased pile-up foreseen during the HL-LHC necessitates major upgrades to the ATLAS detector and trigger. The Phase-II trigger will consist of two levels, a hardware-based Level-0 trigger and an Event Filter (EF) with tracking capabilities. Within the Trigger and Data Acquisition group, a heterogeneous computing farm consisting of CPUs and potentially GPUs and/or FPGAs is under study, together with the use of modern machine learning algorithms such as Graph Neural Networks (GNNs).
GNNs are a powerful class of geometric deep learning methods for modelling spatial dependencies via message passing over graphs. They are well-suited for track reconstruction tasks by learning on an expressive structured graph representation of hit data and considerable speedup over CPU-based execution is possible on FPGAs.
The focus of this talk is a study of track reconstruction for the Phase-II EF system using GNNs on FPGAs. We explore each of the steps in a GNN-based EF tracking pipeline: graph construction, edge classification using an interaction network, and track reconstruction. Several methods and hardware platforms are under evaluation, studying resource utilisation and minimization of model size using quantization aware training, while simultaneously retaining high track reconstruction efficiency and low fake rates required for the EF tracking system.
During the LHC Run 3, the significant upgrades on many detectors and a brand new reconstruction software allows the ALICE experiment to record Pb-Pb collisions at an interaction rate of 50 kHz in a trigger-less continuous readout mode.
The key to process the 1TB/s peak data rate in ALICE is the usage of GPUs. There are two main data processing phases: the synchronous phase, where the TPC reconstruction uses most computing resources, and the asynchronous one, where more GPU resources are available.
Other detectors are aiming at profiting from this computing potential to offload their reconstructions on graphics cards.
In this talk, we illustrate how we successfully ported on GPU both the primary vertex finding and the track reconstruction of the silicon tracker of ALICE, the Inner Tracking System.
We implemented, integrated, and natively supported the ITS code using automatic code generation on two different GPU brands with a single code base.
The implementation details, performance, and how this technique can be easily used in other applications will be discussed.
The LHCb experiment has recently started a new period of data taking after a major upgrade in both software and hardware. One of the biggest challenges has been the migration of the first part of the trigger system (HLT1) into a parallel GPU architecture framework called Allen, which performs a partial reconstruction of most of the LHCb sub-detectors. In Allen, the reconstruction of the Electromagnetic Calorimeter (ECAL) sub-detector is used in many selection algorithms, but its efficiency is currently 10% lower than the full reconstruction performed in the second stage of the trigger. In this talk, we present a preliminary performance study of an alternative ECAL reconstruction algorithm implemented in Allen that complements the current algorithm to maximise the reconstruction efficiency and also minimise the impact on the throughput rate.
The sensitivity of modern HEP experiments to New Physics (NP) is limited by the hardware-level triggers used to select data online, resulting in a bias in the data collected. The deployment of efficient data acquisition systems integrated with online processing pipelines is instrumental to increase the experiments' sensitivity to the discovery of any anomaly or possible signal of NP. In designing such systems the combination of heterogeneous processing elements, including FPGAs and GPUs, is foreseen to sustain the large throughput of raw data from the detectors.
In this work, we present the first implementation of an end-to-end infrastructure that acquires continuously data from an experimental setup and processes it online looking for statistical anomalies using a Machine Learning (ML) technique. The infrastructure is deployed at the INFN Legnaro National Laboratory (LNL) and reads out data from a reduced-sized version of the drift tube muon detector of the CMS experiment at CERN. The data stream is first processed by an FPGA to cluster signals associated with the passage of a muon through the detector and produce candidate stubs. Candidate events are then reconstructed and all muon hits and the reconstructed muon stubs are analyzed online by an algorithm deployed on a GPU to perform unbiased data exploration and statistical anomaly detection. The New Physics Learning Machine (NPLM) technique is used to evaluate the compatibility between incoming batches of experimental data and a reference sample representing the normal behavior of the data. In the specific case of the LNL test stand, the NPLM algorithm uses as a reference sample a dataset gathered in nominal detector conditions; data deviations from the normal behavior, if detected, are characterized and then mapped to known sources of detector malfunctioning with some degree of confidence. Unexpected behaviors, that might signal the presence of New Physics, can be singled out if the observed discrepancy doesn't match any of the expected anomalies. The system is currently dealing with the limited throughput originated by the cosmic muon flux; nevertheless, all components of the readout chain are designed to scale up and be eventually employed in experiments at the LHC.
In this contribution, we describe the technical implementation of the online processing pipeline and assess the performance of its most critical components.
The CMS Tier-0 service is responsible for the prompt processing and distribution of the data collected by the CMS Experiment. A number of upgrades were implemented during the long shutdown of the Large Hadron Collider, which improved the performance and reliability of the service. We report our experience of the data taking during Run-3 detector commissioning as well as performance of the system with respect to Run-2.
(on behalf of the JUNO Collaboration)
Jiangmen Underground Neutrino Observatory (JUNO), under construction in southern China, is a multi-purpose neutrino experiment designed to determine the neutrino mass hierarchy and precisely measure oscillation parameters. Equipped with a 20-kton liquid scintillator central detector viewed by 17,612 20-inch and 25,6000 3-inch photomultiplier tubes, JUNO could reach the unprecedented energy resolution of 3% at 1 MeV.
JUNO is expected to start data taking in 2024 and plans to run for more than 20 years with about 2 petabytes of raw data each year. The large volume of data has brought a great challenge to the JUNO offline data processing and analysis.
This contribution will comprehensively review the development of JUNO offline software (JUNOSW) which started in 2012 in order to support JUNO’s specific requirements, and will particularly highlight the following topics:
1) Data processing framework which supports buffering and management of multiple events, event splitting and mixing, TBB-based multi-threading, and integration of machine learning etc.
2)Unified detector geometry management to support multiple applications including simulation, calibration, reconstruction and detector visualization.
3)ROOT based event data model charactering data representations at different processing stages and complicated relationships between them.
4)Event index based correlation analysis to support selection of sparse physics events from the large volume of data.
The JUNO data processing and analysis chain was completed and has been used by several rounds of Monte Carlo data challenge on both local computing clusters and the distributed computing infrastructure.
The former CMS Run 2 High Level Trigger (HLT) farm is one of the largest contributors to CMS compute resources, providing about 30k job slots for offline computing. The role of this farm has been evolving, from an opportunistic resource exploited during inter-fill periods in the LHC Run 2, to a nearly transparent extension of the CMS capacity at CERN during LS2 and into the LHC Run 3 started in 2022. This “permanent cloud” is located on-site at the LHC interaction point 5, where the CMS detector is installed. As a critical example, the execution of Tier 0 tasks, such as prompt detector data reconstruction, has been fully commissioned. This resource can therefore be used in combination with the dedicated Tier 0 capacity at CERN, in order to process and absorb peaks in the stream of data coming from the CMS detector, as well as contributing to the prompt reconstruction of a substantial fraction of the “parked data sample”, dedicated primarily to B physics studies. The initial deployment model for this resource, based on long-lived statically configured VMs, including HTCondor execution node services connected to the CMS Submission Infrastructure (SI), provided the required level of functionality to enable its exploitation for offline computing. However, this configuration presented certain limitations in its flexibility of use in comparison to pilot-based resource acquisition at the WLCG sites. For example, slot defragmentation techniques were required to enable matching of Tier 0 multicore jobs. Additionally, the configuration of fair-share quotas and priorities for the diverse CMS tasks could not be directly managed by the CMS SI team, in charge of enforcing the global CMS resource provisioning and exploitation policies. A new configuration of this permanent cloud has been proposed in order to solve these shortcomings. A vacuum-like model, based on GlideinWMS pilot jobs joining the CMS CERN HTCondor Pool has been prototyped and successfully tested and deployed. This contribution will describe this redeployment work on the permanent cloud for an enhanced support to CMS offline computing, comparing the former and new models’ respective functionalities, along with the commissioning effort for the new setup.
The Super Tau Charm Facility (STCF) proposed in China is a new-generation electron–positron collider with center-of-mass energies covering 2-7 GeV and a peak luminosity of 5*10^34 cm^-2s^-1. The offline software of STCF (OSCAR) is developed to support the offline data processing, including detector simulation, reconstruction, calibration as well as physics analysis. To meet STCF’s specific requirements, OSCAR is designed and developed based on the SNiPER framework, a lightweight common software for HEP experiments. Besides the commonly used software such as Geant4 and ROOT, several state-of-art software and tools in the HEP community are incorporated as well, such as the Detector Description Toolkit (DD4hep), the plain-old-data I/O (Podio) and Intel Thread Building Blocks (TBB) etc.
This contribution will present the overall design of OSCAR, and in particular, the following topics will be highlighted.
1. The design of the Event Data Model based on Podio, and the implementation of the data management system, via the integration of Podio and SNiPER.
2. The parallelized data processing based on SNiPER and TBB, and in particular, the design of GlobalStore based on the Podio EventStore to support concurrent data access and data I/O.
3. The geometry management system based on DD4hep that provides consistent geometry for detector simulation, calibration, reconstruction and detector visualization.
4. Automated software validation system that supports validation at multiple levels ranging from unit test to physical validation.
Currently, OSCAR is fully functioning to facilitate the conceptual design of the STCF detector and the physics potential study. Meanwhile, OSCAR can also provide a potential solution for other lightweight HEP experiments as well.
We summarize the status of Deep Underground Neutrino Experiment (DUNE) software and computing development. We describe plans for the computing infrastructure needed to acquire, catalog, reconstruct, simulate and analyze the data from the DUNE experiment and its prototypes in pursuit of the experiment's physics goals of precision measurements of neutrino oscillation parameters, detection of astrophysical neutrinos, measurement of neutrino interaction properties and searches for physics beyond the Standard Model. In contrast to traditional HEP computational problems, DUNE's Liquid Argon TPC data consist of simple but very large (many GB) data objects which share many characteristics with astrophysical images. We have successfully reconstructed and simulated data from 4% prototype detector runs at CERN. The data volume from the full DUNE detector, when it starts commissioning late in this decade will present memory management challenges in conventional processing but significant opportunities to use advances in machine learning and pattern recognition as a frontier user of High Performance Computing facilities capable of massively parallel processing. Our goal is to develop infrastructure resources that are flexible and accessible enough to support creative software solutions as HEP computing evolves.
The Deep Underground Neutrino Experiment (DUNE) is a long-baseline experiment which aims to study neutrino oscillation and astroparticle physics. It will produce vast amounts of metadata, which describe the data coming from the read-out of the primary DUNE detectors. Various databases will make up the overall DB architecture for this metadata. ProtoDUNE at CERN is the largest existing prototype for DUNE and serves as a testing ground for - among other things - possible database solutions for DUNE.
The subset of all metadata that is accessed during offline data reconstruction and analysis is referred to as ‘conditions data’ and it is stored in a dedicated database. As offline data reconstruction and analysis will be deployed on HTC and HPC resources, conditions data is expected to be accessed at very high rates. It is therefore crucial to store it in a granularity that matches the expected access patterns allowing for extensive caching. This requires a good understanding of the sources and use cases of conditions data. This contribution will briefly summarize the database architecture deployed at ProtoDUNE and explain the various sources of conditions data. We will present how the conditions data is retrieved from the run conditions and beam database; and how, together with the conditions data from the Detector Control System (Slow Controls) and those needed for the calibration of a LArTPC, are put in a format to match the expected access patterns.
Data taking at the Large Hadron Collider (LHC) at CERN restarted in 2022. The CMS experiment relies on a distributed computing infrastructure based on WLCG (Worldwide LHC Computing Grid) to support the LHC Run 3 physics program. The CMS computing infrastructure is highly heterogeneous and relies on a set of centrally provided services, such as distributed workload management and data management, and computing resources hosted at almost 150 sites worldwide. Smooth data taking and processing requires all computing subsystems to be fully operational, and available computing and storage resources need to be continuously monitored. During the long shutdown between LHC Run 2 and Run 3, the CMS monitoring infrastructure has undergone major changes to increase the coverage of monitored applications and services, while becoming more sustainable and easier to operate and maintain. The used technologies are based on open-source solutions, either provided by the CERN IT department through the MONIT infrastructure, or managed by the CMS monitoring team. Monitoring applications for distributed workload management, submission infrastructure based on HTCondor, distributed data management, facilities have been ported from mostly custom-built applications to use common data flow and visualization services. Data are mostly stored in no-SQL databases and storage technologies such as ElasticSearch, VictoriaMetrics, InfluxDB and HDFS, and accessed either via programmatic APIs, Apache Spark or Sqoop jobs, or visualized preferentially using Grafana. Most CMS monitoring applications are deployed on Kubernetes clusters to minimize maintenance operations. In this contribution we present the full stack of CMS monitoring services and show how we leveraged the use of common technologies to cover a variety of monitoring applications and cope with the computing challenges of LHC Run 3.
Monitoring services play a crucial role in the day-to-day operation of distributed computing systems. The ATLAS experiment at LHC uses the production and distributed analysis workload management system (PanDA WMS), which allows a million computational jobs to run daily at over 170 computing centers of the WLCG and other opportunistic resources, utilizing 600k cores simultaneously on average. The BigPanDAmon system is an essential part of the monitoring infrastructure for the ATLAS experiment that provides a wide range of views from the top-level summaries to a single computational job and its logs. Over the past few years of the PanDA WMS advancement in the ATLAS experiment several new components were developed, such as Harvester, iDDS, Data Carousel, and Global Shares. Due to its modular architecture, BigPanDAmon naturally grew into a platform where the relevant data from all PanDA WMS components and accompanying services are accumulated and displayed in the form of interactive charts and tables. Moreover the system has been adopted by other experiments beyond HEP. In this paper we describe the evolution of the BigPanDAmon system, the development of new modules, and the integration process into other experiments.
The ALICE experiment at the CERN Large Hadron Collider relies on a massive, distributed Computing Grid for its data processing. The ALICE Computing Grid is built by combining a large number of individual computing sites distributed globally. These Grid sites are maintained by different institutions across the world and contribute thousands of worker nodes possessing different capabilities and configurations. Developing software for Grid operations that works on all nodes while harnessing the maximum capabilities offered by any given Grid site is challenging without advance knowledge of what capabilities each site offers. Site Sonar is an architecture-independent Grid infrastructure monitoring framework developed by the ALICE Grid team to monitor the infrastructure capabilities and configurations of worker nodes at sites across the ALICE Grid without the need to contact local site administrators. Site Sonar is a highly flexible and extensible framework that offers infrastructure metric collection without local agent installations at Grid sites. This paper introduces the Site Sonar Grid infrastructure monitoring framework and reports significant findings acquired about the ALICE Computing Grid using Site Sonar.
HammerCloud (HC) is a testing service and framework for continuous functional tests, on-demand large-scale stress tests, and performance benchmarks. It checks the computing resources and various components of distributed systems with realistic full-chain experiment workflows.
The HammerCloud software was initially developed in Python 2. After support for Python 2 was discontinued in 2020, migration to Python 3 became vital in order to fulfill the latest security standards and to use the new CERN Single Sign-On, which requires Python 3.
The current deployment setup based on RPMs allowed a stable deployment and secure maintenance over several years of operations for the ATLAS and CMS experiments. However, the current model is not flexible enough to support an agile and rapid development process. Therefore, we have decided to use a containerization solution, and switched to industry-standard technologies and processes. Having an "easy to spawn" instance of HC enables a more agile development cycle and easier deployment. With the help of such a containerized setup, CI/CD pipelines can be integrated into the automation process as an extra layer of verification.
A quick onboarding process for new team members and communities is essential,
as there is a lot of personnel rotation and a general lack of personpower. This is achieved with the container-based setup, as developers can now work locally with a quick turnaround without needing to set up a production-like environment first. These developments empower the whole community to bravely test and prototype new ideas and deliver new types of resources or workflows to our community.
Operational analytics is the direction of research related to the analysis of the current state of computing processes and the prediction of the future in order to anticipate imbalances and take timely measures to stabilize a complex system. There are two relevant areas in ATLAS Distributed Computing that are currently in the focus of studies: end-user physics analysis including the forecast of samples of data popularity among users, and ranking of WLCG centers for user analysis tasks. Studies in these areas are non-trivial and require detailed knowledge of all boundary conditions, which may be numerous in large-scale distributed computing infrastructures. Forecasts of data popularity are impossible without the categorization of user tasks by their types (data transformation or physics analysis), which do not always appear on the surface but may induce noise, which introduces significant distortions for predictive analysis. Ranking the WLCG resources is also a challenging task as it is necessary to find a balance between the workload of the resource, its performance, the waiting time for jobs on it, as well as the volume of jobs that it processes. This is especially difficult in a heterogeneous computing environment, where legacy resources are used along with modern high-performance machines. We will look at these areas of research in detail and discuss what tools and methods we use in our work, demonstrating the results that we already have. The difficulties we face and how we solve them will also be described.
For LHC Run3 the ALICE experiment software stack has been completely refactored, incorporating support for multicore job execution. The new multicore jobs spawn multiple processes and threads within the payload. Given that some of the deployed processes may be short-lived, accounting for their resource consumption presents a challenge. This article presents the newly developed methodology for payload execution monitoring, which correctly accounts for the resources used by all processes within the payload.
We also present a black box analysis of the new multicore experiment software framework tracing the used resources and system function calls issued by MonteCarlo simulation jobs. Multiple sources of overhead in the processes and threads lifecycle have thus been identified. This paper describes the tracing techniques and what solutions were implemented to address them. The analysis and subsequent improvements of the code have positively impacted the resource consumption and the overall turnaround time of the payloads with a notable 35% reduction in execution time for a reference production job. We also introduce how this methodology will be used to further improve the efficiency of our experiment software and what other optimization venues are currently being pursued.
The ATLAS experiment involves almost 6000 members from approximately 300 institutes spread all over the globe and more than 100 papers published every year. This dynamic environment brings some challenges such as how to ensure publication deadlines, communication between the groups involved, and the continuity of workflows. The solution found for those challenges was automation, which was achieved through the Glance project, more specifically through the Glance Analysis systems, developed to support the analysis and publications life cycle in 2010. Now, after twelve years, in order to satisfy the experiments’ most recent needs, the systems need code refactoring and database remodeling. The goal is to have only one system to accommodate all the analysis and publications workflows, the so-called ATLAS Publication Tracking system, an evolution of the current Analysis systems. This project includes a database remodeling that reflects the hierarchical relation between analyses and publications; a code base that supports non-linear workflows; the expansion of the current API so all the authorized ATLAS members can access ATLAS publication data programmatically; a service-oriented architecture for integration with external software, such as GitLab; the creation of an automatic test environment, which assures the quality of the systems on each update. The ATLAS Publication Tracking system is a long-term project being developed with an iterative and incremental approach, which ensures that the most valuable tools are implemented with priority while allowing a smooth transition between the old systems and the new one.
As the largest particle physics laboratory in the world, CERN has more than 17000 collaborators spread around the globe. ATLAS, one of CERN’s experiments, has around 6000 active members and 300 associate institutes, all of which must go through the standard registration and updating procedures within CERN’s HR (Foundation) database. Simultaneously, the ATLAS Glance project, among other functions, also has the same goal within the ATLAS context. At the time of its first development, no tools were available to allow Glance to write into the Foundation database, therefore the solution put into place was to duplicate data. This however proved to be inefficient as the databases grew over time. Information had to be constantly updated manually by the ATLAS Secretariat to keep members and institutes data (such as names, employment information and authorship status) coherent between databases. Today, equipped with new tools, the Glance system is about to change its relationship with Foundation: a sole source of truth for the data shall be determined, removing the duplication of information. This includes automating a series of internal processes so the ATLAS secretariat need not to manually intervene to keep both databases synchronized. For this, a workflow had to be developed so that the previous manual work could be successfully replaced considering the multitude of possible actions by the Secretariat. The remodeling of the current structure of the database, along with the refactoring of the code, shall also be required to establish an easy communication between the two systems. Finally, a number of tools developed on Foundation’s side (such as SQL procedures and APIs) have to be put in place to enable the writing and reading between databases.
The LHCb experiment is one of the 4 LHC experiments at CERN. With more than 1500 members and tens of thousands of assets, the Collaboration requires systems that allow the extraction of data from many databases according to some very specific criteria. In LHCb there are 4 production web applications responsible for managing members and institutes, tracking assets and their current status, presenting radiological information of the cavern and supporting the management of cables. A common requirement shared across all these systems is to allow searching information based on logic sentences. Therefore, in order to avoid rework, the Glance Search Library was created with the goal to provide components for applications to deploy frontend search interfaces capable of generating standardized queries based on users' input, and backend utility functions that compile such queries into a SQL clause. The Glance Search Library is split into 2 smaller libraries maintained in different GitLab repositories. The first one only contains Vue components and JavaScript modules and, in LHCb, it is included as a dependency of the SPAs. The second is a PHP Object-Oriented library, mainly used by REST APIs that are required to expose large amounts of data stored in their relational databases. This separation provides greater flexibility and more agile deployments. It also enables lighter applications with no graphical interface to build command line tools solely on top of the backend classes and predefined queries, for example.
The Glance project is responsible for over 20 systems across three CERN experiments: ALICE, ATLAS and LHCb. Students, engineers, physicists and technicians have been using systems designed and managed by Glance on a daily basis for over 20 years. In order to produce quality products continuously, considering internal stakeholder's ever-evolving requests, there is the need of standardization. The adoption of such a standard had to take into account not only future developments but also legacy systems of the three experiments. These systems were built as a monolith, which, as they scaled, became difficult to maintain due to its lack of documentation and use of technologies that were becoming obsolete. Migrating them to a new architecture would mean speeding up the development process, avoiding rework and integrating CERN systems widely. Since a lot of the core functionalities of the systems are shared between them, both on the frontend and on the backend, the architecture had to assure modularity and reusability. In this architecture, the principles behind Hexagonal Architecture are followed and the systems’ codebase is split into two applications: a JavaScript client and a REST backend server. The open-source framework Vue.js was chosen for the frontend. Its versatility, approachability and extended documentation made it the ideal tool for creating components that are reused throughout Glance applications. The backend uses PHP libraries created by the team to expose information through REST APIs both internally, allowing easier integration between the systems, and externally, introducing to users outside Glance information managed by the team.
The recent major upgrade of the ALICE Experiment at CERN’s Large Hadron Collider has been coupled with the development of a new Online-Offline computing system capable of interacting with a sustained input throughput of 3.5TB/s. To facilitate the control of the experiment, new web applications have been developed and deployed to be used 24 hours a day, 365 days a year in the control room and remotely by the subsystem experts and on-call support staff.
Over the past years, an exponential increase in number of exploits on applications vulnerabilities has been observed. This includes but it is not limited to malicious user input, DDoS, SQL Injection and Cross-Site Scripting attacks. Thus, the ALICE interfaces are being built using modern web technologies and a common library developed in-house which provides the core functionalities and building blocks for preventing vulnerabilities. This approach ensures a consolidated and secure environment towards maintaining data integrity and a straightforward non-malicious control of the experiment. This work showcases the tools and practices applied to enhance the application-level security and privacy needed for the experiment to be controlled and observed remotely. A report is also presented of incidents encountered during the first year of ALICE Run 3 operation.
CERN, as many large organizations, relies on multiple communication means for different use-cases and teams.
Email and mailing lists are the most popular ones, but more modern communications systems gain traction such as Mattermost and Push notifications.
On one end of the spectrum we have communication teams writing individual emails to users on a daily basis, which may be small targets, or in the order of thousands. On the other end, there are many automated tools and scripts which generate thousands of notifications daily, mostly in the form of emails.
As a consequence of the large amount of notifications received every day, for the users receiving them, it is challenging to control and keep track of where, how and when some information was received.
At the same time for those sending and maintaining the tools that deliver notifications, it is difficult to choose which targets to adopt (email, Mattermost, etc). Additionally it is difficult to please all users and take into account their preferences. Ultimately, across all those responsible for sending information, a lot of effort is spent on maintaining similar scripts and tools.
The CERN Notifications system aims at consolidating communication by providing a central place where notifications are created, maintained and distributed.
It allows to save efforts and costs by avoiding multiple parallel implementations of communication systems and their maintenance and details such as retry and failure mechanism, version updates, etc.
CERN Notifications allows not only optimising the flow for the multiple people and teams which are responsible for sending, but also empowers the target users by respecting their preferences: how, where and when they receive their notifications.
The system was designed to allow those who send information to focus on the the content and relevance of the communication without knowing the technical details of the many frameworks available to distribute information.
This paper describes the design and architecture of the CERN Notifications system and its components, how it was designed with a flexible and highly modular architecture which allows adding further device targets with little effort. Furthermore, it presents implementation details and the decisions behind those. And last but not least it describes the features that empower users to choose how to consume information send to them.
The primary physics goal of the Mu2e experiment requires reconstructing an isolated 105 MeV electron with better than 500 KeV/c momentum resolution. Mu2e uses a low-mass straw tube tracker, and a CsI crystal calorimeter, to reconstruct tracks.
In this paper, we present the design and performance of a track reconstruction algorithm optimized for Mu2e’s unusual requirements. The algorithm is based on the KinKal kinematic Kalman filter track fit package. KinKal supports multiple track parameterizations, including one optimized for looping tracks, such as Mu2e signal tracks, and others optimized for straight or slightly-curved tracks, such as the high-momentum (P>1 GeV/c) cosmic ray muons used to calibrate and align the Mu2e detectors. All KinKal track parameterizations include the track origin time, to correctly model correlations arising from measurements that couple time and space, such as the straw drift time or the calorimeter cluster time. KinKal employs magnetic field inhomogeneity and material effect correction algorithms with 10-4 fractional precision. The Mu2e fit uses Artificial Neural Net functions to discriminate background hits from signal hits, and to resolve the straw tube hit left-right ambiguity, while iterating the extended Kalman filter. The efficiency, accuracy, and precision of the Mu2e track reconstruction, as tested on detailed simulations of Mu2e data, will be presented.
Among the biggest computational challenges for High Energy Physics (HEP) experiments there are the increasingly larger datasets that are being collected, which often require correspondingly complex data analyses. In particular, the PDFs used for modeling the experimental data can have hundreds of free parameters. The optimization of such models involves a significant computational effort and a considerable amount of time, of the order of days, before reaching a result.
Medusa is a C++ application designed to perform physics data analyses of generic 4-body decays deploying massively parallel platforms (multicore CPUs and GPUs) on Linux systems. It relies on Hydra, a header-only library that provides a high-level and user-friendly interface for common algorithms used in HEP, abstracting away the complexities associated with the implementation of code for different massively parallel architectures.
Medusa has been tested through the measurement of the CP-violating phase phi_s in b-hadron decays exploiting the data collected by the LHCb experiment. By deploying such technologies as CUDA, TBB and OpenMP, Medusa accelerates the optimization of the full model, running over 500000 events, by factors 74 (multicore CPU) and 370 (GPU) in comparison with a non-parallelized program.
To accurately describe data, tuning the parameters of MC event Generators is essential. At first, experts performed tunings manually based on their sense of physics and goodness of fit. The software, Professor, made tuning more objective by employing polynomial surrogate functions to model the relationship between generator parameters and experimental observables (inner-loop optimization), then optimizing an objective function to obtain generator parameters (outer-loop optimization). Finally, Apprentice, a purely python-based tool, was developed to leverage High-Performance Computing and introduced rational approximation as an alternative surrogate function. However, none of these tuning methods includes MC systematic uncertainties. More importantly, the estimated uncertainties of tuned parameters are unreliable because the objective distribution does not match a chi-squared distribution, and one has to manually set a cutoff threshold on the objective function using educated guesses. In this work, we integrate the MC systematic uncertainties into the inner-loop optimization and outer-loop optimization. With our new method, we find that the objective function nicely follows the chi-square distribution; thus, the uncertainty of the tuned generator parameters is better quantified.
Performing a physics analysis of data from simulations of a high energy experiment requires the application of several common procedures, from obtaining and reading the data to producing detailed plots for interpretation. Implementing common procedures in a general analysis framework allows the analyzer to focus on the unique parts of their analysis. Over the past few years, EIC simulations have been performed using differing frameworks and data models; we thus developed epic-analysis, a common analysis framework to support all of them, allowing for comparison studies and cross checks while the design of the EIC continues to evolve. The reconstruction of kinematic variables is fundamental to several physics channels, including inclusive, semi-inclusive, and jet physics. epic-analysis includes many different kinematics reconstruction methods, ranging from using the scattered electron to machine learning methods, each of which produce the same set of kinematic variables needed for physics analysis. Since the number of variables is large, a multi-dimensionally binned analysis is also often employed. We thus developed adage, a novel graph-based data structure that not only associates data to their bins, but also stores and can execute user-specified algorithms on any lower dimensional subsets. This approach allows the analyzer to write analysis algorithms that are fully independent of the binning strategy, expediting the exploration of the high dimensional phase space. Finally, as part of the EPIC software stack, epic-analysis continuous integration tests can be triggered by upstream changes in the simulation or reconstruction. For example, this automation allows for the physics impact on a detector design change to be quickly assessed, completing the full feedback loop for EIC detector design.
Apache Spark is a distributed computing framework which can process very large datasets using large clusters of servers. Laurelin is a Java-based implementation of ROOT I/O which allows Spark to read and write ROOT files from common HEP storage systems without a dependency on the C++ implementation of ROOT. We discuss improvements due to the migration to an Arrow-based in-memory representation as well as detail the performance difference for analyses over data stored in either ROOT or the Parquet format.
HEPscore is a CPU benchmark, based on HEP applications, that the HEPiX Working Group is proposing as a replacement of the HEPSpec06 benchmark (HS06), which is currently used by the WLCG for procurement, computing resource requests and pledges, accounting and performance studies. At the CHEP 2019 conference, we presented the reasons for building a benchmark for the HEP community that is based on HEP applications instead of standard industrial benchmarks. In this contribution we describe the mix of HEP workloads selected to build HEPscore. We present the results of the 2022 campaign of measurements that studied the performance of eleven HEP applications on more than 70 unique computer systems on multiple WLCG sites. We provide an update on the current status of a HEPScore candidate and its deployment plans for 2023. We also discuss how HEPscore can be used to assess the power efficiency of different CPU architectures.
Creating new materials, discovering new drugs, and simulating systems are essential processes for research and innovation, and require substantial computational power. While many applications can be split into many smaller independent tasks, some cannot and may take hours or weeks to run to completion. To better manage those longer-running jobs, it would be desirable to stop them at any arbitrary point in time and later continue their computation on another compute resource; this is usually referred to as checkpointing. While some applications can manage checkpointing in a programmatic way, it would be preferable if the batch scheduling system could do that independently. In this paper, we evaluate the feasibility of using CRIU (Checkpoint Restore in Userspace), an open-source tool available for the GNU/Linux environment, with an emphasis on the OSG’s OSPool HTCondor setup. CRIU allows for checkpointing of the process state into a disk image, and is able to seamlessly deal with both open files and established network connections. Furthermore, it can be used for checkpointing of both traditional Linux processes and containerized workloads. The functionality seems adequate for many scenarios supported in the OSPool. although there are some limitations that prevent it from being usable in all circumstances.
CERN IT has consolidated all life-cycle management of its physical server fleet on the Ironic bare-metal API. From the initial registration upon the first boot, over the inventory checking, the burn-in and the benchmarking for acceptance, the provisioning to the end users and the repairs during its service, up to the retirement at the end of the servers’ life, all stages can be managed within this framework. In this presentation we will follow a server throughout its life in the CERN data center, and explain how this enables us to handle a fleet of 10’000 nodes in an automated and efficient way and to prepare for the new data centre which is currently being built. We will add the top challenges we faced when moving to this system, like the transparent adoption of already in-production nodes or after-the-fact inventory updates, and eventually round things up with our “GRUBsetta stone”, a collection of boot errors and what they really mean.
The University of Victoria (UVic) operates an Infrastructure-as-a-Service science cloud for Canadian researchers, and a WLCG T2 grid site for the ATLAS experiment at CERN. At first, these were two distinctly separate systems, but over time we have taken steps to migrate the T2 grid services to the cloud. This process has been significantly facilitated by basing our approach on Kubernetes, a versatile, robust, and very widely-adopted automation platform for orchestrating and managing containerized applications. Previous work exploited the batch capabilities of Kubernetes to run the computing jobs of the UVic ATLAS T2, and replace the conventional grid Computing Elements, by interfacing with the Harvester workload management system of the ATLAS experiment. However, the required functionality of a T2 site encompasses more than just batch computing. Likewise, the capabilities of Kubernetes extend far beyond running batch jobs, and include for example scheduling recurring tasks and hosting long-running externally-accessible services in a resilient way. We are now undertaking the more complex and challenging endeavour of adapting and migrating all remaining functions of the T2 site - such as APEL accounting and Squid caching proxies, but in particular the grid Storage Element - to cloud-native deployments on Kubernetes. We aim to enable fully comprehensive deployment of a complete ATLAS T2 site on a Kubernetes cluster via Helm charts, which will benefit the community by providing a streamlined and replicable way to install and configure an ATLAS site. We also describe our experience running a high-performance self-managed Kubernetes ATLAS T2 cluster at the scale of 8,000 CPU cores for the last 2 years, and compare with the conventional setup of grid services.
The ATLAS experiment at CERN is one of the largest scientific machines built to date and will have ever growing computing needs as the Large Hadron Collider collects an increasingly larger volume of data over the next 20 years. ATLAS is conducting R&D projects on Amazon and Google clouds as complementary resources for distributed computing, focusing on some of the key features of commercial clouds: lightweight operation, elasticity and availability of multiple chip architectures.
The proof of concept phases have concluded with the cloud-native, vendor-agnostic integration with the experiment’s data and workload management frameworks. Google has been used to evaluate elastic batch computing, ramping up ephemeral clusters of up to O(100k) cores to process tasks requiring quick turnaround. Amazon cloud has been exploited for the successful physics validation of the Athena simulation software on ARM processors.
We have also set up an interactive facility for physics analysis allowing end-users to spin up private, on-demand clusters for parallel computing with up to 4000 cores, or run GPU enabled notebooks and jobs for machine learning applications.
The success of the proof of concept phases has led to the extension of the Google cloud project, where ATLAS will study the total cost of ownership of a production cloud site during 15 months with 10k cores on average, fully integrated with distributed grid computing resources and continue the R&D projects.
An all-inclusive analysis of costs for on-premises and public cloud-based solutions to handle the bulk of HEP computing requirements shows that dedicated on-premises deployments are still the most cost-effective. Since the advent of public cloud services, the HEP community has engaged in multiple proofs of concept to study the technical viability of using cloud resources; however, the financial viability of using cloud resources for HEP computing and storage is of greater importance. We present the results of a study comparing the cost of providing computing resources ina public cloud and a comprehensive estimate for the cost of an on-premises solution for HEP computing. Like previous studies, the fundamental conclusion is that for the bulk of HEP computing needs, on premises is significantly more cost effective than public clouds.
Among liquid argon time projection chamber (LArTPC) experiments MicroBooNE is the one that continually took physics data for the longest time (2015-2021), and represents the state of the art for reconstruction and analysis with this detector. Recently published analyses include oscillation physics results, searches for anomalies and other BSM signatures, and cross section measurements. LArTPC detectors are being used in current experiments such as ICARUS and SBND, and being planned for future experiments such as DUNE.
MicroBooNE has recently released to the public two of its data sets, with the goal of enabling collaborative software developments with other LArTPC experiments and with AI or computing experts. These datasets simulate neutrino interactions on top of off-beam data, which include cosmic ray background and noise. The datasets are released in two formats: the native artroot format used internally by the collaboration and familiar to other LArTPC experts, and the HDF5 format which contains reduced and simplified content and is suitable for usage by the broader community.
This contribution presents the open data sets, discusses their motivation, the technical implementation, and the extensive documentation - all inspired by FAIR principles. Finally, opportunities for collaborations are discussed.
The ATLAS Open Data project aims to deliver open-access resources for education and outreach in High Energy Physics using real data recorded by the ATLAS detector. The Open Data release so far has resulted in the release of a substantial amount of data from 8 TeV and 13 TeV collisions in an easily-accessible format and supported by dedicated software and documentation to allow its fruitful use by users at a range of experience levels. To maximise the value of the data, software, and documentation resources provided ATLAS has developed initiatives and promotes stakeholder engagement in the creation of these materials through on-site and remote training schemes such as high-school work experience and summer schools programs, university projects and PhDs qualification tasks. We present examples of how multiple training programs inside and outside CERN have helped and continue to help development the ATLAS Open Data project, lessons learnt, impacts, and future goals.
The BaBar experiment collected electron-positron collisions at the SLAC National Accelerator Laboratory from 1999-2008. Although data taking has stopped 15 years ago, the collaboration is still actively doing data analyses, publishing results, and giving presentations at international conferences. Special considerations were needed to do analyses using a computing environment that was developed more than a decade ago. A framework is required that preserves the data, data access, and the capability of doing analyses using a well defined and preserved environment. Also, BaBar’s support by SLAC National Accelerator Laboratory, the place where the experiment took place, ended at the beginning of 2021. Fortunately, the HEP Research Computing group at the University of Victoria (UVic), Canada, offered to be the new home for the main BaBar computing infrastructure, GridKa offered to host all data for access by analyses running at UVic, and CERN and IN2P3 offered to store a backup of all data. In this talk, we will present what was done at BaBar to preserve the data and analysis capabilities and needed to move the whole computing infrastructure, including collaboration tools and data files, away from the SLAC National Accelerator Laboratory. It will be shown how BaBar preserved the ability to continue to do data analyses and also have a working collaboration tools infrastructure. The talk will detail what was needed to move the different bits of an experiment’s computing infrastructure to a new home, access the data from a different location, and how to move to more modern systems where older infrastructure could not be used anymore. The talk will be focused on BaBar’s experience with such a big change in its infrastructure and what was learned from it, which may be useful to other experiments which are interested in long term analysis support and data preservation in general.
In this paper we discuss the CMS open data publishing workflows, summarising experience with eight releases of CMS open data on the CERN Open Data portal since its initial launch in 2014. We present the recent enhancements of data curation procedures, including (i) mining information about collision and simulated datasets with accompanying generation parameters and processing configuration files, (ii) building an API service covering information related to luminosity, run number ranges and other contextual dataset information, as well as (iii) configuring the CERN Open Data storage area as a Rucio endpoint that manages over four petabytes of released CMS open data and serves as a WLCG Tier 3 site to simplify data transfers. Finally, we discuss the latest CMS content released as open data (completed Run 1 data, first samples from Run 2 data) and the associated runnable analysis examples demonstrating its use in containerised data analysis workflows. We conclude by a short list of lessons learnt as well as general recommendations to facilitate upcoming releases of Run 2 data.
Making the large datasets collected at the LHC accessible to the public is a considerable challenge given the complexity and volume of data. Yet to harness the full scientific potential of the facility, it is essential to enable meaningful access to the data by the broadest physics community possible. Here we present an application, the LHCb Ntuple Wizard, which leverages the existing computing infrastructure available to the LHCb collaboration in order to enable third-party users to request derived data samples in the same format used in LHCb physics analysis. An intuitive user interface built with the React-JS framework allows for the discovery of available particle or decay channel datasets through a flexible search engine, and guides the user through the request for producing Ntuples: collections of N particle or decay candidates, each candidate corresponding to a tuple cataloguing measured quantities chosen by the user. Necessary documentation and metadata is rendered in the appropriate context within the application to guide the user through the core components of the application, dataset discovery and Ntuple configuration. In the Ntuple configuration step, decays are represented by an interactive directed acyclic graph where the nodes depict (intermediate) particles and the edges indicate a mother-daughter relationship, each graph corresponding to the configuration of a single Ntuple. Standard tools used at LHCb for saving measured or derived quantities to Ntuples can be applied to specific nodes, or collections of nodes, allowing for customization of information saved about the various subsamples used to build the physics candidate (e.g. various particles in a decay). Ntuples in this context are saved as simply structured ROOT files containing the catalogued quantities, requiring no external usage of the LHCb software stack. Issues of computer security and access control arising from offering this service are addressed by keeping the configuration output of the Ntuple Wizard in a pure data structure format (YAML) to be interpreted by internal parsers. The parsers produce the necessary Python scripts for steering the Ntuple production job, the output of which will be delivered to the CERN Open Data Portal.
Research in high energy physics (HEP) heavily relies on domain-specific digital contents. We reflect on the interpretation of principles of Findability, Accessibility, Interoperability, and Reusability (FAIR) in preservation and distribution of such digital objects. As a case study, we demonstrate the implementation of an end-to-end support infrastructure for preserving and accessing Universal FeynRules Output (UFO) models guided by the FAIR principles. UFO models are custom-made python libraries used by the HEP community for Monte Carlo simulation of collider physics events. Our framework provides simple but robust tools to preserve and access the UFO models and corresponding metadata in accordance with the FAIR principles.
Significant progress has been made in applying graph neural networks (GNNs) and other geometric ML ideas to the track reconstruction problem. State-of-the-art results are obtained using approaches such as the Exatrkx pipeline, which currently applies separate edge construction, classification and segmentation stages. One can also treat the problem as an object condensation task, and cluster hits into tracks in a single stage, such as in the GravNet architecture. However, condensation with such an architecture may still require non-differentiable operations. In this work, we extend the ideas of geometric attention applied in the GravNetNorm architecture to the task of fully geometric (and therefore fully differentiable) end-to-end track reconstruction in one step.
To realize this goal, we introduce a novel condensation loss function called Influencer Loss, which allows an embedded representation of tracks to be learned in tandem with the most representative hit(s) in each track. This loss has global optima that formally match the task of track reconstruction, namely smooth condensation of tracks to a single point, and we demonstrate this empirically on the TrackML dataset. We combine the Influencer approach with geometric attention to build an Influencer pooling operation, that allows a GNN to learn a hierarchy of hits-to-tracks in a fully differentiable fashion. Finally, we show how these ideas naturally lead to a representation of collision point clouds that can be used for downstream predictive and generative tasks.
Recent work has demonstrated that graph neural networks (GNNs) trained for charged particle tracking can match the performance of traditional algorithms while improving scalability. Most approaches are based on the edge classification paradigm, wherein tracker hits are connected by edges, and a GNN is trained to prune edges, resulting in a collection of connected components representing tracks. These connected components are usually collected by a clustering algorithm and the resulting hit clusters are passed to downstream modules that may assess track quality or fit track parameters.
In this work, we consider an alternative approach based on object condensation (OC), a multi-objective learning framework designed to cluster points belonging to an arbitrary number of objects, in this context tracks, and regress the properties of each object. We demonstrate that object condensation shows promising results in various simplified scenarios and present a modular and extensible open-source implementation that allows us to efficiently train and evaluate the performance of various OC architectures and related approaches.
Track reconstruction is one of the most important and challenging tasks in the offline data processing of collider experiments. For the BESIII detector working in the tau-charm energy region, plenty of efforts were made previously to improve the tracking performance with traditional methods, such as template matching and Hough transform etc. However, for difficult tracking tasks, such as the tracking of low momentum tracks, tracks from secondary vertices and tracks with high noise level, there is still large room for improvement.
In this contribution, we demonstrate a novel tracking algorithm based on machine learning method. In this method, a hit pattern map representing the connectivity between drift cells is established using an enormous MC sample, based on which we design an optimal method of graph construction, then an edge-classifying Graph Neural Network is trained to distinguish the hit-on-track from noise hits. Finally, a clustering method based on DBSCAN is developed to cluster hits from multiple tracks. Track fitting algorithm based on GENFIT is also studied to obtain the track parameters, where deterministic annealing filter are implemented to deal with ambiguities and potential noises.
The preliminary results on BESIII MC sample presents promising performance, showing potential to apply this method to other trackers based on drift chamber as well, such as the CEPC and STCF detectors under pre-study.
Particle track reconstruction is the most computationally intensive process in nuclear physics experiments.
Traditional algorithms use a combinatorial approach that exhaustively tests track measurements (hits) to
identify those that form an actual particle trajectory. In this article we describe the development of machine
learning models that assist the tracking algorithm by identifying valid track candidates from the measurement
("hits") in drift chambers. Several types of machine learning models were tested, including: Convolutional Neural Networks (CNN),
Multi-Layer Perceptron (MLP), Extremely Randomized Trees (ERT) and Recurrent Neural Networks (RNN).
As a result of this work the CLAS12 tracking efficiency increased by ~15% for single particle tracking, and
20%-40% gained efficiency in multi-particle final states. The tracking code also increased in speed by 35%.
Data from the LHC detectors are not easily represented using regular data structures. These detectors are comprised of several species of subdetectors and therefore produce heterogeneous data. LHC detectors are granular by design so that nearby particles may be distinguished. As a consequence, LHC data are sparse, in that many detector channels are not active during a given collision event. Graphs offer a flexible and efficient alternative to rectilinear data structures for representing LHC data. Accordingly, graph-based machine learning algorithms are becoming increasingly popular for a large number of LHC physics tasks [1]. This popularity, and the corresponding potential for substantial increase in physics output, are illustrated on the cover of a recent issue [2] of the CERN Courier magazine.
The graphs used in almost all practical applications at the LHC so far are homogeneous, i.e. each node is assigned the same features, and each edge is assigned the same features [3]. In other words, the power of graphs to represent sparse data has been exploited in applications for the LHC, but the potential of graphs to represent heterogeneous data has not. The pink graph on the cover of the CERN Courier [2] can be seen as an illustration of this limitation: all nodes are pink, regardless of their position in the detector.
We present novel fully-heterogeneous GNN designs and apply them to simulated data from a tracking detector that resembles the trackers that will be used at the HL-LHC. It contains a pixel subsystem that provides 3D hits and a strip subsystem that provides 2D hits. Our designs aim at solving the degraded performance that is observed in the strip detector in the first GNN-based tracking studies presented by the ATLAS Collaboration [4].
[1] Shlomi, Battaglia and Vlimant, “Graph neural networks in particle physics”, Mach. Learn.: Sci. Technol. 2 021001 (2021), https://doi.org/10.1088/2632-2153/abbf9a
[2] https://cerncourier.com/wp-content/uploads/2021/08/CERNCourier2021SepOct-digitaledition.pdf
[3] Sometimes quasi-heterogeneous node representations are used: the same data structure is assigned to each node, but different parts of it are zeroed out in subsets of nodes.
[4] http://cds.cern.ch/record/2815578
We have been studying the use of deep neural networks (DNNs) to identify and locate primary vertices (PVs) in proton-proton collisions at the LHC. Earlier work focused on finding primary vertices in simulated LHCb data using a hybrid approach that started with kernel density estimators (KDEs) derived from the ensemble of charged track parameters heuristically and predicted “target histogram” proxies from which PV positions are extracted. We have recently demonstrated that using a UNet architecture performs indistinguishably from a “flat” convolutional neural network model and that “quantization”, using FP16 rather than FP32 arithmetic, degrades its performance minimally. We have demonstrated that the KDE-to-hists algorithm developed for LHCb data can be adapted to ATLAS and ACTS data. Within ATLAS/ACTS, the algorithm has been validated against the standard vertex finder algorithm.
We have developed an “end-to-end” tracks-to-hists DNN that predicts target histograms directly from track parameters using simulated LHCb data that provides better performance (a lower false positive rate for the same high efficiency) than the best KDE-to-hists model studied. This DNN also provides better efficiency than the default heuristic algorithm for the same low false positive rate. We are currently instantiating the end-to-end tracks-to-hists DNN within the software stack for Allen, LHCb’s GPU-resident, first-level software trigger.
The CMS experiment at CERN accelerates several stages of its online reconstruction by making use of GPU resources at its High Level Trigger (HLT) farm for LHC Run 3. Additionally, during the past years, computing resources available to the experiment for performing offline reconstruction, such as Tier-1 and Tier-2 sites, have also started to integrate accelerators into their systems. In order to make efficient use of these heterogeneous platforms, it is essential to adapt both the CMS production system and the CMSSW reconstruction code to make use of GPUs. Ths CMSSW offline reconstruction can now partially run on GPUs, inheriting from the work done at the HLT. Parts of the production systems infrastructure have also been adapted to successfully map, schedule and run the available GPU-enabled workflows on different sites across the computing grid. This talk will describe the process of commissioning GPU-enabled CMSSW workflows through the production system and will present first results from the deployment of GPU-enabled offline reconstruction workflows.
The LHCb experiment uses a triggerless readout system where its first stage (HLT1) is implemented on GPU cards. The full LHC event rate of 30 MHz is reduced to 1 MHz using efficient parallellisation techniques in order to meet throughput requirements. The GPU cards are hosted in the same servers as the FPGA cards receiving the detector data which reduces the network to a minimum. In this talk, the commissioning of this heterogeneous architecture using the first Run 3 data is presented.
The software based High Level Trigger (HLT) of CMS reduces the data readout rate from 100kHz (obtained from Level 1 trigger) to around 2kHz. It makes use of all detector subsystems and runs a streamlined version of CMS reconstruction. Run-1 and Run-2 of the LHC saw the reconstruction algorithm run on a CPU farm (~30000 CPUs in 2018). But the need to have increased computational power as we approach the high luminosity phase of LHC demands the use of Graphical Processing Units (GPUs) to reign in the cost, size and power consumption of the HLT farm. Parallelization of the reconstruction algorithms, on top of the multi-threading functionality introduced in Run2, allowed parts of HCAL, ECAL and pixel reconstruction to be offloaded to NVIDIA GPUs. In order to ensure the reproducibility of physics results on any machine, the HLT configuration was designed to run seamlessly with and without GPUs, that is, the algorithms were automatically offloaded to a GPU when one was available, and otherwise fell back to running on the CPU. This contribution will describe the development of GPU-based algorithms for the HLT and the challenges they presented, along with the comprehensive validation and commissioning activity undertaken by CMS to ensure the successful operations of the new HLT farm.
To better understand experimental conditions and performances of the Large Hadron Collider (LHC), CERN experiments execute tens of thousands of loosely-coupled Monte Carlo simulation workflows per hour on hundreds of thousands - small to mid-size - distributed computing resources federated by the Worldwide LHC Computing Grid (WLCG). While this approach has been reliable during the first LHC runs, WLCG will be limited to meet future computing needs. In the meantime, High-Performance Computing resources, and more specifically supercomputers, offers a significant additional amount of computing resources but they also come with higher integration challenges.
This state-of-practice paper outlines years of integration of LHCb simulation workflows on several supercomputers. The main contributions of this paper are: (i) an extensive description of the gap to address to run High-Energy Physics Monte Carlo simulation workflows on supercomputers; (ii) various methods and proposals to submit High-Throughput Computing workflows and maximize the use of allocated CPU resources; (iii) a comprehensive analysis of LHCb production workflows running on diverse supercomputers.
FastCaloSim is a parameterized simulation of the particle energy response and of the energy distribution in the ATLAS calorimeter. It is a relatively small and self-contained package with massive inherent parallelism and captures the essence of GPU offloading via important operations like data transfer, memory initialization, floating point operations, and reduction. Thus, it was identified as a good testbed for evaluating the performance and ease
of portability of programming models. As a part of the HEP Center for Computational Excellence project, FastCaloSim had been ported to GPU using CUDA, Kokkos, SYCL, and similar ports for std::parallel, Alpaka, and OpenMP are being developed.
In this presentation, we will give an overview of the progress made with the std::parallel, Alpaka and OpenMP implementations of FastCaloSim. In particular, performance benchmarks on NVIDIA
GPUs, AMD GPUs and multicore CPUs will be reported for each programming model wherever available, along with the comparison of pros and cons of each approach.
The CMS experiment started to utilize Graphics Processing Units (GPU) to accelerate the online reconstruction and event selection running on its High Level Trigger (HLT) farm in the 2022 data taking period. The projections of the HLT farm to the High-Luminosity LHC foresee a significant use of compute accelerators in the LHC Run 4 and onwards in order to keep the cost, size, and power budget of the farm under control. This direction of leveraging compute accelerators has synergies with the increasing use of HPC resources in HEP computing, as HPC machines are employing more and more compute accelerators that are predominantly GPUs today. In this work we review the features developed for the CMS data processing framework, CMSSW, to support the effective utilization of both compute accelerators and many-core CPUs within a highly concurrent task-based framework. We measure the impact of various design choices for the scheduling of heterogeneous algorithms on the event processing throughput, using the Run-3 HLT application as a realistic use case.
The development of an LHC physics analysis involves numerous investigations that require the repeated processing of terabytes of measured and simulated data. Thus, a rapid processing turnaround is beneficial to the scientific process. We identified two bottlenecks in analysis independent algorithms and developed the following solutions.
First, inputs are now cached on individual SSD caches of each worker node. Here, cache efficiency and longevity is increased by a cache aware workload scheduling algorithm. Additionally, the algorithm is resilient against changes in workload composition and worker node allocation.
Second, the overall throughput is increased through tailored resource allocation, thus maximizing utilization. For this, the result aggregation, in particular of histograms, and the DNN evaluation are transparently offloaded to dedicated resources satisfying their unique demands. Consequently, the resource needs are homogenized for the primary workload.
Using these measures, a full-fledged LHC Run 2 analysis can be reprocessed from scratch within a few days on a small institute cluster of about 200 logical cores. The individual analysis parts, which are often repeated during development and debugging, have their runtime reduced from hours to minutes, with measured speed ups of up to 1490%. Finally, all these improvements readily carry over to other analyses within the same environment.
Rucio is a Data Management software that has become a de-facto standard in the HEP community and beyond. It allows the management of large volumes of data over their full lifecycle. The Belle II experiment located at KEK (Japan) recently moved to Rucio to manage its data over the coming decade (O(10) PB/year). In addition to its Data Management functionalities, Rucio also provides support for storing generic metadata. Rucio metadata already provides accurate accounting of the data stored all over the sites serving Belle II. Annotating files with generic metadata opens up possibilities for finer-grained metadata query support.
We will first introduce some of the new developments aimed at providing good performance that were done to cover Belle II use-cases like bulk insert methods, metadata inheritance, etc. We will then describe the various tests performed to validate Rucio generic metadata at Belle II scale (O(100M) files), detailing the import and performance tests that were made.
The ATLAS experiment is preparing a major change in the conditions data infrastructure in view of Run4 In this presentation we will expose the main motivations for the new design (called CREST for Conditions-REST), the ongoing changes in the DB architecture and present the developments for the deployment of the new system. The main goal is to setup a parallel infrastructure for full scale testing before the end of Run3.
The ALICE experiment at CERN has undergone a substantial detector, readout and software upgrade for the LHC Run3. A signature part of the upgrade is the triggerless detector readout, which necessitates a real time lossy data compression from 1.1TB/s to 100GB/s performed on a GPU/CPU cluster of 250 nodes. To perform this compression, a significant part of the software, which traditionally is considered off-line, was moved to the front-end of the experiment data acquisition system, for example the detector tracking. This is the case also for the various configuration and conditions databases of the experiment, which are now replaced with a single homogeneous service, serving both the real-time compression, online data quality checks and the subsequent secondary data passes, Monte-Carlo simulation and data analysis.
The new service is called CCDB (for Calibration and Conditions Database). It receives, stores and distributes objects created from online detector calibration tasks and control systems, as well as objects created by offline workflows, using a homogeneous and universal metadata annotation schema, distributes them in real time to the Online cluster and replicates all content on Grid storage elements for Grid jobs or by collaboration members. The access to the metadata and objects is done via a REST API and a ROOT-based C++ client interface which streamlines the interaction with this service from compiled code while plain curl command line calls are a simple access alternative.
In this paper we will present the architecture and implementation details of the components that manage frequent updates of objects with millisecond-resolution intervals of validity and how we have achieved an independent operation of the Online cluster while also making all objects available to Grid computing nodes.
The HSF Conditions Databases activity is a forum for cross-experiment discussions hoping for as broad a participation as possible. It grew out of the HSF Community White Paper work to study conditions data access, where experts from ATLAS, Belle II, and CMS converged on a common language and proposed a schema that represents best practice. The focus of the HSF work is the most difficult use case, specifically the subset of non-event data that are needed for distributed computing resources to process event data with access rates of up to 10k Hz. Following discussions with a broader community, including NP as well as HEP experiments, a core set of use cases, functionality and behaviour was defined with the aim to describe a core Conditions Database API. This contribution will describe the reference implementation of both the conditions database service and the client which together encapsulate HSF best practice conditions data handling.
Django was chosen for the service implementation, which uses an ORM instead of the direct use of SQL. The simple relational database schema to organise conditions data is implemented in PostgreSQL. The task of storing conditions data payloads themselves is outsourced to any POSIX-compliant filesystem, allowing for transparent relocation and redundancy. Crucially this design provides a clear separation between retrieving the metadata describing which conditions data are needed for a data processing job, and retrieving the actual payloads from storage. The deployment using helm on OKD will be described together with scaling tests and operations experience from the sPHENIX experiment running many 10k cores at BNL.
The ATLAS EventIndex is a global catalogue of the events collected, processed or generated by the ATLAS experiment. The system was upgraded in advance of LHC Run 3, with a migration of the Run 1 and Run 2 data from HDFS MapFiles to HBase tables with a Phoenix interface. The frameworks for testing functionality and performance of the new system have been developed. There are two types of tests running. First, the functional test that must check the correct functioning of the import chain. These tests run event picking over a random set of recently imported data to see if the data have been imported correctly, and can be accessed by both the CLI and the PanDA client. The second, the performance test, generates event lookup queries on sets of the EventIndex data and measures the response times. These tests enable studies of the response time dependence on the amount of requested data, and data sample type and size. Both types of tests run regularly on the existing system. The results of the regular tests as well as the statuses of the main EventIndex sub-systems (services health, loaders status, filesystem usage, etc.) are sent to InfluxDB in JSON format via HTTP requests and are displayed on Grafana monitoring dashboards. In case (part of) the system misbehaves or becomes unresponsive, alarms are raised by the monitoring system.
The CMS experiment at CERN incorporates one of the highest throughput Data Acquisition (DAQ) systems in High-Energy Physics. Its network throughput will further increase by over an order of magnitude at the High-Luminosity LHC.
The current Run 3 CMS Event Builder receives all the fragments of Level-1 trigger accepted events from the front-end electronics (740 data streams from the CMS subdetectors) and assembles them into complete 2 MB events at a rate of 100 kHz, with a throughput of 1.6 Tbit/s. Its output is handed over to the High Level Trigger (HLT), which runs in a farm consisting of approximately 200 computers equipped with general-purpose GPUs. The HLT selects interesting events at a rate of several kHz. The CMS DAQ will undergo a full upgrade prior to the start of the HL-LHC operation in 2029. The DAQ readout, network, and compute hardware will be entirely replaced to cope with a maximum input rate of 750 kHz and a nominal event size of 8.4 MB.
As with the current system, the Phase-2 event builder will consist of commercial off-the-shelf compute elements interconnected by a high-performance switched network in an all-to-all fashion. The switched network will have to handle an average throughput of about 50 Tb/s. To cope with the increased Level-1 rate, data fragments from individual Level-1 accepts corresponding to one LHC beam revolution (LHC orbit) will be aggregated into "orbit fragments" in the DAQ custom readout electronics. It is these orbit fragments that will then be further aggregated into full orbit data blocks, thus allowing the event builder protocol to work at a constant message rate of about 11 kHz, avoiding excessive message overheads. The final event building will then be delegated to the HLT processes, working each on individual orbit blocks.
To accommodate this new concept of "orbit building", the event builder software components will be entirely redesigned. In this work the key new features of the Phase-2 "event" builder are discussed. A study of new software solutions for the Phase-2 Event Builder and preliminary test benchmarks are presented with related performance results.
The ATLAS experiment Data Acquisition (DAQ) system will be extensively upgraded to fully exploit the High-Luminosity LHC (HL-LHC) upgrade, allowing it to record data at unprecedented rates. The detector will be read out at 1 MHz generating over 5 TB/s of data. This design poses significant challenges for the Ethernet-based network as it will be required to transport 20 times more data than during Run 3. The increased data rate, data sizes, and the number of servers will exacerbate the TCP incast effect observed in the past, which makes it impossible to fully exploit the capabilities of the network and limits the performance of the processing farm.
We present exhaustive and systematic experiments to define buffer requirements in network equipment to minimise the effects of TCP Incast and reduce the impact on the processing applications. Three switch models were stress-tested using DAQ traffic patterns in a test environment at approximately 10% scale of the expected HL-LHC DAQ system size.
As the HL-LHC system's desired hardware is not currently available and the lab size is considerably smaller, tests aim to project buffer requirements with different parameters. Different solutions are analysed, comparing software-based and network hardware cost-to-performance ratios to determine the most effective option to mitigate the impact of TCP incast.
The results of these evaluations will contribute to the decision-making process of acquiring network hardware for the HL-LHC DAQ.
To achieve better computational efficiency and exploit a wider range of computing resources, the CMS software framework (CMSSW) has been extended to offload part of the physics reconstruction to NVIDIA GPUs, while the support for AMD and Intel GPUs is under development. To avoid the need to write, validate and maintain a separate implementation of the reconstruction algorithms for each back-end, CMS decided to adopt a performance portability framework. After evaluating different alternative, it was decided to adopt Alpaka as the solution for Run-3.
Alpaka (Abstraction Library for Parallel Kernel Acceleration) is a header-only C++ library that provides performance portability across different back-ends, abstracting the underlying levels of parallelism. It supports serial and parallel execution on CPUs, and extremely parallel execution on GPUs.
This contribution will show how Alpaka is used inside CMSSW to write a single code base; to use different toolchains to build the code for each supported back-end, and link them into a single application; and to select the best back-end at runtime. It will highlight how the alpaka-based implementation achieves near-native performance, and will conclude discussing the plans to support additional back-ends.
The original HLT framework used in the Belle II experiment was formaly upgraded replacing the old IPC based ring buffer with the ZeroMQ data transport to overcome the unexpected IPC locking problem. The new framework has been working stably in the beam run so far, but it lacks the capability to recover the processing fault without stopping the on-going data taking. In addition, the compatibility with the offline framework (basf2) was lost which was maintained in the original.
In order to solve these, an improved core processing framework is developed based on basf2 running on each of worker servers, while keeping the existing ZeroMQ data transport between the servers unchanged. The new core framework is implemented with a lock-free 1-to-N and N-to-1 data transport using ZeroMQ utilizing the IPC socket so that it keeps a 100% compatibility with the original ring-buffer based offline framework. When a processing fault occurs, the affected currently processing event is salvaged from the input buffer and sent directly to the output using ZeroMQ broadcast. The terminated process is automatically restarted without stopping data taking.
This contribution describes the detail of the improved Belle II HLT frameowrk with the result of the performance test in the real Belle II DAQ data flow.
The Deep Underground Neutrino Experiment (DUNE) is a next generation long-baseline neutrino experiment based in the USA which is expected to start taking data in 2029. DUNE aims to precisely measure neutrino oscillation parameters by detecting neutrinos from the LBNF beamline (Fermilab) at the Far Detector, 1300 kilometres away, in South Dakota. The Far Detector will consist of four cryogenic Liquid Argon Time Projection Chamber (LArTPC) detectors of 17kT, each producing more than 1 TB/s of data. The main requirements for the data acquisition (DAQ) system are the ability to run continuously for extended periods of time, with a 99% uptime requirement, and the functionality to record beam neutrinos and low energy neutrinos from the explosion of a neighbouring supernova, should one occur during the lifetime of the experiment. The key challenges are the high data rates that the detectors generate and the deep underground environment, which places constraints on power and space. To overcome these challenges, the DUNE experiment plans to use a highly efficient C++ software suite and a server farm of about 110 nodes continuously running about two hundred processes located close to the detector, 1.5 miles underground. Thirty nodes will be at the surface and will run around two hundred processes simultaneously. DUNE is studying the use the Kubernetes framework to distribute containerised workloads and take advantage of its resource definitions and high uptime services to run the DAQ system. Progress in deploying these systems at the CERN neutrino platform on the prototype DUNE experiments (ProtoDUNE) were also made.
Large-scale research facilities are becoming prevalent in the modern scientific landscape. One of these facilities' primary responsibilities is to make sure that users can process and analysis measurement data for publication. To allow for barrier-less access to those highly complex experiments, almost all beamlines require fast feedback capable of manipulating and visualizing data online to offer convenience for the decision process of the experimental strategy. And recently, the advent of beamlines at fourth-generation synchrotron sources and high resolution with high sample rate detector has made significant progress that pushes the demand for computing resources to the edge of current workstation capabilities. On top of this, most synchrotron light sources have shifted to prolonged remote operation because of the outbreak of a global pandemic, with the need for remote access to the online instrumental system during the operation. Another issue is the vast data volume produced by specific experiments makes it difficult for users to create local data copies. In this case, on-site data analysis services are necessary both during and after experiments.
Some state-of-the-art experimental techniques, such as phase-contrast tomography and ptychography approaches, will be deployed. However, it poses a critical problem of integrating this algorithmic development into a novel computing environment used in the experimental workflow. The solution requires collaboration with the user research groups, instrument scientists and computational scientists. A unified software platform that provides an integrated working environment with generic functional modules and services is necessary to meet these requirements. Scientists can work on their ideas, implement the prototype and check the results following some conventions without dealing with the technical details and the migration between different HPC environments. Thus, one of the vital considerations is integrating extensions into the software in a flexible and configurable way. Another challenge resides in the interactions between instrumental sub-systems, such as control system, data acquisition system, computing infrastructures, data management system, data storage system, and so on, which can be quite complicated.
In this paper, we propose a platform named Daisy for integration and automation across services and tools, which ties together existing computing infrastructure and state-of-the-art algorithms. With modular architecture, it comprises loosely coupled algorithm components that communicate over the heterogeneous in-memory data store and scales horizontally to deliver automation at scale based on Kubernetes. The applications for the different scientific domains of HEPS developed based on the platform will also be introduced.
EvtGen is a simulation generator specialized for decays of heavy hadrons. Since its early development in the 90’s, the generator has been extensively used and has become today an essential tool for heavy-flavour physics analyses. Throughout this time, its source code has remained mostly unchanged, except for additions of new decay models. In view of the upcoming boom of multi-threaded processing, we have launched a modernization campaign with the chief goal of making EvtGen thread safe. This talk will cover the challenges encountered in this endeavour and the milestones reached so far.
The upgrade of the Large Hadron Collider (LHC) is going well, during next decade we will face the ten-fold increase in experimental data. The application of state-of-the-art detectors and data acquisition systems requires high-performance simulation support, which even more demanding in case of heavy ion collisions. Our basic aim was to develop a Monte-Carlo simulation code for heavy ion collisions (but applicable for proton-proton collisions, as well), which can adopt all available acceleration opportunities from hardware side (e.g. GPUs) and innovative software solutions (e.g. machine learning). The new version of HIJING (Heavy Ion Jet INteraction Generator) fulfil these expectations. We present the latest results on hardware accelerations, indicate the novel software solutions and display the applicability of HIJING++ on existing heavy ion data. The presentation of our developments will indicate and summarize the main efforts of near future MC-codes for LHC physics.
In a context where the HEP community is striving to improve the software to cope with higher data throughput, detector simulation is adapting to benefit from new performance opportunities. Given the complexity of the particle transport modeling, new developments such as adapting to accelerator hardware represent a scalable R&D effort.
The AdePT and Celeritas projects have already demonstrated the feasibility of porting realistic detector simulations to GPUs, which are becoming more and more available as computing resources. However, achieving efficiencies comparable to the standard CPU-based simulation still has essential work sites, and improving GPU support for geometry is one of them. VecGeom library is one of the geometry back-ends available for Geant4, used in production by several experiments. VecGeom is CUDA-aware, but recent studies have pinpointed the current GPU implementation as a major source of divergence and inefficiency in GPU simulation workflows.
We will present the results of a one-year effort to develop a fully portable geometry model mapping the existing Geant4 geometry descriptions to a GPU-friendly surface-based approach. The implementation is completely transparent and aims to provide a GPU implementation that factorizes the divergent code of the 3D primitive solids into simpler and more balanced 2D surface algorithms.
Motivated by the need to have large Monte Carlo data statistics to be able to perform the physics analysis for the coming runs of HEP experiments, particularly for HL-LHC, there are a number of efforts exploring different avenues for speeding up particle transport simulation. In particular, one of the possibilities is to re-implement the simulation code to run efficiently on GPUs. This could allow future large Monte Carlo productions to utilise GPU resources, as well as traditional CPUs.
We present the status and plans of the Accelerated demonstrator of electromagnetic Particle Transport (AdePT) R&D project. The goal of this development is to provide a realistic demonstrator of electromagnetic calorimeter simulation on GPUs, with the geometry as complex as the LHC experiments’ detectors, complete electromagnetic physics, and all the required energy scoring infrastructure. We will discuss the GPU-specific workflow of this prototype, and describe the implementation of its different components.
We will also look into the aspect of integrating the new GPU-based simulation module with the existing CPU-based ones, namely the interfacing with the Geant4 toolkit. We will show a possible scenario of running the existing Geant4 simulations with their calorimeter part delegated to AdePT on GPUs.
We will present the performance both in the standalone mode as well as when integrated into Geant4, discuss the identified bottlenecks and propose a plan of possible further optimizations.
Monte Carlo detector transport codes are one of the backbones in high-energy physics. They simulate the transport of a large variety of different particle types through complex detector geometries based on a multitude of physics models.
Those simulations are usually configured or tuned through large sets of parameters. Often, tuning the physics accuracy on the one hand and optimising the resource needs on the other hand are competing requirements.
In this area, we are presenting a toolchain to tune Monte Carlo transport codes which is capable of automatically optimising large sets of parameters based on user-defined metrics.
The toolchain consists of two central components. Firstly, the MCReplay engine which is a quasi-Monte-Carlo transport engine able to fast replay pre-recorded MC steps. This engine for instance allows to study the impact of cut variations on quantities such as hits without the need to perform new full-simulations. Secondly, it consists of an automatic and generic parameter optimisation framework called O2Tuner.
The toolchain’s application in concrete use-cases will be presented. Its first application in ALICE led to the reduction of CPU time of Monte Carlo detector transport by 30\%. In addition, further possible scenarios will be discussed.
Geant4, the leading detector simulation toolkit used in High Energy Physics, employs a set of physics models to simulate interactions of particles with matter across a wide range of interaction energies. These models, especially the hadronic ones, rely largely on directly measured cross-sections and inclusive characteristics, and use physically motivated parameters. However, they generally aim to cover a very wide range of possible simulation tasks and may not always be optimized for a particular process or a given material.
The Geant4 collaboration recently made many parameters of the models accessible via a configuration interface. This opens a possibility to fit simulated distributions to thin target experimental datasets and extract optimal values of the model parameters and the associated uncertainties. Such efforts are currently undertaken by the Geant4 Collaboration with the goal of offering alternative sets of model parameters, aka “tunes”, for certain applications. The efforts should subsequently lead to more accurate estimates of the systematic errors in physics measurements given the detector simulation role in performing the physics measurements.
Results from the study will be presented to illustrate how Geant4 model parameters can be optimized through applying fitting techniques, to improve the agreement between the Geant4 and the experimental data.
Keywords: Geant4 toolkit, hadronic interactions, optimizations of phenomenological models, fitting technique
No single organisation has the resources to defend its services alone against most modern malicious actors and so we must protect ourselves as a community. In the face of determined and well-resourced attackers, we must actively collaborate in this effort across HEP and more broadly across Research and Education (R&E).
Parallel efforts are necessary to appropriately respond to this requirement. We must both share threat intelligence about ongoing cybersecurity incidents with our trusted partners, and deploy the fine-grained security network monitoring necessary to make active use of this intelligence. We must also engage with senior management in our organisations to ensure that we work alongside any broader organisational cybersecurity development programmes.
We report on progress of the Security Operations Centre (SOC) Working Group, established by the WLCG but with membership encompassing the R&E sector. The goal of the Working Group is to develop reference designs for SOC deployments and empower R&E organisations to collect, leverage and act upon targeted, contextualised, actionable threat intelligence. This report will include recent SOC deployment activities at sites with network connectivity in excess of 100Gb/s, as well as new technology designs. An important development, which is likely to form a key part of the WLCG security strategy, is the potential use of passive DNS logs to allow sites without fine-grained network monitoring to benefit from the threat intelligence available to our community.
We also report on higher level progress in engaging with the broader community in establishing common approaches to this vital area of cybersecurity.
In 2022, CERN ran its annual phishing campaign in which 2000 users gave away their passwords (Note: this number is in line with results of campaigns at other organisations). In a real phishing incident this would have meant 2000 compromised accounts... unless they were protected by Two-Factor Authentication (2FA)! In the same year, CERN introduced 2FA for accounts with access to critical services. The new login flow requires users to always authenticate with a 2FA token (either TOTP or WebAuthn), introducing a significant security improvement for the individual and the laboratory. In this paper we will discuss the rationale behind the 2FA deployment, as well as the technical setup of 2FA in CERN's Single Sign-On, Keycloak. We will share statistics on how users are responding to the change, and concrete actions we have taken thanks to their feedback. Finally, we briefly cover our custom extensions to Keycloak for specific use cases, which include, persistent cookies and our Kerberos setup.
Since 2017, the Worldwide LHC Computing Grid (WLCG) has been working towards enabling token-based authentication and authorization throughout its entire middleware stack. Following the initial publication of the WLCG v1.0 Token Schema in 2019, work has been done to integrate OAuth2.0 token flows across the Grid middleware. There are many complex challenges to be addressed before the WLCG can be end-to-end token-based, including not just technical hurdles but also interoperability with the wider authentication and authorization landscape.
This paper presents the status of the WLCG coordination and deployment work, and how it relates to software providers and partner communities. The authors also detail how the WLCG token transition timeline has progressed, and how it has changed since its publication.
GlideinWMS is a distributed workload manager that has been used in production for many years to provision resources for experiments like CERN's CMS, many Neutrino experiments, and the OSG. Its security model was based mainly on GSI (Grid Security Infrastructure), using x509 certificate proxies and VOMS (Virtual Organization Membership Service) extensions. Even if other credentials, like ssh keys, were possible to authenticate with resources, proxies were also added all the time, to establish the identity of the requestor and the associated memberships or privileges. This single credential was used for everything and was, often implicitly, forwarded wherever needed.
The addition of identity and access tokens and the phase-out of GSI forced us to reconsider the security model of GlideinWMS, in order to handle multiple credentials which can differ in type, technology, and functionality.
Both identity tokens and access tokens are possible. GSI proxies even if no more mandatory, are still used, together with various JWT (JSON Web Token) based tokens and other certificates. The functionality of the credentials, defined by issuer, audience, and scope, also differ: a credential can allow access to a computing resource, or can protect the GlideinWMS framework from tampering, or can grant read or write access to storage, can provide an identity for accounting or auditing, or can provide a combination of any the formers. Furthermore, the tools in use do not include automatic forwarding and renewal of the new credentials so credential lifetime and renewal requirements became part of the discussion as well.
In this paper, we will present how GlideinWMS was able to change its design and code to respond to all these changes.
The CMS Submission Infrastructure (SI) is the main computing resource provisioning system for CMS workloads. A number of HTCondor pools are employed to manage this infrastructure, which aggregates geographically distributed resources from the WLCG and other providers. Historically, the model of authentication among the diverse components of this infrastructure has relied on the Grid Security Infrastructure (GSI), based on identities and X509 certificates. In contrast, commonly used modern authentication standards are based on capabilities and tokens. The WLCG has identified this trend and aims at a transparent replacement of GSI for all its workload management, data transfer and storage access operations, to be completed during the current LHC Run 3. As part of this effort, and within the context of CMS computing, the Submission Infrastructure group is in the process of phasing out the GSI part of its authentication layers, in favor of IDTokens and Scitokens. The use of tokens is already well integrated into the HTCondor Software Suite, which has allowed us to fully migrate the authentication between internal components of SI. Additionally, recent versions of the HTCondor-CE support tokens as well, enabling CMS resource requests to Grid sites employing this CE technology to be granted by means of token exchange. After a rollout campaign to sites, successfully completed by the third quarter of 2022, the totality of HTCondor CEs in use by CMS are already receiving Scitoken-based pilot jobs. On the ARC CE side, a parallel campaign was launched to foster the adoption of the REST interface at CMS sites (required to enable token-based job submission via HTCondor-G), which is nearing completion as well. In this contribution, the newly adopted authentication model will be described. We will then report on the migration status and final steps towards complete GSI phase out in the CMS SI.
DIRAC is the interware for building and operating large scale distributed computing systems. It is adopted by multiple collaborations from various scientific domains for implementing their computing models.
DIRAC provides a framework and a rich set of ready-to-use services for Workload, Data and Production Management tasks of small, medium and large scientific communities having different computing requirements. The base functionality can be easily extended by custom components supporting community specific workflows. A single DIRAC service can provide a complete solution for the distributed computing of one, or multiple collaborations. The Workload Management System provides a transparent, uniform interface for managing computing resources and complex workflows. The Data Management System offers several tools to ensure data handling operations. DIRAC put special emphasis on the large scale data productions and datasets management.
This contribution will highlight DIRAC's current, upcoming and planned capabilities and technologies. Examples include, but are not limited to, adoption of security tokens and interactions with Identity Provider services, integration of Clouds and High Performance Computers, interface with Rucio, improved monitoring and deployment procedures.
The recent release of AwkwardArray 2.0 significantly changes the way that lazy evaluation and task-graph building are handled in columnar analysis. The Dask parallel processing library is now used for these pieces of functionality with AwkwardArray, and this change affords new ways of optimizing columnar analysis and distributing it on clusters. In particular this allows optimization of a task graph all the way to the user code, possibly obviating the “processor” pattern Coffea has relied upon up to now. Utilizing this functionality completely required a major retooling of Coffea for this new infrastructure, which has resulted in a more extensible and easily maintainable codebase depending on the dask-awkward, and dask-histogram packages. We will demonstrate comparative performance benchmarks between Awkward-array 1.0 and Awkward-array 2.0 based releases of Coffea, as well as between processor-based and fully-dask-optimized compute graphs in AwkwardArray 2.0.
In particle physics, workflow management systems are primarily used as tailored solutions in dedicated areas such as Monte Carlo production. However, physicists performing data analyses are usually required to steer their individual, complex workflows manually, frequently involving job submission in several stages and interaction with distributed storage systems by hand. This process is not only time-consuming and error-prone, but also leads to undocumented relations between particular workloads, rendering the steering of an analysis a serious challenge.
This contribution presents the Luigi Analysis Workflow (law) Python package which is based on the open-source pipelining tool luigi, originally developed by Spotify. It establishes a generic design pattern for analyses of arbitrary scale and complexity, and shifts the focus from executing to defining the analysis logic. Law provides the building blocks to seamlessly integrate with interchangeable remote resources without, however, limiting itself to a specific choice of infrastructure.
In particular, it introduces the concept of complete separation between analysis algorithms on the one hand, and run locations, storage locations, and software environments on the other hand. To cope with the sophisticated demands of end-to-end HEP analyses, law supports job execution on WLCG infrastructure (ARC, gLite, CMS-crab) as well as on local computing clusters (HTCondor, Slurm, LSF), remote file access via various protocols using the Grid File Access Library (GFAL2), and an environment sandboxing mechanism with support for sub-shells and virtual environments, as well as Docker and Singularity containers. Moreover, the novel approach ultimately aims for analysis preservation out-of-the-box.
Law is developed open-source and independent of any experiment or the language of executed code. Over the past years, its user-base increased steadily with applications now ranging from (pre-)processing workflows in CMS physics objects groups, to pipelines performing the statistical inference in most CMS di-Higgs searches, and it serves as the underlying core software for large scale physics analyses across various research groups.
Data analysis in particle physics is socially distributed: unlike centrally developed and executed reconstruction pipelines, the analysis work performed after Analysis Object Descriptions (AODs) are made and before the final paper review—which includes particle and event selection, systematic error handling, decay chain reconstruction, histogram aggregation, fitting, statistical models, and machine learning—are often performed “off the GRID.”
This presents a challenge for developers of analysis tools, who need to know how their tools are being used in order to focus efforts in development, documentation, and training. The most common methods have traditionally been direct conversations with known users, wide-cast surveys, and download counts, but each of these has its limitations.
In this talk, I will discuss the above as well as new methods of analyzing user behavior: collecting issue comments through GitHub and GitLab APIs, statically analyzing code from thousands of git repositories matching search criteria, and web analytics of documentation sites. Applying these methods to the Awkward Array library reveals the most commonly used functions, slice idioms, and data types, as well as what libraries Awkward Array is commonly used with and how data are transferred between them. Finally, I apply these methods to other physics analysis libraries to show the generality of the techniques.
In the LHCb experiment, a wide variety of Monte Carlo simulated samples need to be produced for the experiment’s physics programme. LHCb has a centralised production system for simulating, reconstructing and processing collision data, which runs on the DIRAC backend on the WLCG.
To cope with a large set of different types of sample, requests for simulation production are based on a concept of “models” (templates) for each data-taking period, with variations for different generators and fast-simulation techniques. Request are then customised via pre-defined configuration per type of event (i.e. decay). This allows requests to be created and handled efficiently on a world-wide distributed system by a small team of people. However, maintenance and regular updates of these models, as well as the creation of bespoke requests (e.g. with filtered output) can be time-consuming tasks, prone to human error.
We present LbMCSubmit: a new scriptable submission system which generates the necessary requests from a parametrisation of the desired samples. The numerous request models are replaced by a set of rules for creating requests, thus ensuring consistency and reducing the workload required for their maintenance. Support for common use-cases is built-in, while also allowing for fine-grained customisation as needed.
Data-files specifying production requests are collected in a GitLab repository, then tested and submitted by CI jobs, using a shared infrastructure with the existing Analysis Productions package. LbMCSubmit may also be used at the command-line for running local tests or submitting user jobs (e.g. for generator tuning studies) to DIRAC.
LbMCSubmit results in a significant reduction in the time spent maintaining and updating request models, preparing and submitting the requests themselves, as well as ensuring that newly released configuration files (e.g. for new decay types) are immediately available in production.
With the construction and operation of fourth-generation light sources like European Synchrotron Radiation Facility Extremely Brilliant Source (ESRF-EBS), Advanced Photon Source Upgrade (APS-U), Advanced Light Source Upgrade (ALS-U), High Energy Photon Source (HEPS), etc., several advanced biological macromolecule crystallography (MX) beamlines are or will be built and thereby the huge amount of raw experimental data will be accumulated. Besides, high-resolution hybrid pixel array detectors are equipped and thus such large-scale and excellent-quality data will bring stringent challenges on the traditional manual or semi-automatic processing procedures. In this report, we will introduce a user-friendly, AI-empowered, auto-pipelining data analysis system for MX. It consists of four modules: (1) a boosted decision tree (BDT) based module to intelligently utilize suitable tools or algorithms for data reduction i.e. from X-ray diffraction images (TIFF/HDF5 files) to reference reflection files (MTZ); (2) a structure prediction module using database-querying or AlphaFold/OpenFold real-time prediction, i.e. from FASTA sequences to protein data bank (PDB) files; (3) a model auto-building module composed of two branches, one is for high accuracy which is time-consuming and the other is fast with lose of accuracy; (4) a structure refinement module by deep learning. This system works in two modes. One is for real-time/online analysis that operated automatically in the background by monitoring the user experimental data folder and taking default processing parameters. And the other is usually called batch mode. Firstly, users will configure the analysis procedures in GUI and then process multiple data concurrently for performances. All the equipped tools or algorithms are designed as plugins and can be substituted in a convenient way. This data analysis system is based on and developed for HEPS initially, aiming at an automatic, intelligent, and high-efficiency software and will be open-source for academic research.
Monte Carlo simulations are a key tool for the physics program of High Energy Experiments. Their accuracy and reliability is of the utmost importance. A full suite of verifications is in place for the LHCb Simulation software to ensure the quality of the simulated samples produced.
In this contribution we will give a short overview of the procedure and the tests in place, that exploits the LHCb software testing infrastructure. First level verifications are performed as soon as new software is submitted for integration in the LHCb GitLab repository. The first step consists of Continous Integration (CI) tests and so called ‘nightly tests’ performed to verify the integrity of the software with short jobs run every night. Next, in-depth performance and regression tests are carried out with the LHCbPR dedicated infrastructure. Samples of O(1000) events are generated and plots of a wide spectrum of physics observables are compared to references. Trends of performance metrics are also produced. The most recent and final step is performed after the software is deployed for production. By verifying distributions of key quantities for all simulation productions on a fraction of the events, we ensure that the output is as expected before the full samples are produced.
Simulation Data Quality shifters verify the outcome of all steps in the verification chain, and alert experts of anomalies and unexpected changes.
The challenges expected for the HL-LHC era are pushing LHC experiments to re-think their computing models at many levels. The evolution toward solutions that allow an effortless interactive analysis experience is, among others, one of the topics followed closely by the CMS experiment. In this context, ROOT RDataFrame offers a high-level, lazy programming model which makes it a flexible and user-friendly tool for HEP analysis workflows. To support this paradigm shift even further, a distributed infrastructure which leverages Dask to offload interactive payloads has been set up in production on INFN resources, transparently integrating Grid, clouds and possibly HPC. It was then a natural fit to integrate the efforts on both solutions to get a peek on how a Phase2 analysis might look like. The presented work will provide an overview of the main technologies involved and will describe the results of the first benchmark using the analysis of Vector Boson Scattering (VBS) of same-sign W boson pairs processes with one hadronically-decaying tau lepton and one light lepton (electron or muon) in the final state .The analysis workflow includes systematic variations as well as pre- and post-selection phases. The proposed comparison between a “legacy” batch-based strategy and the interactive RDataframe is based on several metrics from event throughput to resource consumption. To achieve a fair comparison both cases have been executed running the same analysis on the very same set of resources hosted at the INFN distributed analysis facility.
ALICE, one of the four large experiments at CERN LHC, is a detector for the physics of heavy ions. In a high interaction rate environment, the pile-up of multiple events leads to an environment that requires advanced multidimensional data analysis methods.
Machine learning (ML) has become very popular in multidimensional data analysis in recent years. Compared to the simple, low-dimensional analytical approaches used in the past, it is more difficult to interpret machine learning models and evaluate their uncertainties. On the other hand, oversimplification and reduction of dimensionality in the analysis lead to explanations becoming more complex or wrong.
Our goal was to provide a tool for dealing with multidimensional problems, to simplify data analysis in many (optimally all relevant) dimensions, to fit and visualize multidimensional functions including their uncertainties and biases, to validate assumptions and approximations, to easy define the functional composition of analytical parametric and non-parametric functions, to use symmetries and to define multidimensional "invariant" functions/alarms.
RootInteractive is a general-purpose tool for multidimensional statistical analysis. We use a declarative programming paradigm where we build the structure and elements of computer programs and express the logic of a computation without describing its control flow. This approach makes it easy to be used for domain experts, students and educators. RootInteractive provides functions for interactive, easily configurable visualization of unbinned and binned data, interactive n-dimensional histogramming/projection and derived aggregate information extraction on the server (Python/C++) and client (Javascript). We support client/server applications using Jupyter, or we can create a stand-alone client-side application/dashboard.
Using a combination of lossy and lossless data compression, datasets with, for example, O(10^7) entries times O(25) attributes can be analyzed interactively in the standalone application in the O(500 MBy) browser. By applying a suitable representative downsampling O(10^-2-10^-3) and subsequent reweighting or pre-aggregation on the server or bach farm, the effective monthly/annual statistics ALICE can be analyzed interactively in many dimensions for calibration/reconstruction validation/QA/QC or statistical/physical analysis.
In this contribution, we introduce the main features of our general-purpose statistical tool and demonstrate them with examples from ALICE, used in the development of simulations/calibrations/reconstructions for combined particle identification, the spatial point distortion algorithm and the combined multiplicity-centrality estimators.
Realistic environments for prototyping, studying and improving analysis workflows are a crucial element on the way towards user-friendly physics analysis at HL-LHC scale. The IRIS-HEP Analysis Grand Challenge (AGC) provides such an environment. It defines a scalable and modular analysis task that captures relevant workflow aspects, ranging from large-scale data processing and handling of systematic uncertainties to statistical inference and analysis preservation. By being based on publicly available Open Data, the AGC provides a point of contact for the broader community. Multiple different implementations of the analysis task that make use of various pipelines and software stacks already exist.
This contribution presents an updated AGC analysis task. It features a machine learning component and expanded analysis complexity, including the handling of an extended and more realistic set of systematic uncertainties. These changes both align the AGC further with analysis needs at the HL-LHC and allow for probing an increased set of functionality.
Another focus is the showcase of a reference AGC implementation, which is heavily based on the HEP Python ecosystem and uses modern analysis facilities. The integration of various data delivery strategies is described, resulting in multiple analysis pipelines that are compared to each other.
The growing amount of data generated by the LHC requires a shift in how HEP analysis tasks are approached. Efforts to address this computational challenge have led to the rise of a middle-man software layer, a mixture of simple, effective APIs and fast execution engines underneath. Having common, open and reproducible analysis benchmarks proves beneficial in the development of these modern tools. One such benchmark is provided by the Analysis Grand Challenge (AGC), which represents a blueprint for a realistic analysis pipeline. This contribution presents the first AGC implementation that leverages ROOT RDataFrame, a powerful, modern and scalable execution engine for the HENP use cases. The different steps of the benchmarks are written with a composable, flexible and fully Pythonic API. RDataFrame can then transparently run the computations on all the cores of a machine or on multiple nodes thanks to automatic dataset splitting and transparent workload distribution. The portability of this implementation is shown by running on various resources, from managed facilities to open cloud platforms for research, showing usage of interactive and distributed environments.
Abstract
PyPWA is a toolkit designed to fit (regression) parametric models to data and to generate distributions (simulation) according to a given model (function). PyPWA software has been written under the python ecosystem with the goal of performing Amplitude or Partial Wave Analysis (PWA) in nuclear and particle physics experiments. The aim of spectroscopy experiments is often the identification short lived (strongly interacting) resonances that have decayed to the observed multi-particle final states. The PyPWA toolkit is built from individual and mostly disjoint components that the user can arrange in a variety of ways. PyPWA can solve broad collection of problems. Users just need to provide a function (model), data and simulation in their preferred formats. PyPWA will provide tools for two basic components, Data Processing (read, write, splitting) and Analysis (simulation, fitting and prediction). It also provides various ways of speeding up calculations through multi-threading and the use of GPUs. The flexibility of PyPWA and its use of many standard packages make it an ideal tool for both new and experienced scientists wanting to perform fits of models to data. The examples provided with the code allow for a quick start and the user-friendly Python ecosystem comes with a large user base with a lot of support. We will briefly describe the general features of amplitude analysis and describe the PyPWA software philosophy, structure and use.
Most analyses in the LHCb experiment start by filtering data and simulation stored on the WLCG. Traditionally this has been achieved by submitting user jobs that each process a small fraction of the total dataset. While this has worked well, it has become increasingly complex as the LHCb datasets have grown and this model requires all analysts to understand the intricacies of the grid. This model also burdens individuals with needing to document the way in which each file was processed.
Here we present a more robust and efficient approach, known within LHCb as Analysis Productions. Filtering LHCb datasets to create ntuples is done by creating a merge request in GitLab, which is then tested automatically on a small subset of the data using Continuous Integration. Results of these tests are exposed via a dedicated website that aggregates the most important details. Once the merge request is reviewed and accepted, productions are submitted and run automatically using the power of the DIRAC transformation system. The output data is stored on grid storage and tools are provided to make it easily accessible for analysis.
This new approach has the advantage of being faster and simpler for analysts while also ensuring that the full processing chain is preserved and reproducible. Using GitLab to manage submissions encourages code review and the sharing of derived datasets between analyses.
The Analysis Productions system has been stress-tested with legacy data for a couple of years and is becoming the de facto standard by which data, legacy or run-3, is prepared for physics analysis. It has been scaled to analyses that process thousands of datasets and the approach of testing prior to submission is now being expanded to other production types in LHCb.
We will present the rapid progress, vision and outlook across multiple state of the art development lines within the Global Network Advancement Group and its Data Intensive Sciences and SENSE/AutoGOLE working groups, which are designed to meet the present and future needs and address the challenges of the Large Hadron Collider and other science programs with global reach. Since it was founded in the Fall of 2019 and the working groups were formed in 2020, in partnership with ESnet, Internet2, CENIC, GEANT, ANA, RNP, StarLight, NRP, N-DISE, AmLight, and many other leading research and education networks and network R&D projects, as well as Caltech, UCSD/SDSC, Fermilab, CERN, LBL, and many other leading universities and laboratories, the GNA-G working groups have deployed expanding virtual circuit and programmable testbed spanning six continents which supports continuous developments aimed at the next generation of programmable networks interworking with the science programs' computing and data management systems. The talk will cover examples of recent progress in developing and deploying new methods and approaches in multidomain virtual circuits, flow steering, path selection, load balancing and congestion avoidance, segment routing and machine learning based traffic prediction and optimization. Examples of results demonstrated at the Supercomputing 2022 conference (SC22) and under persistent development will be included.
The NOTED (Network Optimised Transfer of Experimental Data) project has successfully demonstrated the ability to dynamically reconfigure network links to increase the effective bandwidth available for FTS-driven transfers between endpoints, such as WLCG sites by inspecting on-going data transfers and so identifying those that are bandwidth-limited for a long period of time. Recently, the architecture of NOTED has been improved and the software has been packaged for easy distribution.
These improved capabilities and features of NOTED have been tested and demonstrated at various international conferences. For example, during demonstrations at Supercomputing 2022, independent instances of NOTED at CERN (Switzerland) and DE-KIT (Germany) monitored large data transfers generated by the ATLAS experiment between these sites and TRIUMF (Canada). We report here on this and other events, highlighting how NOTED can predict link congestion or a notable increase in the network utilisation over an extended period of time and, where appropriate, automatically reconfigure network topology to introduce an additional—or an alternative and better performing—path by using dynamic circuit provisioning systems such as SENSE and AutoGOLE.
Data caches of various forms have been widely deployed in the context of commercial and research and education networks, but their common positioning at the Edge limits their utility from a network operator perspective. When deployed outside the network core, providers lack visibility to make decisions or apply traffic engineering based on data access patterns and caching node location.
As an alternative, in-the-network caching provides a different type of content delivery network for scientific data infrastructure, supporting on-demand temporary caching service. It also allows providers to design data hotspots into the network topology, and to manage traffic movement and congestion by data-driven traffic engineering. There is also an opportunity for strategies around regional in-network cache placement to reduce the data access latency for the users and increase the overall computing application performance.
We will describe the status of in-network caching nodes deployed within ESnet in support of the US CMS data federation, which includes caches maintained by the University of Wisconsin-Madison, MIT, UCSD, Caltech, and ESnet. We will describe the container and networking architecture used to deploy data caches within ESnet, and update on the evolving tooling around service management lifecycle. An analysis of cache usage will also be provided along with an outlook for expanding the in-network cache footprint.
The Caltech team, in collaboration with network, computer science, and HEP partners at the DOE laboratories and universities, is building intelligent network services ("The Software-defined network for End-to-end Networked Science at Exascale (SENSE) research project") to accelerate scientific discovery.
The overarching goal of SENSE is to enable National Labs and universities to request and provision end-to-end intelligent network services for their application workflows leveraging SDN capabilities. The project's architecture, models, and demonstrated prototype define the mechanisms needed to dynamically build end-to-end virtual guaranteed networks across administrative domains, with no manual intervention from sysadmins or wide-are network engineers. In addition, a highly intuitive intent-based interface, as defined by the project, allows applications to express their high-level service requirements, and an intelligent, scalable model-based software orchestrator converts that intent into appropriate network services configured across multiple types of devices.
The overarching goal of SENSE is to enable National Labs and universities to request and provision end-to-end intelligent network services for their application workflows leveraging SDN capabilities.
In this paper, we will present the system's architecture and components, the first integration results with Scientific Collaboration tools, Quality of Service, and the next steps for better network use and utilization.
A comprehensive analysis of the HEP (High Energy Physics) experiment traffic across LHCONE (Large Hadron Collider Open Network Environment) and other networks, is essential for immediate network optimisation (for example by the NOTED project) and highly desirable for long-term network planning. Such an analysis requires two steps: tagging of network packets to indicate the type and owner of the traffic being carried and then processing of the tagged packets. The RNTWG (Research Network Technical Working Group) has defined a specification to identify the experiment and the application that originates a given network flow, named scitags (Scientific Network Tags) that is applied to the flow label field of the IPv6 header, this is being reported elsewhere at this conference. We report here on the second step: our processing of packets tagged according to this specification.
We developed P4flow as a software-defined networking approach by using P4 (Programming Protocol-Independent Packet Processors), a language for programming the data plane of network devices to accounting and process IPv6 packets with a scitags-based stamp in the flow label field, to understand the network utilisation and the applications used by the WLCG (Worldwide Large Hadron Collider Computing Grid) sites. With P4$_{\text{flow}}$, and exploiting the control plane capabilities provided by RARE/freeRtr (an Open Source Network Operating System developed by the GÉANT community), we can not only generate statistics concerning the traffic per experiment and application but can also, using an Intel Tofino P4-programmable ASIC Ethernet Switch, decide how to forward traffic matching defined flow labels. This latter capability is particularly interesting as we prepare for a future where LHC experiments will be sharing network links with other major science collaborations such as, for example, SKA.
Apptainer (formerly known as Singularity) since its beginning implemented many of its container features with the assistance of a setuid-root program. It still supports that mode, but as of version 1.1.0 it no longer uses setuid by default. This is feasible because it now can mount squash filesystems, mount ext2/3/4 filesystems, and use overlayfs using unprivileged user namespaces and FUSE. It also now enables unprivileged users to build containers, even without requiring system administrators to configure /etc/subuid and /etc/subgid unlike other “rootless” container systems. As a result, all the unprivileged functions can be used nested inside of another container, even if the container runtime prevents any elevated privileges.
Large research infrastructures, such as DESY and CERN, in the field of the exploration of the universe and matter (ErUM) are significantly driving the digital transformation of the future. The German action plan "ErUM-Data" promotes this transformation through the interdisciplinary networking and financial support of 20.000 scientists.
The ErUM-Data-Hub (https://erumdatahub.de) serves as a central networking and transfer office to meet these ambitions. One central task is the training of (prospective) scientists with schools and workshops in the areas of Big Data, Deep Learning, Sustainable Computing and many more.
We present the achievements up to the first anniversary of the ErUM-Data-Hub in the German ErUM community.
XAS (synchrotron X-ray absorption spectroscopy) uses X-ray photon energy as a variable to measure the structure of X-ray absorption coefficient that changes with energy. In spectral experiments, the determination of the composition and structure of unknown samples requires data collection first, and then data processing and analysis. It takes a lot of time and there can be no errors in the middle, which seriously restricts the development of spectral experiments. The absorption spectrum lines of the same material are approximately the same. Using this feature, the absorption spectrum and its related information of the material are stored in the database, and then the known spectrum information of the unknown sample that is close to the unknown sample is listed through the spectral matching algorithm to facilitate the processing of the spectral line station. Therefore, how to quickly and accurately match the composition of sample materials in real time is one of the focuses of spectroscopic line station scientists. In this paper, we propose a set of XAS spectroscopy matching and related processing software, which can provide an intuitive real-time interface display for scientists at the spectroscopy line station, and facilitate users to collect data while processing data. The software includes a variety of spectral matching algorithms, which can give the spectral lines most similar to the input spectral lines in the database and the detailed information of the spectral lines in the database; It integrates the normalization processing, principal component analysis algorithm, linear fitting algorithm, and extended edge processing algorithm of Larch software, enhances the interaction between users and spectral lines and displays the results, and weakens the details of data processing. Through the real-time display and convenient processing of line station data, the process of spectroscopy experiment is promoted and more scientists are attracted to participate in the spectroscopy experiment.
The organization of seminars and conferences was strongly influenced by the covid-19 pandemic.
In the early period of the pandemic, many events were canceled or held completely online, using video conferencing tools such as ZOOM or MS Teams. Later, thanks to large-scale vaccination and immunization, it was possible to organize again large events in the presence. Nevertheless, given some local restrictions to people temporarily affected by Covid-19, it was still necessary to provide online modalities for participants who could not participate in presence, having in fact hybrid events with both remote and in-person participation.
In this contribution we describe the experience with the ZOOM-Events platform, used for the ICHEP 2022 International Conference on High Energy Physics, held in Bologna in July 2022, with about 1100 participants in presence and 300 connected remotely. We describe in detail how the ZOOM Events platform was configured for the management of the numerous parallel sessions and the granting of access to participants and how we dealt with the problems that emerged in the organizational phases.
Recently, a workshop on Artificial Intelligence for the Electron Ion Collider (AI4EIC) has been held at the College of William&Mary. The workshop covered all active and potential areas of applications of AI/ML for the EIC; it also had a strong outreach and educational component, with different tutorials given by experts in AI and machine learning from national labs, universities, and industry as well as a hackathon satellite event during the last day of the workshop. The format of the hackathon was hybrid and international
(both local and remote participation). For this hackathon, we proposed problems with increased level of difficulty and that are deemed to be solvable in a one-day event, starting from a problem that is accessible to everyone. We focused on the dual-radiator Ring Imaging Cherenkov (dRICH) detector under development as part of the particle-identification (PID) system at the future EPIC detector at EIC. Data have been produced using the EPIC software stack. Documentation and data sets have been made available on zenodo. This experience has been highly educational, particularly for students; interestingly, it also showed the potential advantages of modern AI/ML approaches to PID for imaging Cherenkov detectors compared to traditional approaches.
To meet the computing challenges of upcoming experiments, software training efforts play an essential role in imparting best practices and popularizing new technologies. Because many of the taught skills are experiment-independent, the HSF/IRIS-HEP training group coordinates between different training initiatives while building a training center that provides students with various training modules. Both the events and the development of the training material are driven by a community of motivated educators. In this talk, we describe tools and organizational aspects with which we cultivate a strong sense of community ownership, provide recognition for individual contributions, and continue to motivate our members. We also describe new initiatives to foster further growth and increased reach. Among these is the evolution of our Training Center into a dynamic web page that allows us to significantly increase the scope of listed content without sacrificing readability.
Deep underground, the removal of rock to fashion three soccer field
sized caverns is underway, as are detector prototypings. In 2024, the
first DUNE far detector will be constructed as a large cryostat,
instrumented as a traditional tracking calorimeter but in a cold bath of
zenon doped liquidized argon. An Epic Game UnReal Engine rendered 3D
simulation of the underground laboratory has been developed from
electronic engineering drawings for the purpose of outreach to middle
and high school students and to stimulate an academic interest to know
more about high energy physics to a computer savvy generation of
students. and ideally enroll in high school and college classes that
might one day lead to becoming a HEP scientist. An overview of the
project and a virtual lab tour will be provided in this presentation.
Machine learning (ML) and deep learning (DL) are powerful tools for modeling complex systems. However, most of the standard models in ML/DL do not provide a measure of confidence or uncertainties associated with their predictions. Further, these models can only be trained on available data. During operation, models may encounter data samples poorly reflected in training data. These data samples are called Out-of-Distribution (OOD) samples, and the predictions on these can be arbitrarily wrong. Uncertainty Quantification is a technique that provides insight into a model’s confidence in predictions, including OOD samples.
Gaussian Process (GP) is a well-known ML method that provides accurate estimation of prediction uncertainties. We will present our work with GP for AI-based Experimental Control to stabilize gain measurement of the Central Drift Chamber in the GlueX experiment at Jefferson Lab.
As the number of observed data points and/or input features increases, traditional GP implementations do not scale well, and different approximation methods are applied to improve the scaling. To provide accurate uncertainty quantification for DL models, we developed and applied Deep Gaussian Process Approximation (DGPA) methods. We will discuss our work with DGPA for three different applications namely 1) uncertainty aware errant beam prediction at the Spallation Neutron Source accelerator, 2) uncertainty aware particle identification for Solenoidal Large Intensity Device experiment at Thomas Jefferson National Accelerator Facility, and 3) uncertainty aware surrogate model for the Fermi National Accelerator Laboratory booster complex.
We explore interpretability of deep neural network (DNN) models designed for identifying jets coming from top quark decay in the high energy proton-proton collisions at the Large Hadron Collider (LHC). Using state-of-the-art methods of explainable AI (XAI), we identify which features play the most important roles in identifying the top jets, how and why feature importance varies across different XAI metrics, and how latent space representations encode information as well as correlate with physical quantities. We additionally illustrate the activity of hidden layers as Neural Activation Pattern (NAP) diagrams to understand how DNNs relay information across the layers and how this understanding can help us to make such models significantly simpler by allowing effective model reoptimization and hyperparameter tuning.
The task of identifying B meson flavor at the primary interaction point in the LHCb detector is crucial for measurements of mixing and time-dependent CP violation.
Flavor tagging is usually done with a small number of expert systems that find important tracks to infer the B flavor from.
Recent advances show that replacing all of those expert systems with one ML algorithm that considers all tracks in an event yields an increase in tagging power. However, training the current classifier takes a long time and it is not suitable for use in real time triggers.
In this work we present a new classifier, based on the DeepSet architecture.
With the right inductive bias of permutation invariance, we achieve great speedups in training (multiple hours vs 10 minutes), a factor of 4-5 speed-up in inference for use in real time environments like the trigger and less tagging asymmetry.
For the first time we investigate and compare performances of these “Inclusive Flavor Taggers” on simulation of the upgraded LHCb detector for the third run of the LHC.
An increasingly frequent challenge faced in HEP data analysis is to characterize the agreement between a prediction that depends on a dozen or more model parameters–such as predictions coming from an effective field theory (EFT) framework–and the observed data. Traditionally, such characterizations take the form of a negative log likelihood (NLL) distribution, which can only be evaluated numerically. The lack of a closed-form description of the NLL function makes it difficult to convey results of the statistical analysis. Typical results are limited to extracting "best fit" values of the model parameters and 1-D intervals or 2-D contours extracted from scanning the higher dimensional parameter space. It is desirable to explore these high-dimensional model parameter spaces in more sophisticated ways. One option for overcoming this challenge is to use a neural network to approximate the NLL function. This approach has the advantage of being continuous and differentiable by construction, which are essential properties for an NLL function and may also provide useful handles in exploring the NLL as a function of the model parameters. In this talk, we describe the advantages and limitations of this approach in the context of applying it to a CMS data analysis using the framework of EFT.
Searches for new physics set exclusion limits in parameter spaces of typically up to 2 dimensions. However, the relevant theory parameter space is usually of a higher dimension but only a subspace is covered due to the computing time requirements of signal process simulations. An Active Learning approach is presented to address this limitation. Compared to the usual grid sampling, it reduces the number of parameter space points for which exclusion limits need to be determined. Hence it allows to extend interpretations of searches to higher dimensional parameter spaces and therefore to raise their value, e.g. via the identification of barely excluded subspaces which motivate dedicated new searches.
In an iterative procedure, a Gaussian Process is fit to excluded signal cross-sections. Within the region close to the exclusion contour predicted by the Gaussian Process, Poisson disc sampling is used to determine further parameter space points for
which the cross-section limits are determined. The procedure is aided by a warm-start phase based on computationally inexpensive, approximate limit estimates such as total signal cross-sections. A python package, excursion [1], provides the Gaussian Process routine. The procedure is applied to a Dark Matter search performed by the ATLAS experiment, extending its interpretation from a 2 to a 4-dimensional parameter space while keeping the computational effort at a low level.
The result is published in two formats: on one hand there is a publication of the Gaussian Process model. On the other hand, a visualization of the full 4-dimensional contour is presented as a collection of 2-dimensional exclusion contours where the 2 remaining parameters are chosen by the user.
[1] https://github.com/diana-hep/excursion
The continuous growth in model complexity in high-energy physics (HEP) collider experiments demands increasingly time-consuming model fits. We show first results on the application of conditional invertible networks (cINNs) to this challenge. Specifically, we construct and train a cINN to learn the mapping from signal strength modifiers to observables and its inverse. The resulting network infers the posterior distribution of the signal strength modifiers rapidly and for low computational cost. We present performance indicators of such a setup including the treatment of systematic uncertainties. Additionally, we highlight the features of cINNs estimating the signal strength for a vector boson associated Higgs production analysis carried out at the CMS experiment on Monte Carlo samples.
Quantum Computing (QC) is a promising early-stage technology that offers novel approaches to simulation and analysis in nuclear and high energy physics (NHEP). By basing computations directly on quantum mechanical phenomena, speedups and other advantages for many computationally hard tasks are potentially achievable, albeit both, the theoretical underpinning and the practical realization, are still subject to considerable scientific debate, which raises the question of applicability in NHEP.
In this contribution, we describe the current state of affairs in QC: Currently available noisy, intermediate-scale quantum (NISQ) computers suffer from a very limited number of quantum bits, and are subject to considerable imperfections, which narrows their practical computational capabilities. Our recent work on optimization problems suggests that the Co-Design of quantum hardware and algorithms is one route towards practical utility. This approach offers near-term advantages throughout a variety of domains, but requires interdisciplinary exchange between communities.
To this end, we identify possible classes of applications in NHEP, ranging from quantum process simulation over event classification directly at the quantum level to optimal real-time control of experiments. These types of algorithms are particularly suited for quantum algorithms that involve Variational Quantum Circuits, but might also benefit from more unusual special-purpose techniques like (Gaussian) Boson Sampling. We outline challenges and opportunities in the cross-domain cooperation between QC and NHEP, and show routes towards co-designed systems and algorithms. In particular, we aim at furthering the interdisciplinary exchange of ideas by establishing a joint understanding of requirements, limitations and possibilities.
Over the last 20 years, thanks to the development of quantum technologies, it has been
possible to deploy quantum algorithms and applications, that before were only
accessible through simulation, on real quantum hardware. The current devices available are often refereed to as noisy intermediate-scale quantum (NISQ) computers and they require
calibration routines in order to obtain consistent results.
In this context, we present the latest developments of Qibo, an open-source framework for quantum computing.
Qibo was initially born as a tool for simulating quantum circuits.
Through its modular layout for backend abstraction it is possible to change effortlessly between different backends, including a high-performance simulator based on just-in-time compilation, Qibojit, which is able to simulate circuits with large number of qubits (greater than 35).
The latest additions have been Qibolab and Qibocal. The first one is a module that makes possible to employ the language developed by Qibo to execute quantum circuits on real quantum hardware, also based on different electronics. The second one is a general framework for performing calibration, characterization and randomized benchmarking protocols on all the platforms compatible with Qibolab. The advantage of these tools is that we are able to use different setups while accessing them through the same language.
We illustrate two applications of Quantum Machine Learning aimed at HEP and implemented thanks to our framework: a generative model (quantum GAN) used in the context of Monte Carlo event generation and a variational quantum circuit used to determine the content of the proton.
The Quantum Angle Generator (QAG) constitutes a new quantum machine learning model designed to generate accurate images on current Noise Intermediate Scale (NISQ) Quantum devices. Variational quan- tum circuits constitute the core of the QAG model, and various circuit architectures are evaluated. In combination with the so-called MERA- upsampling architecture, the QAG model achieves excellent results, which are analyzed and evaluated in detail. To our knowledge, it is the first time that such accurate results are achieved by a quantum model. To explore the noise robustness of the model, an extensive quan- tum noise study is carried out. In this paper it is demonstrated, that the model trained on the quantum device learns the hardware noise behaviour and generates outstanding results with it. It is verified that even a quantum hardware machine calibration change during training of up to 8% can be well tolerated. For demonstration, the model is employed to a crucial high energy physics simulation use case. The sim- ulations are required to measure particle energies and, ultimately, to discover unknown particles at the Large Hadron Collider at CERN.
In the near future, the LHC detector will deliver much more data to be processed. Therefore, new techniques are required to deal with such a large amount of data. Recent studies showed that one of the quantum computing techniques, quantum annealing (QA), can be used to perform the particle tracking with efficiency higher than 90% even in the dense environment. The algorithm starts from determining the connection between the hits, and classifies the objects with their pattern as doublet (pair of hits), triplet (three hits in a roll) or quadruplet (four hits in a roll). In order to perform the QA process, all these objects have to be constructed into a Quadratic Unconstrained Binary Optimization (QUBO) format. The current study aims to reduce the computational cost in the QA-based tracking algorithm by implementing a graph neural network (GNN) in the pre-processing stage to select input object for QUBO, and by optimizing the tightness of the selection. Moreover, the tracking performances between the standard QA-based tracking algorithm and the GNN-QA tracking algorithm are also compared.
The Superconducting Quantum Materials and Systems Center (SQMS) and the Computational Science and AI Directorate (CSAID) at Fermi National Accelerator Laboratory and Rigetti Computing have teamed up to define and deliver a standard pathway for quantum computing at Rigetti from HEPCloud. HEPCloud now provides common infrastructure and interfacing for managing connectivity and providing access to remote quantum resources using cloud services. HEPCloud provides the tools necessary for scheduling and running quantum applications that not only require QPU resources, but also a tight coupling with classical algorithms that utilize use QPU resources as co-processors. With this new interface, quantum resources can be accessed through familiar job submission and monitoring grid infrastructure available at the Fermilab computing facilities. The system incorporates AWS to handle both the application computational load and the communication link to Rigetti QPUs. The AWS resources can also be readily used for simulators and testing before actually submission through to Rigetti.
We have demonstrated applications ranging from optimization with QAOA, to experiments measuring qubit fidelity, to qutrit problems using the pulse package Quil-T. Notebooks developed for interactive use can readily be used with straightforward modifications to command line processing. Our computing model includes moving data into and out of AWS and Rigetti. Here we describe use cases driving this development, working example applications, the overall system architecture, and the facilities that are currently used.
The study of the decays of $B$ mesons is a key component of modern experiments which probe heavy quark mixing and $CP$ violation, and may lead to concrete deviations from the predictions of the Standard Model [1]. Flavour tagging, the process of determining the quark flavour composition of $B$ mesons created in entangled pairs at particle accelerators, is an essential component of this analysis, enabling the study of asymmetries in the decay rate of neutral $B$ mesons to flavour agnostic $CP$ eigenstates [1] and the explicit violation of $T$ symmetry at the level of fundamental interactions [2].
Flavour tagging is a difficult problem, depending in general on subtle correlations between the momenta and particle types of the many decay products emerging from the initial particle collision. Problems which require the detection of faint signals within vast quantities of data fall naturally within the domain of machine learning (ML), and indeed flavour tagging has traditionally been most readily tackled via ML [1].
Concurrently, the recent physical realisation of quantum computers has seen significant interest in the prospects of applying quantum machine learning (QML) methods to data intensive problems in particle physics [3]. In this work we employ QML for $B$ meson flavour tagging, investigating the performance of boosted ensembles of continuous variable quantum support vector machines in both the high and low entanglement regimes. We obtain results that are competitive with state-of-the-art classical methods and bode well for the performance of QML algorithms running on the large-scale quantum computers of the future.
[1] Abudinén, F., et al. The European Physical Journal C, 82, (2022)
[2] Lees, J. P., et al. Physical review letters, 109, 211801 (2012)
[3] Heredge, J., et al. Computing and Software for Big Science, 5, (2021)
Join like-minded attendees to hang out and celebrate diversity at the Grain, a rooftop beer garden located atop the Hilton Norfolk The Main hotel. This will be a casual evening of camaraderie.
Sponsorship provided by IDEAS4HPC.
ALICE has upgraded many of its detectors for LHC Run 3 to operate in continuous readout mode recording Pb-Pb collisions at 50 kHz interaction rate without trigger.
This results in the need to process data in real time at rates 50 times higher than during Run 2. In order to tackle such a challenge we introduced O2, a new computing system and the associated infrastructure. Designed and implemented during the long shutdown, O2 is now in production taking care of all the data processing needs of the experiment.
O2 is designed around the message passing paradigm enabling resilient, parallel data processing for both the synchronous (to LHC beam) and asynchronous data taking and processing phases.
The main purpose of the synchronous online reconstruction is detector calibration and raw data compression. This synchronous processing is dominated by the TPC detector, which produces by far the largest data volume, and TPC reconstruction is fully running on GPUs.
When there is no beam in the LHC, the powerful GPU-equipped online computing farm of ALICE is used for the asynchronous reconstruction, which creates the final reconstruction output for analysis from the compressed raw data.
Since the majority of the compute performance of the online farm is in the GPUs, and since the asynchronous processing is not dominated by the TPC in the way the synchronous processing is, there is an ongoing effort to offload a significant amount of compute load from other detectors to the GPU as well.
The talk will present the experience from running the O2 framework in production during the 2022 ALICE data taking, with particular regard to the GPU usage, an overview of the current state and the plans for the asynchronous reconstruction, and the current performance of synchronous and asynchronous reconstruction with GPUs for pp and Pb-Pb data.
Streaming Readout Data Acquisition systems coupled with distributed resources spread over vast geographic distances present new challenges to the next generation of experiments. High bandwidth modern network connectivity opens the possibility to utilize large, general-use, HTC systems that are not necessarily located close to the experiment. Near real-time response rates and workflow colocation can provide high reliability solutions to ensure efficient use of beam time. This talk will focus on a few technologies currently being developed at Jefferson Lab and in collaboration with ESnet to support fully streaming DAQ systems.
As nuclear physics collaborations and experiments increase in size, the data management and software practices in this community have changed as well. Large nuclear physics experiments at Brookhaven National Lab (STAR, PHENIX, sPHENIX), at Jefferson Lab (GlueX, CLAS12, MOLLER), and at the Electron-Ion Collider (ePIC) are taking different approaches to data management, building on existing frameworks or developing new solutions as necessary. In particular, where data analysis patterns are different from high energy physics, the solutions specific to nuclear physics lead to other solutions. Along with this transition to new tools, some collaborations are navigating changes from past practices in smaller efforts. I will give an overview of the approaches that are in use or planned, with a focus on common aspects.
This presentation will cover the content of the report delivered by the Snowmass computational Frontier late in 2022. A description of the frontier organization and various preparatory events, including the Seattle Community Summer Study (CSS), will be followed by a discussion on the evolution of computing hardware and the impact of newly established and emerging technologies, including Artificial Intelligence (AI) and Quantum Computing (QC). The report findings and recommendations will be presented, including the main one on the creation of a Coordinating Panel on Software and Computing (CPSC).
The U.S. Nuclear Physics community has been conducting long-range planning (LRP) for nuclear science since late 1970s. The process is known as the Nuclear Science Advisory Committee (NSAC) LRP with NSAC being an advisory body jointly appointed by the U.S. Department of Energy and the U.S. National Science Foundation. The last NSAC LRP was completed in 2015 and the current NSAC LRP is ongoing and the LRP report is expected in the fall of 2023. Part of the LRP process is the community driven town meetings led by the Division of Nuclear Physics of the American Physical Society. In this presentation, I will provide some highlights from these town meetings in the context of computing. Brookhaven National Laboratory is supported by the U.S. Department of Energy's Office of Science.
Today's students are tomorrow's leaders in science, technology, engineering and math. To ensure the best minds reach their potential tomorrow, it's vital to ensure that students not only experience meaningful STEM learning today, but also have the opportunities and support to pursue careers in a STEM environment that is more welcoming, inclusive and just. This panel will feature expertise from across Hampton Roads in building an equitable workforce from a racial justice perspective. The panelists bring experience working with pre-college students (Ivan McKinney, District Manager/Corporate Trainer, Unreasonable Kids College) and A.K. Schultz, CEO, SVT Robotics), within a university (Dr. Aurelia T. Williams, Vice Provost for Academic and Faculty Affairs, Norfolk State University) and within a federally funded aeronautical research center (Director Clayton Turner, NASA Langley). The panel will be moderated by Kimberly Weatherly (Assistant Dean and Director, William & Mary Center for Student Diversity).
Big science is represented by projects like those in particle physics. Big engineering is the application of engineering principles to large-scale projects that have a significant impact on society, like popular use of AI/ML (think ChatGPT and Google Bard). Both big science and big engineering are among the noblest and boldest applications of the human intellect to understanding the universe and our place in it. Both depend on human collaboration to generate the ingenuity needed to make their impacts positive ones. Both are marred by evidence of bias, particularly racial bias, that lessens intellectual excellence. LEIDA - Leadership on Equity, Inclusion, Diversity, and Access is needed to ensure that opportunities lost in the past due to marginalization of particular communities eventually ends and the full breadth of creativity and innovation possible determines the future of our field.
The WLCG infrastructure provides the compute power and the storage capacity for the computing needs of the experiments at the Large Hadron Collider (LHC) at CERN. The infrastructure is distributed across over 170 data centers in more than 40 countries. The amount of consumed energy in WLCG to support the scientific program of the LHC experiments and its evolution depends on different factors: the luminosity of the LHC and its operating conditions, determining the data volume and the data complexity; the evolution of the computing models and the offline software of the experiments, considering the ongoing R&D program in preparation for the next LHC phase (HL-LHC); the computing hardware technology evolution in the direction of higher energy efficiency; the modernization of the facilities hosting the data centers, improving the Power Usage Efficiency. This contribution presents a study of the WLCG energy needs and their evolution for the continuation of the LHC program, based on the factors mentioned above. Some information is obtained from the CERN experience but can be extrapolated to the whole of WLCG. The study provides therefore a holistic view for the infrastructure rather than a detailed prediction at the level of the single facilities. It presents an accurate view of the trends and offers a model for more refined studies.
The Data Lake concept has promised increased value to science and more efficient operations for storage compared to the traditional isolated storage deployments. Building on the established distributed dCache serving as the Nordic Tier-1 storage for LHC data, we have also integrated tier-2 pledged storage in Slovenia, Sweden, and Switzerland, resulting in a coherent storage space well above the expected for the funding committed to the Nordic Tier-1 site.
We have implemented this with an innovative automated deployment of dCache that scales well over many sites in a distributed federation. This setup optimizes for minimal local site effort, leading to a storage service that delivers increased value to scientists while at the same time reducing the cost of operations.
ARC with caching is used for computing in order to increase performance by up to 50% when reading from geographically distributed storage, as well as reduce bandwidth use.
China’s High Energy Photon Source (HEPS), the first national high-energy synchrotron radiation light source and soon one of the world’s brightest fourth-generation synchrotron radiation facilities, is being under intense construction in Beijing’s Huairou District, and will be completed in 2025.
To make sure that the huge amount of data collected at HEPS is accurate, available and accessible, we developed an effective data management system that is aimed at automating the organization, transfer, storage, distribution and sharing of the data produced from HEPS experiments. First, the general situation of HEPS and the construction progress of the whole project are introduced. Second, the architecture and data flow of the HEPS DMS are described. Third, key techniques and new function modules implemented in this system are introduced. For example, the process of automatic data tracking when using a hierarchical storage policy is illustrated, and how the DMS deals with the metadata collection when an emergency occurs such as beamline network interruption. Finally, the progress and the effect of the data management and data service system deployed at testbed beamlines of BSRF are given.
The Vera C. Rubin observatory is preparing for execution of the most ambitious astronomical survey ever attempted, the Legacy Survey of Space and Time (LSST). Currently in its final phase of construction in the Andes mountains in Chile and due to start operations late 2024 for 10 years, its 8.4-meter telescope will nightly scan the southern sky and collect images of the entire visible sky every 4 nights using a 3.2 Gigapixel camera, the largest imaging device ever built for astronomy. Automated detection and classification of celestial objects will be performed by sophisticated algorithms on high-resolution images to progressively produce an astronomical catalog eventually composed of 20 billion galaxies and 17 billion stars and their associated physical properties.
In this contribution we will present an overall view of the system currently in construction to perform data distribution and the annual reprocessing campaigns of the entire image dataset collected since the beginning of the survey, using computing and storage resources provided by 3 Rubin data facilities (one in the US and two in Europe). Each year a data release will be produced and delivered to science collaborations for their studies in 4 science areas: probing dark energy and dark matter, taking an inventory of the solar system, exploring the transient optical sky and mapping the Milky Way.
We will present how we leverage some of the practices and tools used for large-scale distributed data processing by other projects in the high energy physics and astronomy communities and how we integrate them with tools developed by the Rubin project for meeting the specific challenges it faces.
ALICE is one of the four large experiments at the CERN LHC designed to study the structure and origins of matter in collisions of heavy ions (and protons) at ultra-relativistic energies. The experiment measures the particles produced as a result of collisions in its center so that it can reconstruct and study the evolution of the system produced during these collisions. To perform these measurements, many different sub-detectors combined to form the experimental apparatus, each providing specific information. The ALICE Collaboration is composed of 2,000 members from over 175 physics institutes in 39 countries. Besides, numerous computing resources are available to researchers to collect, process, and analyze data gathered from experiments.
The ALICE experiment at CERN started its LHC Run 3 in 2022 with an upgraded detector and an entirely new data acquisition system, capable of collecting 100 times more events than the previous setup. One of the key elements of the new DAQ is the Event Processing Nodes (EPN) farm, which currently comprises 250 servers, each equipped with 8 MI50 ATI GPU accelerators. The role of the EPN is to make a lossy compression of the detector data from approximately 600GB/s to 100GB/s during the heavy-ion data taking period. The 100GB/s stream is written to an 80PB EOS disk buffer for further offline processing. The EPNs handle data streams, called Time Frames, of 10ms duration from the detector independently from each other and write the output, called Compressed Time Frames (CTF), to a local disk. The CTFs must be removed from the buffer as soon as the compression is completed to free the local disk for the next data. In addition to the CTFs, the EPNs process calibration data, which is also written to the local node storage and must be transferred to persistent storage rapidly. The data transfer functions are done by the EPN2EOS system, which in addition to the data copy also registers the CTFs and calibration data in the ALICE Grid catalogue. EPN2EOS is highly optimized to perform the copy and registration functions outside of the EPN data compression times, it is also capable to redirect data streams to an alternative storage system in case of network interruptions or unavailability of the primary storage and has extensive monitoring and messaging system to present the ALICE operations with real-time alerts in case of problems. The system has been in production since November 2021 and in this paper, we describe its architecture, implementation, and analysis of its first year of utilization.
The File Transfer System (FTS) is a software system responsible for queuing, scheduling, dispatching and retrying file transfer requests, it is used by three of the LHC experiments, namely ATLAS, CMS and LHCb, as well as non LHC experiments including AMS, Dune and NA62. FTS is critical to the success of many experiments and the service must remain available and performant during the entire LHC Run-3. Experiments use FTS to manage the transfer of their Physics files all over the World or more specifically all over the Worldwide LHC Computing Grid (WLCG). Since the start of LHC Run-3 (from 5th July 2022 to 5th November 2022), FTS has managed the successful transfer of approximately 400 million files totalling 517 Petabytes of data.
This paper describes how the FTS team has evolved the software and the deployment in order to cope with changes in implementation technologies, increase the efficiency of service, streamline its operations, and to meet the ever changing needs of its user community. We report about the software migration from Python 2 to Python 3, the move from the Pylons web development framework toward Flask and the new database deployment strategy to separate the handling of the critical operations from the long duration monitoring queries. In addition, during 2022 a new HTTP based protocol has been finalised that can now be used between FTS and compatible WLCG tape storage endpoints.
HPC systems are increasingly often used for addressing various challenges in high-energy physics. But often the data infrastructures used in the latter area are not well integrated with infrastructures that include HPC resources. Here we will focus on a specific infrastructure, namely Fenix, which is based on a consortium of 6 leading European supercomputing centres. The Fenix sites are integrated into a common AAI and provide a so-called Archival Data Repository that can be accessed through a Swift API. Fenix was initiated through the Human Brain Project (HBP) but also provides resources to other research communities in Europe.
In this talk, we will report on our efforts to enable the support of Swift in FTS3 and its dependencies GFAL2 and DaviX. We will, in particular, discuss how FTS3 has been integrated into the Fenix AAI, which largely follows the architectural principles of the European Open Science Cloud (EOSC). Furthermore, we show how end-users can use this service through a WebFTS service that has been integrated into the science gateway of the HBP, which is also known as the HBP Collaboratory. Finally, we discuss how transfer commands are automatically distributed over several FTS3 instances to optimise transfer between different Fenix sites.
NA62 is a K meson physics experiment based on a decay-in-flight technique and whose Trigger and Data Acquisition system (TDAQ) is multi-level and network based. A reorganization of both the beam line and the detector is foreseen in the next years to complete and extend the physics reach of NA62. One of the challenging aspects of this upgrade is a significant increase (x4) in the event rate which requires a deep revision of the TDAQ system. This revision includes technological and functional aspects.
The first initiative of the program consists in the upgrade of the hardware trigger processor (L0TP) with a recent platform that offers larger local memory, more computing power and higher transmission bandwidth (L0TP+). The second action is to increase physics selectivity of the trigger processor using different kinds of online processing, both at front-end and concentrator levels, adopting classical and AI approaches for algorithms design.
L0TP+ is implemented on an FPGA device and is configured and controlled by means of a soft CPU core. Testing has been conducted extensively with a parasitic setup which includes network taps and a commodity server to compare trigger decisions on an event-by-event basis, thus reproducing realistic operation conditions with no impact on the experiment schedule. In view of the next data taking period, the positive experience of the parasitic mode can be reused as a development setup to explore new algorithms, test additional features, thus speeding up the TDAQ upgrade.
The backend of the Belle II data acquisition system consists of a high-level trigger system, online storage, and an express-reconstruction system for online data processing. The high-level trigger system was updated to use the ZeroMQ networking library from the old ring buffer and TCP/IP socket, and the new system is successfully operated. However, the online storage and express-reconstruction system use the old type of data transportation. For future maintainability, we expand the same ZeroMQ library-based system to the online storage and express-reconstruction system. At the same time, we introduce two more updates in the backend system. First, online side raw data output becomes compressed ROOT format which is the official format of the Belle II data. The update helps to reduce the bandwidth of the online to offline data transfer and offline-side computing resource usage for data format conversion and compression. Second, high-level trigger output-based event selection is included in the online storage. The event selection allows more statistics of data quality monitoring from the express-reconstruction system. In the presentation, we show the description and test result of the upgrade before applying it to the beam operation and data taking.
The High-Luminosity LHC will open an unprecedented window on the weak-scale nature of the universe, providing high-precision measurements of the standard model as well as searches for new physics beyond the standard model. Such precision measurements and searches require information-rich datasets with a statistical power that matches the high-luminosity provided by the Phase-2 upgrade of the LHC. Efficiently collecting those datasets will be a challenging task, given the harsh environment of 200 proton-proton interactions per LHC bunch crossing. For this purpose, CMS is designing an efficient data-processing hardware trigger (Level-1) that will include tracking information and high-granularity calorimeter information. Trigger data analysis will be performed through sophisticated algorithms such as particle flow reconstruction, including widespread use of Machine Learning. The current conceptual system design is expected to take full advantage of advances in FPGA and link technologies over the coming years, providing a high-performance, low-latency computing platform for large throughput and sophisticated data correlation across diverse sources.
High Energy Photon Source(HEPS)is expected to generate a huge amount of data, which puts extreme pressure on data I/O in computing tasks. Meanwhile, inefficient data I/O significantly affect computing performance.
Firstly, the data reading mode and limitations of computing resources are taken into account,and we propose a method for automatic tuning of storage parameters, such as data block size, for optimizing the data reading speed.
Secondly, we designed a data processing pipeline scheme for reducing I/O latency and maximizing IO bandwidth utilization while processing high-throughput data. The computing task is split into multiple steps, i.e., data loading, data preprocessing, data processing and data writing, which are executed asynchronously and in parallel.
Finally, due to the limited storage, the lossless compression methods are applied for further optimizing the I/O speed. However, it will incur additional performance overhead. Thus, we put forward an intelligent lossless compression method, which judges whether compression is beneficial to data I/O, and compresses the suitable data to reduce I/O footprint and required storage resources.
The CMS data acquisition (DAQ) is implemented as a service-oriented architecture where DAQ applications, as well as general applications such as monitoring and error reporting, are run as self-contained services. The task of deployment and operation of services is achieved by using several heterogeneous facilities, custom configuration data and scripts in several languages. Deployment of all software is carried out by installation of rpms through Puppet management system on physical and virtual machines in computer network. Two main approaches are used to operate and control the life cycle of the different services: short-lived services, such as event building and read-out, are managed using a custom-built infrastructure, while auxiliary, long-running services are managed using systemd. In this work, we restructure the existing system into a homogeneous, scalable cloud architecture adopting a uniform paradigm where all applications are orchestrated in a uniform environment with standardized facilities. In this new paradigm DAQ applications are organized as groups of containers and the required software is packaged into container images. Automation of all aspects of coordinating and managing containers is provided by the Kubernetes environment, where a set of physical and virtual machines is unified in a single pool of compute resources. As opposed to the current system, different versions of the software, including operating system, libraries, and their dependencies, can coexist within the same network host, and can be installed in container images prepared at build time with no need of applying software changes on target machines. In this work we demonstrate that a container-based cloud architecture provides an across-the-board solution that can be applied for DAQ in CMS. We show strengths and advantages of running DAQ applications in a container infrastructure as compared to a traditional application model.
The CMS experiment data acquisition (DAQ) collects data for events accepted by the Level-1 trigger from the different detector systems and assembles them in an event builder prior to making them available for further selection in the High Level Trigger, and finally storing the selected ones for offline analysis. In addition to the central DAQ providing global acquisition functionality, several separate, so-called “MiniDAQ” setups allow operating independent data acquisition runs using an arbitrary subset of the CMS subdetectors.
During Run 2 of the LHC, MiniDAQ setups were running their event builder and high level trigger applications on dedicated resources, separate from those used for the central DAQ. This cleanly separated MiniDAQ setups from the central DAQ system, but also meant limited throughput and a fixed number of possible MiniDAQ setups. In Run 3, MiniDAQ-3 setups share production resources with the new central DAQ system, allowing each setup to operate at the maximum Level-1 rate thanks to the reuse of the resources and network bandwidth.
The configuration management tool defines the assignment of shared resources to subdetectors and provides functionality to evolve it, for example when hardware becomes unavailable, minimizing changes to unaffected parts of the system, in such a way as to not disturb ongoing independent runs. A system has been implemented to automatically synchronize MiniDAQ configurations to that of the central DAQ in order to minimize required operator and expert interventions in case of re-assignment of resources. The configuration management tool further provides expert features needed during the commissioning of the new DAQ system, to enable for example performance tests of most of the resources, concurrently to providing MiniDAQ for the commissioning of selected subdetectors.
We report on the new configuration management features and on the first year of operational experience with the new MiniDAQ-3 system.
The analysis category was introduced in Geant4 almost ten years ago (in 2014) with the aim to provide users with a lightweight analysis tool, available as part of the Geant4 installation without the need to link to an external analysis package. It helps capture statistical data in the form of histograms and n-tuples and store these in files in four various formats. It was already presented at CHEP multiple times, the last time five years ago. In this presentation we will give an update on its evolution since then.
We will present the major redesign in the past two years that allowed introducing a new Generic analysis manager. In particular, we will discuss the advantages of our design choice based on the so- called Non Virtual Interface pattern: the code robustness and stability in the context of the code evolution over almost ten years.
We will also report on new functionalities: a new factory class, Generic analysis manager, that provides more flexibility in the selection of the output file type, saving data in multiple formats from the same simulation run, then on the connection of the analysis to visualization or new support for data object cycles in the upcoming version Geant4 11.1. Finally, we will present the continuous code improvements using static code analysis and sanitizer tools.
For the new Geant4 series 11.X electromagnetic (EM) physics sub-libraries were revised and reorganized in view of requirements for simulation of Phase-2 LHC experiments. EM physics simulation software takes a significant part of CPU during massive production of Monte Carlo events for LHC experiments. We present recent evolution of Geant4 EM sub-libraries for simulation of gamma, electron, and positron transport. Updates of other components of EM physics are also discussed. These developments are included into the new Geant4 version 11.1 (December 2022). The most important modifications concern reorganization of initialization of EM physics and introduction of alternative tracking software. These modifications affect CPU efficiency of any simulation, CPU saving depends on geometry and physics configuration for concrete experimental setup. We will discuss several methods: gamma general process, Woodcock tracking, transportation with multiple scattering process, alternative tracking manager, and new G4HepEm library. These developments provide a ground for implementation of EM particle transport at co-processors and GPU. We also will present very recent updates in physics processes and in configuration of EM physics.
The Circular Electron Positron Collider (CEPC) [1] is one of the future experiments aiming to study the Higgs boson’s properties precisely. For this purpose, excellent track reconstruction and particle identification (PID) performance are required. Such as the tracking efficiency should be around 100%, the momentum resolution should be less than 0.1%, and the Kaon and pion should have 2 sigma separation power for momentum below 20 GeV. To fulfill these requirements, a tracking system combining a silicon tracker and a drift chamber is proposed for the CEPC experiment. Here the drift chamber is not only used for improving track reconstruction performance but also used for excellent PID with cluster counting method[2]. To evaluate the performance of this design carefully, the simulation should be close to the real situation as much as possible.
This contribution presents a refined drift chamber simulation by combining the Geant4 and the Garfield++ [3] simulation in the CEPCSW [4]. The Geant4 is used for traditional particle transportation and interaction simulation in the detector. The Garfield++ aims for detailed simulation in each drift chamber cell including precise ionization simulation, pulse simulation as well as waveform simulation. Due to the extremely time-consuming avalanche process simulation in Garfield++. It is not feasible to simulate the waveform of the whole drift chamber using Garfield++. To solve the barrier, a fast pulse simulation method based on the Normalizing Flow technology [5] is developed which can simulate the pulse’s time and amplitude according to the local position of an ionized electron. The result shows the fast simulation has very high fidelity and more than 2 magnitude speed up can be achieved. To further validate this method, simulating drift time is performed using real data from the BESIII experiment [6]. It shows the simulated drift time distribution is consistent with real data. Last but not least, the track reconstruction performance is shown by using this more realistic drift chamber simulation.
Reference:
[1] CEPC Study Group Collaboration, M. Dong et al., CEPC Conceptual Design Report: Volume 2 - Physics & Detector, arXiv:1811.10545
[2] Jean-Fran¸cois Caron, et al., Improved Particle Identification Using Cluster Counting in a Full-Length Drift Chamber Prototype, 10.1016/j.nima.2013.09.028
[3] Garfield++ Team, https://gitlab.cern.ch/garfield/garfieldpp, 2021. GitLab repository (2021).
[4] CEPCSW Team, CEPCSW prototype repository, https://github.com/cepc/CEPCSW, 2021. GitHub repository (2021)
[5] I. Kobyzev, S. J. D. Prince and M. A. Brubaker, “Normalizing Flows: An Introduction and Review of Current Methods,” in IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 43, no. 11, pp. 3964-3979, 1 Nov. 2021, doi: 10.1109/TPAMI.2020.2992934.
[6] BESIII Collaboration, Design and Construction of the BESIII Detector. Nucl.Instrum.Meth.A614:345-399,2010
MoEDAL (the Monopole and Exotics Detector at the LHC) searches directly magnetic monopoles at the Interaction Point 8 of the Large Hadron Collider (LHC). As an upgrade of the experiment an addition, MAPP (MoEDAL Apparatus for Penetrating Particles) detector extends the physics reach by providing sensitivity to milli-charged and long-lived exotic particles. The MAPP detectors are scintillator detectors, and they are planned, or already installed in service tunnels of the LHC, locating from 50 to 100 meters from the IP8 [1].
To study and to support the data analysis of the detectors, a complete simulation model of the detector regions was developed. This Geant4 [2] based model consists of all tunnel and accelerator components between the detectors and the IP8, and the material budget, about 100 meters thick ground layer above the tunnels for cosmic background studies. In addition, new physics models describing the interactions of exotic particles, such as millicharged particles, has been implemented in the model.
The geometry description of the model utilises CAD to GDML conversion and parser of Geant4. This allowed to construct modular elements which can be changed without the need of recompiling the software code. In addition, the physics processes are handled in stacks which allows to limit the required computing resources. Various physics generators, such as Pythia8 [3], are used as a primary input.
In this contribution I will discuss about the development of the geometry models and present the new physics models and interactions that are used in the simulations. I will also show some examples of the detector response for various types of physics models.
References:
[1] B. Acharya et al, MoEDAL-MAPP, an LHC Dedicated Detector Search Facility, in Proceedings of 2022 Snowmass Summer Study (2022) arXiv:2209.03988 [hep-ph].
[2] J. Allison et al., Recent developments in Geant4, Nucl. Instr. Meth. A 835 (2016) p. 186-225.
[3] T. Sjostrand, The Pythia event generator: Past, present and future, Comput. Phys. Comm. 246 (2020) 106910 arXiv:1907.09874v1 [hep-ph].
FullSimLight is a lightweight, Geant4-based command line
simulation utility intended for studies of simulation performance. It
is part of the GeoModel toolkit (geomodel.web.cern.ch) which has been
stable for more than one year. The FullSimLight component
has recently undergone renewed development aimed at extending its
functionality. It has been endowed with a GUI for fast, transparent,
and foolproof configuration and with a plugin mechanism allowing users
and developers with diverse goals to extend and customize the
simulation. Geometry and event input can be easily specified on the
fly, allowing rapid evaluation of different geometry options and their
effect on simulation performance. User actions and sensitive detectors
can also be loaded through the new plugin mechanism, allowing for
customization of Geant4 processing and hit production. The geometry
explorer (gmex), in a parallel development, has been enhanced with
the capability of visualizing FullSimLight track and hit output.
FullSimLight, brought to you by the ATLAS collaboration, is an
experiment independent software tool.
In this contribution we report status of the CMS Geant4 simulation and the prospects for Run-3 and Phase-2.
Firstly, we report about our experience during the start of Run-3 with Geant4 10.7.2, the common software package DD4hep for geometry description, and VecGeom run time geometry library. In addition, FTFP_BERT_EMM Physics List and CMS configuration for tracking in magnetic field have been utilized. For the first time, for the Grid mass production of Monte Carlo, this combination of components is used.
Further simulation improvements are under development targeting Run-3 such as the switch to the new Geant4 11.1 in production, that provides several features important for the optimization of simulation, for example the new transportation process with built-in multiple scattering, neutron general process, custom tracking manager, G4HepEm sub-library, and others.
We will present evaluation of various options, validation results, and the final choice of simulation configuration for 2023 production and beyond. The performance of the CMS full simulation for Run-2 and Run-3 will also be discussed.
CMS development plan for the Phase-2 Geant4 based simulation is very ambitious, and it includes a new geometry description, physics, and simulation configurations. The progress on new detector descriptions and full simulation will be presented as well as the R&D in progress to reduce compute capacity needs.
Finally, the status of the R&D for using Celeritas and Adept GPU prototypes in CMSSW will be presented.
The Electron Ion Collider (EIC) collaboration and future experiment is a unique scientific ecosystem within Nuclear Physics as the experiment starts right off as a cross-collaboration from Brookhaven National Lab (BNL) & Jefferson Lab (JLab). As a result, this muti-lab computing model tries at best to provide services accessible from anywhere by anyone who is part of the collaboration. While the computing model for the EIC is not finalized, it is anticipated that the computational and storage resources will be made accessible to a wide range of collaborators across the world. The use of federated ID seems to be a critical element to the strategy of providing such services, allowing seamless access to each lab site computing resources. However, providing Federated access to a Federated storage is not a trivial matter and has its share of technical challenges.
In this contribution, we will focus on the steps we took towards the deployment of a distributed object storage system that integrates with Amazon S3 and Federated ID. We will first cover for and explain the first stage storage solutions provided to the EIC during the detector design phase. Our initial test deployment consisted of Lustre storage using MinIO, hence providing an S3 interface. High Availability load balancers were added later to provide the initial scalability it lacked. Performance of that system will be shown. While this embryonic solution worked well, it had many limitations. Looking ahead, the Ceph object storage is considered a top-of-the-line solution in the storage community - since the Ceph Object Gateway is compatible with the Amazon S3 API out of the box, our next phase will use a native S3 storage. Our Ceph deployment will consist of erasure coded storage nodes to maximize storage potential along with multiple Ceph Object Gateways for redundant access. We will compare performance of our next stage implementations. Finally, we will present how to leverage OpenID Connect with the Ceph Object Gateway’s to enable Federated ID access.
We hope this contribution will serve the community needs as we move forward with cross-lab collaborations and the need for Federated ID access to distributed compute facilities.
Rucio, the data management software initially developed for ATLAS, has been in use at Belle II since January 2021. After the transition to Rucio, new features and functionality were implemented in Belle II grid tools based on Rucio, to improve the experience of grid users. The container structure in the Rucio File Catalog enabled us to define collections of arbitrary datasets, allowing the simple definition of official datasets for physics analyses that result in a reduction of potential mistakes and pre-analysis work for users. Other features, including asynchronous replication, deletion, and direct resolution of file level path information, have improved the experience of analysis on the grid at Belle II. We will describe how the implementation in the Belle II computing architecture was performed to exploit the features from Rucio and how it has enhanced the user experience for analysts.
A critical challenge of performing data transfers or remote reads is to be fast and efficient as possible while, at the same time, keeping the usage of system resources as low as possible. Ideally, the software that manages these data transfers should be able to organize them so that one can have them run up to the hardware limits. Significant portions of LHC analysis use the same datasets, running over each file or dataset multiple times. By utilizing "on-demand" based regional caches, we can improve CPU Efficiency and reduce the wide area network usage. Speeding up user analysis and reducing network usage (and hiding latency from jobs by caching most essential files on demand) are significant challenges for HL-LHC, where the data volume increases to an exabyte level. In this paper, we will describe our journey and tests with the CMS XCache project (SoCal Cache), which will compare job performance and CPU efficiency using different storage solutions (Hadoop, Ceph, Local Disk, Named Data Networking). It will also provide insights into our tests over a wide area network and possible storage and network usage savings.
In recent years, advanced and complex analysis workflows have gained increasing importance in the ATLAS experiment at CERN, one of the large scientific experiments at the Large Hadron Collider (LHC). Support for such workflows has allowed users to exploit remote computing resources and service providers distributed worldwide, overcoming limitations on local resources and services. The spectrum of computing options keeps increasing across WLCG resources, volunteer computing, high-performance and leadership computing facilities, commercial clouds, and emerging service levels like Platform-as-a-Service (PaaS), Container-as-a-Service (CaaS) and Function-as-a-Service (FaaS), each one providing new advantages and constraints. Users can significantly benefit from these providers, but at the same time, it is cumbersome to deal with multiple providers even in a single analysis workflow with fine-grained requirements coming from their applications' nature and characteristics.
In this presentation we will first highlight issues in distributed heterogeneous computing, such as the insulation of users from the complexities of distributed heterogeneous providers, complex resource provisioning for CPU and GPU hybrid applications, integration of PaaS, CaaS, and FaaS providers, smart workload routing, automatic data placement, seamless execution of complex workflows, interoperability between pledged and user resources, and on-demand data production. We will then present solutions developed in ATLAS with the Production and Distributed Analysis system (PanDA system) and future challenges for LHC Run4.
The computing resources supporting the LHC experiments research programmes are still dominated by x86 processors deployed at WLCG sites. This will however evolve in the coming years, as a growing number of HPC and Cloud facilities will be employed by the collaborations in order to process the vast amounts of data to be collected in the LHC Run 3 and into the HL-LHC phase. Compute power in these facilities typically includes a significant (or even dominant) fraction of non-x86 components, such as alternative CPU architectures (ARM, Power) and a variety of GPU specifications. Using these heterogeneous resources efficiently will be therefore essential for the LHC collaborations reaching their scientific goals. The Submission Infrastructure (SI) is a central element in the CMS Offline Computing model, enabling resource acquisition and exploitation by CMS data processing, simulation and analysis tasks. The SI is implemented as a set of federated HTCondor dynamic pools, which must therefore be adapted to ensure access and optimal usage of alternative processors and coprocessors such as GPUs. Resource provisioning and workload management tools and strategies in use by the CMS SI team must take into account questions such as the optimal level of granularity in the description of the resources and how to prioritize CMS diversity of workflows in relation to the new resource mix. Some steps in this evolution towards profiting from this higher resource heterogeneity have been already taken. For example, CMS is already opportunistically using a pool of GPU slots provided mainly at the CMS WLCG sites. Additionally, Power processors have been validated for CMS production at the Marconi100 cluster at CINECA. This contribution will describe the updated capabilities of the SI to continue ensuring the efficient allocation and use of computing resources by CMS, despite their increasing diversity. The next steps towards a full integration and support of heterogeneous resources according to CMS needs will also be reported.
Cloudscheduler is a system to manage resources of local and remote compute clouds and makes those resources available to HTCondor pools. It examines the resource needs of idle jobs, then starts virtual machines (VMs) sized to suit those resource needs on allowed clouds with available resources. Using yaml files, cloudscheduler then provisions the VMs during the boot process with all necessary tools needed to register with HTCondor and run the experiment's jobs. Although we have run cloudscheduler in its first version for ATLAS and Belle-II workloads successfully for more than 10 years, we developed cloudscheduler version 2 (CSV2), a complete overhaul and modernization of cloudscheduler. We published the technical design of CSV2 in 2019, however, many features have been added since then and the system is used successfully in production for Belle-II, ATLAS, DUNE, and BaBar. In addition to using CSV2 as a WLCG grid site, we also run it as a service for other WLCG grid sites, and the Canadian Advanced Network for Astronomical Research (CANFAR) group uses its own instance of CSV2 for their astronomy workload. In this talk, we report on our experience in operating CSV2 for the different experiment's jobs from a user's and administrator's point of view, running on up to 10,000 cores across all experiments and clouds in North America, Australia, and Europe. We will also report on how to correctly account for the resource usage in the APEL system. CSV2 can be used with its own HTCondor system, but it can also extend an existing HTCondor system with cloud resources, for example in times of high demand of batch computing resources. We will detail how projects can be created and integrated with an existing or new HTCondor system, and how the monitoring works. We will also report on the integration of different clouds, as well as using the integrated opportunistic system. CSV2’s integrated opportunistic system allows the use of the same cloud for different experiments, giving one experiment the preferred usage and others an opportunity to make temporary use of idle resources. In addition, we report on how we worked with different cloud administrators to allow opportunistic use of idle cloud resources, managed by the cloud administrators through cloud metadata.
EPOS 4 is the last version of the high-energy collision event generator EPOS, released publicly in 2022. It was delivered with improvements on several aspects, whether about the theoretical bases on which it relies, how they are handled technically, or regarding user's interface and data compatibility.
This last point is especially important, as part of a commitment to provide the widest possible use. In this regard, a new output data format have been implemented, based on the HepMC standard libraries. This feature enables in particular the analysis of EPOS simulations with RIVET, an analysis and validation toolkit for Monte Carlo event generators, with recent major upgrades on concerning heavy-ion analysis methods. In order to take advantage of this, the use of RIVET has been implemented directly in the EPOS analysis machinery, ensuring an easy and fast solution for comparison with experimental data, beneficial for both developers and users. We will hence present in this talk the details of this implementation and the results obtained thanks to it.
A mechanism to store in databases all the parameters needed to simulate the detectors response to physics interactions is presented. This includes geometry, materials, magnetic field, electronics.
GEMC includes a python API to populate the databases, and the software to run the Monte-Carlo simulation. The engine is written in C++ and uses Geant4 for the passage of particles through matter.
An overview of the software, and its usage will be shown, with examples on how to build geometry, handle geometry variations, and provide realistic electronic response.
The usage of GEMC at Jefferson Lab in the CLAS12 experimental program will be showcased.
The LHCb software has undergone a major upgrade in view of data taking with higher luminosity in Run3 of the LHC at CERN.
The LHCb simulation framework, Gauss, had to be adapted to follow the changes in modern technologies of the underlying experiment core software and to introduce new simulation techniques to cope with the increase of the required amount of simulated data. Additional constraints come from the fact that Gauss also relies on external simulation libraries.
The new version of Gauss is based on a newly developed experiment agnostic simulation framework, called Gaussino. This new software is based on the Gaudi data processing framework and encapsulates generic simulation components. Gaussino provides components and interfaces for High Energy Physics generators, e.g. Pythia. It relies on the Geant4 toolkit for detector simulation and provides a fast simulation interface to replace the Geant4 physics processes in given sub-detectors with parametric models, including deep learning based options. Geometry layouts can be provided through DD4Hep or experiment-specific detector description tools. A built-in mechanism to define simple volumes at configuration time is also available. Gaussino ensures a consistent multi-threaded execution between the various components and the underlying Gaudi infrastructure.
Following an overview of the structure and functionality of Gaussino we will describe how the new version of Gauss exploits the Gaussino infrastructure to provide what required for the simulation(s) of LHCb experiment.
Finally we will show recent developments and performance of the new software as well as first experience of using it to generate simulated samples in the LHCb production system.
Gaussino is a new simulation experiment-independent framework based on the Gaudi data processing framework. It provides generic core components and interfaces to build a complete simulation application: generation, detector simulation, geometry, monitoring, and saving of the simulated data. Thanks to its highly configurable and extendable components Gaussino can be used both as a toolkit and a stand-alone application. It provides implementations for software components widely used by the High Energy Physics community, e.g. Pythia and Geant4. Geometry layouts can be provided through DD4Hep or experiment-specific software. A built-in mechanism is available to define simple volumes at configuration time and ease the development cycle. Inspections of the geometry and simulated data can be performed through Geant4 visualization driver accessible in Gaussino. It is also possible to save objects for visualising them a posteriori with Phoenix. We will show how Gaussino can be first used to try out new detector ideas and increasing the complexity of the geometry and physics processes can provide the foundation for a complete experiment simulation where the same detector can be used and its physics performance evaluated. The possibility of retrieving custom information from any place in the detector also allows to obtain samples for proposed additions to experimental setup as well as training datasets for studies involving machine learning, such as fast simulation models, for which use Gaussino provides a dedicated interface.
LCIO is a persistency framework and event data model originally developed to foster closer collaboration among the international groups conducting simulation studies for future linear colliders. In the twenty years since its introduction at CHEP 2003 it has formed the backbone for ILC and CLIC physics and detector studies. It has also been successfully employed to study and develop other collider and fixed-target experiments, as well has having been adopted by several detector R&D groups such as CALICE. It has been a remarkably successful collaborative development that has served a number of disparate communities. We intend to discuss the history of the development of LCIO and show how it is being used in simulation studies, testbeam campaigns and running experiments today, a full two decades after its introduction.
Modern HEP workflows must manage increasingly large and complex data collections. HPC facilities may be employed to help meet these workflows' growing data processing needs. However, a better understanding of the I/O patterns and underlying bottlenecks of these workflows is necessary to meet the performance expectations of HPC systems.
Darshan is a lightweight I/O characterization tool that captures concise views of HPC application I/O behavior. It intercepts application I/O calls at runtime, records file access statistics for each process, and generates log files detailing application I/O access patterns.
Typical HEP workflows include event generation, detector simulation, event reconstruction, and subsequent analysis stages. A study of the I/O behavior of the ATLAS simulation and DAOD_PHY/DAOD_PHYSLITE production, CMS simulation, and DUNE analysis workload using Darshan are presented. Characterization of the various stages at scale would guide the further tuning of the I/O patterns with real HEP workloads to better inform storage capabilities requirements at facilities, uncover the I/O bottlenecks in current workflows when deployed at scale, and provide recommendations for data format and access patterns for future HEP workloads.
We present tools for high-performance analysis written in pure Julia, a just-in-time (JIT) compiled dynamic programming language with a high-level syntax and performance. The packages we present center around UnROOT.jl, a pure Julia ROOT file I/O package that is optimized for speed, lazy reading, flexibility, and thread safety.
We discuss what affects performance in Julia, the challenges, and their solutions during the development of UnROOT.jl. We highlight type stability as a challenge and discuss its implication whenever any “compilation” happens (incl. Numba, Jax, C++) as well as Julia’s specific ones.
We demonstrate the performance and “easy to use” claim by comparing UnROOT.jl against popular alternatives (RDataFrame, Uproot, etc.) in medium-size realistic benchmarks, comparing both performance and code complexity.
Finally, we also showcase real ATLAS analysis workflows both locally and on an HPC system, highlighting the composability of UnROOT.jl with multi-thread/process and out-of-core distributed computing libraries.
We will describe how ServiceX, an IRIS-HEP project, generates C++ or python code from user queries and orchestrates thousands of experiment-provided docker containers to filter and select event data. The source datafiles are identified using Rucio. We will show how the service encapsulates best practice for using Rucio and helps inexperienced analysers get up to speed quickly. The data is returned as flat root or parquet files in an object store. We will show how ServiceX is deployed into a modern analysis facility as part of a scalable analysis workflow. Recent work includes support for CMS MiniAOD files, robust failover across file replicas, CERN OpenData support, Autoscaling of worker pods.
Awkward Arrays is a library for performing NumPy-like computations on nested, variable-sized data, enabling array-oriented programming on arbitrary data structures in Python. However, imperative (procedural) solutions can sometimes be easier to write or faster to run. Performant imperative programming requires compilation; JIT-compilation makes it convenient to compile in an interactive Python environment.
Several functions in Awkward Arrays JIT-compile a user’s code into executable machine code. They use several different techniques, but reuse parts of each others’ implementations.
We discuss the techniques used to achieve the Awkward Arrays acceleration with JIT-compilation, focusing on RDataFrame, cppyy, and Numba, particularly Numba on GPUs:
In particle physics, data analysis frequently needs variable-length, nested data structures such as arbitrary numbers of particles per event and combinatorial operations to search for particle decay. Arrays of these data types are provided by the Awkward Array library.
The previous version of this library was implemented in C++, but this impeded its ability to grow. Thus, driven by this limitation, Awkward Array has been deeply restructured to enable its integration with other libraries while preserving its existing high-level API and C++ performance-critical algorithms. In the latest 2.0 release, 50k LoC of C++ have been converted to 20 kLoC of Python.
In this talk, we present the design and features of Awkward Array 2.0 and showcase the full ecosystem that developed as a result of the library’s restructuring work. First, this endeavour has laid the groundwork for full CUDA integration (Awkward Arrays can be copied to a GPU). Second, conversion facilities are now available between Awkward Arrays and ROOT’s RDataFrame, Arrow and Parquet. Finally, multiple libraries have been integrated:
Awkward Array 2.0 was released at the end of 2022 and is available for physics research now.
Recent developments of HEP software allow novel approaches to physics analysis workflows. The novel data delivery system, ServiceX, can be very effective when accessing a fraction of large datasets at remote grid sites. ServiceX can deliver user-selected columns with filtering and run at scale. We will introduce the ServiceX data management package, ServiceX DataBinder, for easy manipulations of ServiceX delivery requests and delivered data using a single configuration file. We will show various practical use cases within analysis pipelines that range from a data delivery of a few columns for machine learning study to a data delivery for full-scale physics analysis.
Cling is a clang/LLVM-based, high-performance C++ interpreter originating from HEP. In ROOT, cling is used as the basis for language interoperability, it provides reflection data to ROOT's I/O system, and enables RDataFrame's dynamic type-safe interfaces.
Cling regularely moves to more recent LLVM versions to bring new features and support for new language standards. The recent LLVM 13 upgrade introduces support for C++20, including new language features such as C++ concepts. We describe what else the new LLVM infrastructure has to offer, including updated CUDA support and a more reliable and customizable JIT facility. In addition, we describe the recently-added Cling tooling support for performance tracing and debugging, making interpreted code a good citizen of the C++ ecosystem. Given Cling's sensitivity to bugs in the system stacks (compilers, ABI, standard libraries), we provide some insights on the challenges faced on the way to support Apple's ARM architecture. Finally, we share details on how to get the fastest interpreted code out of Cling, be it analysis or reconstruction code.
High energy physics experiments are pushing forward the precision measurements and searching for new physics beyond standard model. It is urgent to simulate and generate mass data to meet requirements from physics. It is one of the most popular areas to make good use of existing power of supercomputers for high energy physics computing. Taking the BESIII experiment as an illustration, we deploy the offline software BOSS into the top-tier supercomputer "Tianhe-II" with the help of Singularity. With very limited internet connection bandwidth and without root privilege, we synchronize and maintain the simulation software up to date through CVMFS successfully, and an acceleration rate in a comparison of HPC and HTC is realized for the same large-scale task. There are two creative ideas to be shared in the community: on one hand, common users constantly meet problems in the real-time internet connection and the conflict of loading locker. We solve these two problems by a deployment of a squid server and using fuse in memory in each computing node. On the other hand, we provide a MPI python interface for high throughput parallel computation in Tianhe-II. Meanwhile, the program to deal with data output is also specially aligned so that there is no queue issue in the I/O task. The acceleration rate in simulation reaches 80% so far, as we have done the simulation tests up to 15 K processes in parallel.
The CMS experiment is working to integrate an increasing number of High Performance Computing (HPC) resources into its distributed computing infrastructure. The case of the Barcelona Supercomputing Center (BSC) is particularly challenging as severe network restrictions prevent the use of CMS standard computing solutions. The CIEMAT CMS group has performed significant work in order to overcome these constraints and make BSC resources available to CMS. The developments include adapting the workload management tools, replicating the CMS software repository to BSC storage, providing an alternative access to detector conditions data, and setting up a service to transfer produced output data to a nearby storage facility. In this work, we discuss the current status of this integration activity, and present recent developments, such as a front-end service to improve slot usage efficiency, and an enhanced transfer service that supports the staging of input data for workflows at BSC. Moreover, significant efforts have been devoted to improving the scalability of the deployed solution, automating its operation, and simplifying the matchmaking of CMS workflows that are suitable for execution at BSC.
With advances in the CMS CMSSW framework to support GPU, culminating with the deployment of GPU in the Run-3 HLT, CMS is also starting to look at integrating GPU resources into CMS Offline Computing as well. At US HPC Facilities a number of very large HPC with GPU have either just become available or will become available soon, offering opportunities for CMS if we would be able to make use of them. We are reporting our experience with commissioning of GPU resources at OLCF Summit and NERSC Perlmutter and using them for GPU-enabled CMS data reconstruction.
The NSF-funded Scalable CyberInfrastructure for Artificial Intelligence and Likelihood Free Inference (SCAILFIN) project has developed and deployed artificial intelligence (AI) and likelihood-free inference (LFI) techniques and software using scalable cyberinfrastructure (CI) built on top of existing CI elements. Specifically, the project has extended the CERN-based REANA framework, a cloud-based data analysis platform deployed on top of Kubernetes clusters that was originally designed to enable analysis reusability and reproducibility. REANA is capable of orchestrating extremely complicated multi-step workflows, and uses Kubernetes clusters both for scheduling and distributing container-based workloads across a cluster of available machines, as well as instantiating and monitoring the concrete workloads themselves. This work describes the the components that were developed in order to enable large scale deployment on High Performance Computing (HPC) resources. Scaling and performance results using large-scale MadMiner AI/LFI training workflows on a variety of large HPC sites will be presented.
LHCb (Large Hadron Collider beauty) is one of the four large particle physics experiments aimed at studying differences between particles and anti-particles and very rare decays in the charm and beauty sector of the standard model at the LHC. The Experiment Control System (ECS) is in charge of the configuration, control, and monitoring of the various subdetectors as well as all areas of the online system, and it is built on top of hundreds of Linux virtual machines (VM) running on a Red Hat Enterprise Virtualization cluster. For such a mission-critical project, it is essential to keep the system operational; it is not possible to run the LHCb’s Data Acquisition without the ECS, and a failure would likely mean the loss of valuable data. In the event of a disruptive fault, it is important to recover as quickly as possible in order to restore normal operations. In addition, the VM’s lifecycle management is a complex task that needs to be simplified, automated, and validated in all of its aspects, with particular focus on deployment, provisioning, and monitoring. The paper describes the LHCb’s approach to this challenge, including the methods, solutions, technology, and architecture adopted. We also show limitations and problems encountered, and we present the results of tests performed.
The ATLAS Trigger and Data Acquisition (TDAQ) High Level Trigger (HLT) computing farm contains 120,000 cores. These resources are critical for online selection and collection of collision data in the ATLAS experiment during LHC operation. Since 2013, during longer period of LHC inactivity these resources are being used for offline event simulation via the "Simulation at Point One" project (Sim@P1). With the recent start of LHC Run 3 and the flat computing budget expected in the near future, finding ways to maximize the resource utilization efficiency is of paramount importance. Recent improvements in the ATLAS software stack can potentially allow the utilization of the Sim@P1 even during LHC operation for the duration of the LHC inter-fill gaps. While previous papers on the Sim@P1 project were emphasizing the technical implementation details, the current contribution is presenting results of a variety of tests that led to the optimal configuration of the job submission infrastructure which would allow the use of Sim@P1 during LHC Run 3.
Communicating the science and achievements of the ATLAS Experiment is a core objective of the ATLAS Collaboration. This talk will explore the range of communication strategies adopted in ATLAS communications, with particular focus on how these have been impacted by the COVID-19 pandemic. In particular, an overview of ATLAS’ digital communication platforms will be given – with focus on social media, YouTube and Virtual Visits – and the effect on target audiences evaluated with best practices are shared.
The International Particle Physics Outreach Group (IPPOG) is a network of scientists, science educators and communication specialists working across the globe in informal science education and public engagement for particle physics. The primary methodology adopted by IPPOG includes the direct participation of scientists active in current research with education and communication specialists, in order to effectively develop and share best practices in outreach. IPPOG member activities include the International Particle Physics Masterclass programme, International Day of Women and Girls in Science, Worldwide Data Day, International Muon Week and International Cosmic Day organisation, and participation in activities ranging from public talks, festivals, exhibitions, teacher training, student competitions, and open days at local institutes. These independent activities, often carried out in a variety of languages to public with a variety of backgrounds, all serve to gain the public trust and to improve worldwide understanding and support of science. We present our vision of IPPOG as a strategic pillar of particle physics, fundamental research and evidence-based decision-making around the world.
Sudhir Malik, Peter Elmer, Adam LaMee, Ken Cecire
The NSF-funded IRIS-HEP "Training, Education & Outreach" program and QuarkNet are partnering to enable and expand software training for the high school teachers with a goal to tap, grow and diversify the talent pipeline from K-12 students for future cyberinfrastructure. IRIS-HEP (https://iris-hep.org/) is a software institute that aims to develop the state-of-the-art software cyberinfrastructure for the High Luminosity Large Hadron Collider (HL-LHC) at CERN and other planned HEP experiments of the 2020’s. QuarkNet (https://quarknet.org/) provides professional development to K-12 physics teachers in particle physics content and methods. The two projects have recently built a collaborative relationship where a well-established community of QuarkNet K-12 teachers has access to a wide training on software tools via its Data and Coding Camps supported by IRIS-HEP. The talk highlights the synergistic efforts and future plans.
UKRI/STFC’s Scientific Computing Department (SCD) runs a vibrant range of computing related public engagement activities. We benefit form the work done by the National Labs public engagement team to develop a well articulated PE strategy, and an accompanying evaluation framework, including the idea of defining formal generic learning outcomes (GLOs).
This paper presents how this combination has supported better decision making when applying limited human and financial resources. The evaluation framework helps us ensure our activities are effective and GLOs help ensure activities communicate what we intend.
Further these all combined to enable a rapid pivot to fully online PE during the pandemic, improving reach in many areas. As we return to face-to-face PE activities we also have a new repertoire of remote activities that are accessible to populations unable to travel to our facilities.
The Virtual Visit service run by the ATLAS Collaboration has been active since 2010. The ATLAS Collaboration has used this popular and effective method to bring the excitement of scientific exploration and discovery into classrooms and other public places around the world. The programme, which uses a combination of video conferencing, webcasts, and video recording to communicate with remote audiences, has already reached tens of thousands of viewers, in a large number of languages, from tens of countries across all continents. We present a summary of the ATLAS Virtual Visit service that is currently in use – including a new booking system and hand-held video conference setup from the ATLAS cavern – and present a new system that is being installed in the ATLAS Visitors Centre. In addition, we show the reach of the programme over the last few years.
Machine learning (ML) has become ubiquitous in high energy physics (HEP) for many tasks, including classification, regression, reconstruction, and simulations. To facilitate development in this area, and to make such research more accessible, and reproducible, we require standard, easy-to-access, datasets and metrics. To this end, we develop the open source Python JetNet library with easily accessible, standardised interfaces for particle cloud datasets, implementations for HEP evaluation and loss metrics, and more useful tools for ML in HEP. While still in the development stage, JetNet has already been widely used for several ML projects at the LHC, averaging 2,000 downloads per month, and being prominently featured at recent conferences such as ML4Jets, illustrating its significant contribution to making ML in HEP research more FAIR.
The newly formed EPIC Collaboration has recently laid the foundations of its software infrastructure. Noticeably, several forward-looking aspects of the software are favorable for Artificial Intelligence (AI) and Machine Learning (ML) applications and utilization of heterogeneous resources. EPIC has a unique opportunity to integrate AI/ML from the beginning: the number of AI/ML activities is anticipated to grow in the coming months (spanning from, e.g., design and other automated procedures to simulation, reconstruction, and particle identification); in the long-term, AI/ML will likely permeate and contribute to multiple aspects of near real-time analyses. This talk will provide an overview of all ongoing activities regarding AI/ML for EPIC and will present plans and steps forward for future implementations
The recent developments in ROOT/TMVA focus on fast machine learning inference, which enables analysts to deploy their machine learning models rapidly on large scale datasets. A new tool has been recently developed, SOFIE, allowing for generating C++ code for evaluation of deep learning models, which are trained from external tools such as Tensorflow or PyTorch.
While Python-based deep learning frameworks for training models in GPU environments develop and mature, SOFIE is a good solution that allows easy integration of inference of trained models into conventional C++ and CPU-based scientific computing workflows. Using this new tool, SOFIE, it is easier to integrate Machine Learning model evaluation in HEP data analysis and in particular when using tools such as RDataFrame.
We will present the recent developments of SOFIE, notably one of the latest features, the support for Graph Neural Networks. In the previous CHEP conference we have introduced SOFIE showing the support for some basic Deep learning operators. Now we have extended the support for parsing and generating C++ code for several deep learning operators commonly used in HEP and represented by the ONNX standard. Other types of architectures typically used in HEP are the Graph Neural Networks. These networks cannot easily and efficiently be represented with ONNX operators. Therefore we have developed a set of C++ classes that can represent message passing GNN architectures, which are created with common tools used in HEP such as PyTorch geometric and the Graph Nets library from DeepMind. From these classes it is then possible to generate efficient C++ code for inference of GNN’s which can be easily integrated in CPU based workflows.
We demonstrate these current capabilities of SOFIE with benchmarks in evaluating some machine leaning models used by LHC experiments.
Neural Networks (NN) are often trained offline on large datasets and deployed on specialized hardware for inference, with a strict separation between training and inference. However, in many realistic applications the training environment differs from the real world or data arrive in a streaming fashion and are continuously changing. In these scenarios, the ability to continuously train and update NN models is desirable.
Continual learning (CL) algorithms allow training of models over a stream of data. CL algorithms are often designed to work in constrained settings, such as limited memory and computational power, or limitations on the ability to store past data (e.g., due to privacy concerns or memory requirements). The most basic online learning suffers from “catastrophic forgetting”, where knowledge from initial or previous training is lost. CL aims to mitigate this effect through the use of different learning algorithms.
High-energy physics experiments are developing intelligent detectors, with algorithms running on computer systems located close to the detector to meet the challenges of increased data rates and occupancies. The use of NN algorithms in this context is limited by changing detector conditions, such as degradation over time or failure of an input signal which might cause the NNs to lose accuracy leading, in the worst case, to loss of interesting events.
CL has the potential to solve this issue, using large amounts of continuously streaming data to allow the network to recognize changes to learn and adapt to detector conditions. It has the potential to outperform traditional NN training techniques as not all possible scenarios can be predicted and modeled in static training data samples.
However, NN training is computationally expensive and when combined with the strict timing requirements of embedded processors deployed close to the detector, current state-of-the-art offline approaches cannot be directly applied in real-time systems. Alternatives to typical backpropagation-based training that can be deployed on FPGAs for real-time data processing are presented, and their computational and accuracy characteristics are discussed in the context of HL-LHC.
The findable, accessible, interoperable, and reusable (FAIR) data principles have provided a framework for examining, evaluating, and improving how we share data with the aim of facilitating scientific discovery. Efforts have been made to generalize these principles to research software and other digital products. Artificial intelligence (AI) models---algorithms that have been trained on data rather than explicitly programmed---are an important target for this because of the ever-increasing pace with which AI is transforming scientific and engineering domains.
We propose a practical definition of FAIR principles for AI models, create a FAIR AI project template that promotes adherence to these principles, and introduce a framework to quantify whether an AI model is FAIR. We demonstrate how to implement these principles using a concrete example from experimental high energy physics: a graph neural network for identifying Higgs bosons decaying to bottom quarks. We study the robustness of these FAIR AI models and their portability across hardware architectures and software frameworks and report new insights on the interpretability of AI predictions by studying the interplay between FAIR datasets and AI models. Enabled by publishing FAIR AI models, these studies pave the way toward reliable and automated AI-driven scientific discovery.
The high-energy physics community is investigating the feasibility of deploying more machine-learning-based solutions on FPGAs to meet modern physics experiments' sensitivity and latency demands. In this contribution, we introduce a novel end-to-end procedure that utilises a forgotten method in machine learning, i.e. symbolic regression (SR). It searches equation space to discover algebraic relations approximating a dataset. We use PySR (software for uncovering these expressions based on evolutionary algorithms) and extend the functionality of hls4ml (a package for machine learning inference in FPGAs) to support PySR-generated expressions for resource-constrained production environments. Deep learning models often optimise the top metric by pinning the network size because vast hyperparameter space prevents extensive neural architecture search. Conversely, SR selects a set of models on the Pareto front, which allows for optimising the performance-resource tradeoff directly. By embedding symbolic forms, our implementation can dramatically reduce the computational resources needed to perform critical tasks. We validate our procedure on multiple physics benchmarks as an alternative to deep learning and decision tree models.
To increase the science rate for high data rates/volumes, Thomas Jefferson National Accelerator Facility (JLab) has partnered with Energy Sciences Network (ESnet) to define an edge to data center traffic shaping/steering transport capability featuring data event-aware network shaping and forwarding.
The keystone of this ESnet JLab FPGA Accelerated Transport (EJFAT) is the joint development of a dynamic compute work Load Balancer (LB) of UDP streamed data. The LB's centerpiece is a Field Programmable Gate Array (FPGA). The FPGA executes a dynamically configurable, low fixed latency, LB data plane featuring real-time packet redirection at high throughput. It also executes a control plane running on its host computer that monitors network and compute farm telemetry in order to make dynamic AI/ML guided decisions. These decisions include determining destination compute host redirection / load balancing.
The LB provides for three forms of scaling. It provides horizontal scale by adding more FPGAs for increased bandwidth. Second it sets the number of core compute hosts independent of the number of source DAQs. Thirdly it allows for a flexible number of CPUs and threads per host, treating each receiving thread as an independent LB destination. The LB provides seamless integration of edge / core computing to support direct experimental data processing.Immediate use will be in JLab science programs and others such as the EIC (Electron Ion Collider). Data centers of the future will need high throughput and low latency for both live streamed and recorded data for running experiment data acquisition analysis and data center use cases.
EJFAT is in development for production use within DOE. When completed, it will have an operational impact for integrated research infrastructure as called for in planning documents for Exascale, Nuclear Physics, and Scientific Computing. It demonstrates a new load balancing architecture.
Field Programmable Gate Arrays (FPGAs) are playing an increasingly important role in the sampling and data processing industry due to their intrinsically highly parallel architecture, low power consumption, and flexibility to execute custom algorithms. In particular, the use of FPGAs to perform machine learning inference is increasingly growing thanks to the development of high-level synthesis projects that abstract the complexity of HDL programming.
In this presentation we will describe our experience extending KServe predictors, an emerging standard for ML (Machine Learning) model inference as a service on kubernetes. This project will support a custom workflow capable of loading and serving models on-demand on top of FPGAs. A key aspect is that the proposed approach makes the firmware generation transparent, often an obstacle to a widespread FPGA adoption. We will detail how the proposed system automates both the synthesis of the HDL code and the generation of the firmware, starting from a high-level language and user-friendly machine learning libraries. The ecosystem is then completed with the adoption of a common language for sharing user models and firmwares, that is based on a dedicated Open Container Initiative artifact definition, thus leveraging all the well established practices on managing resources on a container registry.
Computing demands for large scientific experiments, such as the CMS experiment at CERN, will increase dramatically in the next decades. To complement the future performance increases of software running on CPUs, explorations of coprocessor usage in data processing hold great potential and interest. We explore the novel approach of Services for Optimized Network Inference on Coprocessors (SONIC) and study the deployment of this as-a-Service approach in large-scale data processing. In this setup, the main CMS Mini-AOD creation workflow is executed on CPUs, while several machine learning (ML) inference tasks are offloaded onto (remote) coprocessors, such as GPUs. With experiments performed at Google Cloud, the Purdue Tier-2 computing center, and combinations of the two, we demonstrate the acceleration of these ML algorithms individually on coprocessors and the corresponding throughput improvement for the entire workflow. We also show that this approach can be easily generalized to different types of coprocessors, and even deployed on local CPUs without performance decrease. We emphasize that SONIC enables high coprocessor usage and brings the portability to run workflows on different types of coprocessors.
In the past years the landscape of tools for expressing parallel algorithms in a portable way across various compute accelerators has continued to evolve significantly. There are many technologies on the market that provide portability between CPU, GPUs from several vendors, and in some cases even FPGAs. These technologies include C++ libraries such as Alpaka and Kokkos, compiler directives such as OpenMP, the SYCL open specification that can be implemented as a library or in a compiler, and standard C++ where the compiler is solely responsible for the offloading. Given this developing landscape, users have to choose the technology that best fits their applications and constraints. For example, in the CMS experiment the experience so far in heterogeneous reconstruction algorithms suggests that the full application contains a large number of relatively short computational kernels and memory transfer operations. In this work we use a stand-alone version of the CMS heterogeneous pixel reconstruction code as a realistic use case of HEP reconstruction software that is capable of leveraging GPUs effectively. We summarize the experience of porting this code base from CUDA to Alpaka, Kokkos, SYCL, std::par, and OpenMP offloading. We compare the event processing throughput achieved by each version on NVIDIA, AMD, and Intel GPUs as well as on a CPU, and compare those to what a native version of the code achieves on each platform.
We report the implementation details, commissioning results, and physics performances of a two-dimensional cluster finder for reconstructing hit positions in the new vertex pixel detector (VELO) that is part of the LHCb Upgrade. The associated custom VHDL firmware has been deployed to the existing FPGA cards that perform the readout of the VELO and fully commissioned during the start of LHCb Run 3 data taking. This work represents a further enhancement of the DAQ system, reconstructing VELO hits coordinates on-the-fly, in real time, at the LHC collision rate, and it is part of a wider effort aimed at boosting the real-time processing capability of HEP experiments by delegating intensive tasks to dedicated computing accelerators deployed at the earliest stages of the data acquisition chain. The end result is a DAQ throughput increase in excess of 11%, together with a corresponding drop in electrical power consumption, as the FPGA implementation requires O(50x) less power with respect to the GPU implementation. The tracking performance of this novel system being indistinguishable from a full-fledged software implementation, allows the raw pixel data to be dropped immediately at the readout level, yielding the additional benefit of a 14% reduction in data flow.
High Energy Physics (HEP) Trigger and Data Acquisition systems (TDAQs) need ever increasing throughput and real-time data analytics capabilities either to improve particle identification accuracy and further suppress background events in trigger systems or to perform an efficient online data reduction for trigger-less ones.
As for the requirements imposed by HEP TDAQs applications in the class of real-time dataflow processing, FPGA devices are a good fit in as much they can provide not only adequate computing, memory and I/O resources but also a smooth programming experience thanks to the availability of High-Level Synthesis (HLS) tools.
The main motivation for the design and development of the APEIRON framework is that the currently available HLS tools do not natively support the deployment of applications over multiple FPGA devices, which severely chokes the scalability of problems that this approach could tackle. To overcome this limitation, we envisioned APEIRON as an extension of the Xilinx Vitis framework able to support a network of FPGA devices interconnected by a low-latency direct network as the reference execution platform.
Developers can define scalable applications, using a dataflow programming model inspired by Kahn Process Networks, that can be efficiently deployed on a multi-FPGAs system: the APEIRON communication IPs allow low-latency communication between processing tasks deployed on FPGAs, even if they are hosted on different computing nodes. Thanks to the use of HLS tools in the workflow, processing tasks are described in C++ as HLS kernels, while communication between tasks is expressed through a lightweight C++ API based on non-blocking send() and blocking receive() operations
The rapid growth of scientific data and the computational needs of BNL-supported science programs will bring the Scientific Data and Computing Center (SDCC) to the Exabyte scale in the next few years. The SDCC Storage team is responsible for the symbiotic development and operations of storage services for all BNL experiment data, in particular for the data generated by the ATLAS experiment with the largest amount of data. While the steady increase in ATLAS needs for DISK storage capacity, the cost issue to continue with more than one DISK copies and the updated ATLAS storage environment have brought new challenges to SDCC. In order to overcome the challenges arising from the vast amount of data while enabling efficient and cost-effective data analysis in a large-scale, multi-tiered storage architecture, the Storage team has undertaken a thorough analysis of the ATLAS experiment’s requirements, matching them to the appropriate storage options and strategy, and has explored alternatives to complement/replace our current storage solution. In this paper, we present the main challenges presented by supporting several big data experiments like ATLAS. We describe its requirements and priorities, in particular, what critical storage system characteristics are needed for the high-luminosity run and how the key storage components provided by the Storage team work together: the dCache disk storage system; its archival back-end, HPSS, and its OS-level backend Storage. In particular, we investigate a new solution to integrate Lustre and XRootd. Lustre serves as backend storage and XRootd acts as an access layer frontend to support different grid access protocols. We also describe the validation, commissioning tests, and a comparison between dCache and XRootd in performance. In addition, the performance and cost comparison of OpenZFS and LINUX MDRAID, the evaluation of storage software stacks, and the stress tests to validate Third Party Copy(TPC) will be illustrated.
In the HEP community, the prediction of Data Popularity is a topic that has been approached for many years. Nonetheless, while facing increasing data storage challenges, especially in the HL-LHC era, we are still in need for better predictive models to answer the questions of whether particular data should be kept, replicated, or deleted.
The usage of caches proved to be a convenient technique that partially automates storage management and seems to eliminate some of these questions. While on one hand, we can benefit even from simple caching algorithms like LRU, on the other hand, we show that incorporation of the knowledge about the future access patterns can greatly improve the cache performance.
In this paper, we study the data popularity on the file level, where the special relation between files belonging to the same dataset could be used in addition to the standard attributes. We start by analyzing separate features and try to find the relation with the target variable: the reuse distance of the files. After, we turn to Machine Learning algorithms, such as Random Forest, which is well suited to work with Big Data: it can be parallelized, is more lightweight and easier to interpret than Deep Neural Networks. Finally, we compare the results with standard cache retention algorithms and with the theoretical optimum.
Complete and reliable monitoring of the WLCG data transfers is an important condition for effective computing operations of the LHC experiments. WLCG data challenges organised in 2021 and 2022 highlighted the need for improvements in the monitoring of data traffic on the WLCG infrastructure. In particular, it concerns the implementation of the monitoring of the remote data access via the XrootD protocol. This contribution describes the new implementation of the XrootD monitoring flow, the overall architecture, the deployment scenario and the integration with the WLCG global monitoring system.
Due to the increased demand of network traffic expected during the HL-LHC era, the T2 sites in the USA will be required to have 400Gbps of available bandwidth to their storage solution.
With the above in mind we are pursuing a scale test of XRootD software when used to perform Third Party Copy transfers using the HTTP protocol. Our main objective is to understand the possible limitations in the software stack to achieve the target transfer rate; to that end we have set up a testbed of multiple XRootD servers in both UCSD and Caltech which are connected through a dedicated link capable of 400Gbps end-to-end.
Building upon our experience deploying containerized XRootD servers we use docker and kubernetes to easily deploy and test different configurations of our testbed.
In this work we will present our experience doing these tests and the lessons learned.
In preparation for the second runs of the ProtoDUNE detectors at CERN (NP02 and NP04), DUNE has established a new data pipeline for bringing the data from the EHN-1 experimental hall at CERN to primary tape storage at Fermilab and CERN, and then spreading it out to a distributed disk data store at many locations around the world. This system includes a new Ingest Daemon and a new Declaration Daemon. The Rucio replica catalog, and FTS3 transport are used to transport all files. All file metadata is declared to the new MetaCat metadata service. All of these new components have been successfully
tested at a scale equal to the expected output of the detector data acquisition system (~2-4 GB/s), and the expected network bandwidth out of the experimental hall. We present the procedure that was used to test and the results of the test.
The LArSoft/art framework is used at Fermilab’s liquid argon time projection chamber experiments such as ICARUS to run traditional production workflows in a grid environment. It has become increasingly important to utilize HPC facilities for experimental data processing tasks. As part of the SciDAC-4 HEP Data Analytics on HPC and HEP Event Reconstruction with Cutting Edge Computing Architectures projects, we have been exploring ways to restructure HEP neutrino workflows to increase resource utilization when running at HPC facilities. Our explorations focus on taking advantage of distinct architectural features for data services, parallel application scheduling, and high CPU core counts available at these facilities. In this paper, we introduce changes needed to make use of a new system-wide event store called HEPnOS and efforts to maximize the throughput of newly available multicore algorithms with the available memory on the compute nodes. Performance results are shown for ALCF Theta using the early signal processing steps within the ICARUS production workflow.
HEPnOS is a HEP-specific distributed data store built on top of software components from the DOE-ASCR supported Mochi project. With facility-wide access to HEP event data, we can avoid processing constraints and bottlenecks present in file-based reconstruction workflows. Data stores such as HEPnOS leverage the high performance networks and memories available on HPC systems, and can help eliminate performance bottlenecks and issues that may appear when using parallel file systems.
The Liquid Argon Calorimeters are employed by ATLAS for all electromagnetic calorimetry in the pseudo-rapidity region |η| < 3.2, and for hadronic and forward calorimetry in the region from |η| = 1.5 to |η| = 4.9. They also provide inputs to the first level of the ATLAS trigger. After successful period of data taking during the LHC Run-2 between 2015 and 2018 the ATLAS detector entered into the a long period of shutdown. In 2022 the LHC has restarted a new data taking period the Run-3 period should see an increase of luminosity and pile-up up to 80 interaction per bunch crossing.
To cope with this harsher conditions, a new trigger readout path has been installed during the long shutdown. This new path should improve significantly the triggering performances on electromagnetic objects. This will be achieved by increasing the granularity of the objects available at trigger level by up to a factor of ten.
The installation of this new trigger readout chain required also the update of the legacy system. More than 1500 boards of the precision readout have been extracted from the ATLAS pit, refurbished and re-installed. The legacy analog trigger readout that will remain during the LHC Run-3 as a backup of the new digital trigger system has also been updated.
For the new system 124 new on-detector boards have been added. Those boards that are operating in a radiative environment are digitizing the calorimeter trigger signals at 40MHz. The digital signal is sent to the off-detector system and processed online to provide the measured energy value for each unit of readout. In total up to 31Tbps are analyzed by the processing system and more than 62Tbps are generated for downstream reconstruction. To minimize the triggering latency the processing system had to be installed underground. The limited available space imposed a very compact hardware structure. To achieve a compact system, large FPGAs with high throughput have been mounted on ATCA mezzanines cards. In total no more than 3 ATCA shelves are used to process the signal from approximately 34000 channels.
Given that modern technologies have been used compared to the previous system, all the monitoring and control infrastructure is being adapted and commissioned as well.
This contribution will present the challenges of the installation, the commissioning and the milestones still to be completed towards the full operation of both the legacy and the new readout paths for the LHC Run-3.
ALICE (A Large Ion Collider Experiment) is a heavy-ion detector studying the physics of strongly interacting matter and the quark-gluon plasma at the CERN LHC (Large Hadron Collider). During the second long shut-down of the LHC, the ALICE detector was upgraded to cope with an interaction rate of 50 kHz in Pb-Pb collisions, producing in the online computing system (O2) a sustained input throughput of 3 TB/s.
In the past years, the O2/FLP project built the new data-acquisition system capable of handling this load. It consists of 200 readout nodes, collecting the data transferred from over 8000 detector links to PCs memory by dedicated PCI boards. The readout software manages the hardware and software memory buffers used for DMA and inter-process communication. It initiates the data flow, performs on-the-fly consistency checks, formats the data, reports performance, and finally pushes the data to the local processing pipeline. The output is then sent by the data distribution software over 100Gb/s links to a dedicated event processing farm.
The readout software modular design allowed to address the manifold needs faced during the prototyping, installation and commissioning phases, which proved essential from the lab tests to physics production, like file replay and recording, or online multi-threaded LZ4 compression.
We will describe the hardware and software implementation of the O2 readout system, and review the challenges met during the commissioning and first months of operation with LHC collisions in 2022.
A new era of hadron collisions will start around 2029 with the High-Luminosity LHC which will allow to collect ten times more data than what has been collected during 10 years of operation at LHC. This will be achieved by higher instantaneous luminosity at the price of higher number of collisions per bunch crossing.
In order to withstand the high expected radiation doses and the harsher data taking conditions, the ATLAS Liquid Argon Calorimeter readout electronics will be upgraded.
The electronic readout chain is composed of four main components.
1: New front-end boards will allow to amplify, shape and digitise the calorimeter’s ionisation signal on two gains over a dynamic range of 16 bits and 11 bit precision. Low noise below Minimum Ionising Particle (MIP), i.e. below 120 nA for 45 ns peaking time, and maximum non-linearity of two per mille are required. Custom preamplifiers and shapers are being developed to meet these requirements using 65 nm and 130 nm CMOS technologies. They shall be stable under irradiation until 1.4kGy (TID) and 4.1x10^13 new/cm^2 (NIEL). Two concurrent preamp-shaper ASICs were developed and, “ALFE”, the best one has been chosen. The test results of the latest version of this ASIC will be presented. “COLUTA”, a new ADC chip is also being designed. A production test setup is being prepared and integration tests of the different components (including lpGBT links developed by CERN) on a 32-channels front-end board are ongoing, and results of this integration will be shown.
2: New calibration boards will allow the precise calibration of all 182468 channels of the calorimeter over a 16 bits dynamic range. A non-linearity of one per mille and non-uniformity between channels of 0.25% with a pulse rise time smaller than 1ns shall be achieved. In addition, the custom calibration ASICs shall be stable under irradiation with same levels as preamp-shaper and ADC chips. The HV SOI CMOS XFAB 180nm technology is used for the pulser ASIC, “CLAROC”, while the TSMC 130 nm technology is used for the DAC part, “LADOC”. The latest versions of those 2 ASICs which recently passed the production readiness review (PDR) with their respective performances will be presented.
3: New ATCA compliant signal processing boards (“LASP”) will receive the detector data at 40 MHz where FPGAs connected through lpGBT high-speed links will perform energy and time reconstruction. In total, the off-detector electronics receive 345 Tbps of data via 33000 links at 10 Gbps. For the first time, online machine learning techniques are considered to be used in these FPGAs. A subset of the original data is sent with low latency to the hardware trigger system, while the full data are buffered until the reception of trigger accept signals. The latest development status of the board as well as the firmware will be shown.
4: A new timing and control system, “LATS”, will synchronise to the aforementioned components. Its current design status will also be shown.
Over the next decade, the ATLAS detector will be required to operate in an increasingly harsh collision environment. To maintain physics performance, the detector will undergo a series of upgrades during major shutdowns. A key goal of these upgrades is to improve the capacity and flexibility of the detector readout system. To this end, the Front-End Link eXchange (FELIX) system was developed as the new interface between the data acquisition; detector control and TTC (Timing, Trigger and Control) systems; and new or updated trigger and detector front-end electronics. FELIX functions as a router between custom serial links from front end ASICs and FPGAs to data collection and processing components via a commodity switched network. The serial links may aggregate many slower links or be a single high bandwidth link. FELIX also forwards the LHC bunch-crossing clock, fixed latency trigger accepts and resets received from the TTC system to front-end electronics. FELIX uses commodity server technology in combination with FPGA-based PCIe I/O cards. FELIX servers run a software routing platform serving data to network clients performing a number of data preparation, monitoring and control functions.
This presentation covers the design of FELIX as well as the first operational experience gained during the Run 3 starting, including the challenges faced commissioning the system for each ATLAS sub-detector. Finally, the planned evolution of FELIX for High-Luminosity LHC will be described, including architectural changes and status of early integration with detector development projects.
The volume and complexity of data produced at HEP and NP research facilities have grown exponentially. There is an increased demand for new approaches to process data in near-real-time. In addition, existing data processing architectures need to be reevaluated to see if they are adaptable to new technologies. A unified programming model for event processing and distribution that can exploit parallelism and heterogeneity in the computing environment still needs to be developed. This paper investigates the benefits of blending Flow-Based Programming with the Reactive Actor Model for building distributed, reactive, and high-performance data stream processing applications. In this paper, we present the design concepts of the ERSAP framework for building such applications. The results of using ERSAP in the recent beam test of the EIC prototype calorimeter at DESY and a GEM detector at JLAB will be presented.
To improve the potential for discoveries at the LHC, a significant luminosity increase of the accelerator (HL-LHC) is foreseen in the late 2020s, to achieve a peak luminosity of 7.5x10^34 cm^-2 s^-1, in the ultimate performance scenario. HL-LHC is expected to run with a bunch-crossing separation of 25 ns and a maximum average of 200 events (pile-up) per crossing. To maintain or even improve the performance of CMS in this harsh environment, the detector will undergo several upgrades in the next years. In particular, the Inner Tracker is being completely redesigned featuring a frontend chip with a data readout speed of 1.28 Gbps, and a downlink for clock, trigger, and commands of 160 Mbps. The communication between the frontend and the backend electronics occurs through an optical link based on a custom Low-power Gigabit Transceiver which sends data at 10 and 2.5 Gbps on the uplink and downlink, respectively. The number of pixels has been increased by x6 with respect to the present detector, covering a larger pseudorapidity region up to 4, resulting in an unprecedented number of channels of about two billion. This represents a challenging requirement for the data acquisition system since it needs to efficiently configure, monitor, and calibrate them. A dedicated data acquisition system, written in C++ and based on a custom micro Data, Trigger, and Control board, equipped with an FPGA, was developed to fully test and characterize the pixel modules both on a bench and with beam tests. In this note, we will describe the system architecture and its scalability to the final system which will be based on custom back-end boards equipped with FPGAs and CPUs.
For HEP event processing, data is typically stored in column-wise synchronized containers, such as most prominently ROOT’s TTree, which have been used for several decades to store by now over 1 exabyte. These containers can combine row-wise association capabilities needed by most HEP event processing frameworks (e.g. Athena for ATLAS) with column-wise storage, which typically results in better compression and more efficient support for many analysis use-cases.
One disadvantage is that these containers, TTree in the HEP use-case, require to contain the same attributes for each entry/row (representing events), which can make extending the list of attributes very costly in storage, even if those are only required for a small subsample of events.
Since the initial design, the ATLAS software framework features powerful navigational infrastructure to allow storing custom data extensions for subsample of events in separate, but synchronized containers. This allows adding event augmentations to ATLAS standard data products (such as DAOD-PHYS or PHYSLITE) avoiding duplication of those core data products, while limiting their size increase. For this functionality, the framework does not rely on any associations made by the I/O technology (i.e. ROOT), however it supports TTree friends and builds the associated index to allow for analysis outside of the ATLAS framework.
A prototype based on the Long-Lived Particle search is implemented and preliminary results with this prototype will be presented. At this point, augmented data are stored within the same file as the core data. Storing them in separate files will be investigated in future, as this could provide more flexibility, e.g. certain sites may only want a subset of several augmentations or augmentations can be archived to disk once their analysis is complete.
The increased footprint foreseen for Run-3 and HL-LHC data will soon expose
the limits of currently available storage and CPU resources. Data formats
are already optimized according to the processing chain for which they are
designed. ATLAS events are stored in ROOT-based reconstruction output files
called Analysis Object Data (AOD), which are then processed within the
derivation framework to produce Derived AOD (DAOD) files.
Numerous DAOD formats, tailored for specific physics and performance groups,
have been in use throughout the ATLAS Run-2 phase. In view of Run-3, ATLAS
has changed its Analysis Model, which entailed a significant reduction of
the existing DAOD flavors. Two new, unfiltered and skimmable on read,
formats have been proposed as replacements: DAOD_PHYS, designed to meet the
requirements of the majority of the analysis workflows, and DAOD_PHYSLITE, a
smaller format containing already calibrated physics objects. As ROOT-based
formats, they natively support four lossless compression algorithms: Lzma,
Lz4, Zlib and Zstd.
In this study, the effects of different compression settings on file size,
compression time, compression factor and reading speed are investigated
considering both DAOD_PHYS and DAOD_PHYSLITE formats. Total as well as
partial event reading strategies have been tested. Moreover, the impact of
AutoFlush and SplitLevel, two parameters controlling how in-memory data
structures are serialized to ROOT files, has been evaluated.
This study yields quantitative results that can serve as a paradigm on how
to make compression decisions for different ATLAS' use cases. As an example,
for both DAOD_PHYS and DAOD_PHYSLITE, the Lz4 library exhibits the fastest
reading speed, but results in the largest files, whereas the Lzma algorithm
provides larger compression factors at the cost of significantly slower
reading speeds. In addition, guidelines for setting appropriate AutoFlush
and SplitLevel values are outlined.
With the increased data volumes expected to be delivered by the HL-LHC, it becomes critical for the ATLAS experiment to maximize the utilization of available computing resources ranging from conventional GRID clusters to supercomputers and cloud computing platforms. To be able to run its data processing applications on these resources, the ATLAS software framework must be capable of efficiently executing data processing tasks in heterogeneous distributed computing environments. Today with the use of Gaudi Avalanche Scheduler, a central component of the multithreaded Athena framework whose implementation is based on Intel TBB, we can efficiently schedule Athena algorithms to multiple threads within a single compute node. Our goal is to develop a new framework scheduler capable of supporting distributed heterogeneous environments, based on technologies like HPX and Ray. After the initial evaluation phase of these technologies, we began the actual development of prototype distributed task schedulers and their integration with the Athena framework. This contribution will describe these prototype schedulers , as well as the preliminary results of performance studies of these prototypes within ATLAS data processing applications.
Since March 2019 the Belle II detector has collected data from e+ e- collisions at the SuperKEKB collider. For Belle II analyses to be competitive it is crucial that calibration constants are calculated promptly so that the reconstructed datasets can be provided to analysts. A subset of calibration constants also benefit by being re-derived during yearly recalibration campaigns to give analysts the best possible reconstructed datasets for their final publications.
At the Belle II experiment a Python package, b2cal, was developed to automate the running of Calibration and Alignment Framework (CAF) processes for prompt calibration at Brookhaven National Laboratory (BNL). This uses the open-source Apache Airflow workflow platform to schedule, run, and monitor the calibration procedures by describing them as Directed Acyclic Graphs (DAGs). This has resulted in a successful reduction of both the time taken to produce constants and the human intervention required. In 2022 the recalibration of older data at the Deutsches Elektronen-Synchrotron Laboratory (DESY) was also performed in parallel with the continuing prompt calibration at BNL. The scope of the system has now expanded to include the organisation of creating calibration constants for run-dependent Monte Carlo data and development of the b2cal package now focuses on incorporating more of the post-calibration data processing tasks. The current structure of the automated Belle II calibration system and these new developments will be described.
REve, the new generation of the ROOT event-display module, uses a web server-client model to guarantee exact data translation from the experiments' data analysis frameworks to users' browsers. Data is then displayed in various views, including high-precision 2D and 3D graphics views, currently driven by THREE.js rendering engine based on WebGL technology.
RenderCore, a computer graphics research oriented rendering engine, has been integrated into REve to optimize rendering performance as well as to enable the use of state-of-the-art techniques for object highlighting and object selection. It also allowed for an implementation of optimized instanced rendering through usage of custom shaders and rendering pipeline modifications.
To further the impact of this investment and ensure long-term viability of REve, RenderCore has been refactored on top of WebGPU, the next generation GPU interface for browsers that supports compute shaders and introduces significant improvements in GPU utilization. This leads to optimization of interchange data formats, decreases server-client traffic, and improves offloading of data visualization algorithms to the GPU.
FireworksWeb, physics analysis oriented event-display of the CMS experiment, will be used to demonstrate the results, focusing on optimized visualization of particle trajectories, and high-granularity calorimeters and targeting high data-volume events of heavy-ion collisions and high-luminosity LHC.
Next steps and directions will be discussed, such as porting parts of RenderCore and client-side REve code to C++ and compiling them into WebAssembly using Emscripten to further optimize the CPU performance of the rendering engine.
Particle tracking is among the most sophisticated and complex part of the full event reconstruction chain. A number of reconstruction algorithms work in a sequence to build these trajectories from detector hits. Each of these algorithms use many configuration parameters that need to be fine-tuned to properly account for the detector/experimental setup, the available CPU budget and the desired physics performance. Few examples of such parameters include the cut values limiting the search space of the algorithm, the approximations accounting for complex phenomena or the parameters controlling algorithm performance. The most popular method to tune these parameters is hand-tuning using brute-force techniques. These techniques can be inefficient and raise issues for the long-term maintainability of such algorithms. The open-source track reconstruction software framework known as “A Common Tracking Framework (ACTS)” offers an alternative solution to these parameter tuning techniques through the use of automatic parameter optimization algorithms. ACTS come equipped with an auto-tuning suite that provides necessary setup for performing optimization of input parameters belonging to track reconstruction algorithms. The user can choose the tunable parameters in a flexible way and define a cost/benefit function for optimizing the full reconstruction chain. The fast execution speed of ACTS allows the user to run several iterations of optimization within a reasonable time bracket. The performance of these optimizers has been demonstrated on different track reconstruction algorithms such as trajectory seed reconstruction and selection, particle vertex reconstruction and generation of simplified material map, and on different detector geometries such as Generic Detector and Open Data Detector (ODD). We aim to bring this approach to all aspects of trajectory reconstruction by having a more flexible integration of tunable parameters within ACTS.
Reliably simulating detector response to hadrons is crucial for almost all physics programs at the Large Hadron Collider. The core component of such simulation is the modeling of hadronic interactions. Unfortunately, there is no first-principle theory guidance. The current state-of-the-art simulation tool, Geant4, exploits phenomenology-inspired parametric models, each simulating a specific range of hadron energies for some hadron flavor types. These models must be combined to simulate all hadron flavors at all energy ranges. Parameters in each model and the transition region between models must be tuned to match the experimental measurements. Those models may be updated to cope with new measurements. Our work is to make the modeling of hadronic interactions differentiable so that it is easy to tune and to unify all parametric models with one machine learning-based model so that it is easy to maintain and update. To this end, we exploit the conditional normalizing flow models and train them with simulated data. Our work is the first step toward developing a fully differentiable and data-driven simulation model for hadronic interactions for High Energy and Nuclear Physics.
The full simulation of particle colliders incurs a significant computational cost. Among the most resource-intensive steps are detector simulations. It is expected that future developments, such as higher collider luminosities and highly granular calorimeters, will increase the computational resource requirement for simulation beyond availability. One possible solution is generative neural networks that can accelerate simulations. Normalizing flows are a promising approach in this pursuit. It has been previously demonstrated, that such flows can generate showers in low-complexity calorimeters with high accuracy. We show how normalizing flows can be improved and adapted for precise shower simulation in significantly more complex calorimeter geometries.
For High Energy Physics (HEP) experiments, the calorimeter is a key detector to measure the energy of particles. Particles interact with the material of the calorimeter, creating cascades of secondary particles, the so-called showers. Description of the showering process relies on simulation methods that precisely describe all particle interactions with matter. Constrained by the complexity of the calorimeter geometry and the need to accurately simulate the interaction with each material, the simulation of calorimeters is inherently slow and constitutes a bottleneck for current and future HEP analysis. In order to spur the development and benchmarking of fast and high-fidelity simulation, the first-ever fast calorimeter simulation challenge “CaloChallenge” was proposed. The challenge offers a common benchmark of performance metrics and three realistic datasets, ranging in difficulty from easy to medium to hard. This contribution highlights an initial analysis of submitted results using new approaches of generative models.
Simulation is a crucial part of all aspects of collider data analysis. However, the computing challenges of the High Luminosity era will require simulation to use a smaller fraction of computing resources, at the same time as more complex detectors are introduced, requiring more detailed simulation. This motivates the use of machine learning (ML) models as surrogates to replace full physics-based detector simulation. Recently in the ML community, a new class of models based on diffusion have become state of the art for generating high quality images with reasonable computation times. In this work, we study the application of diffusion models to generate simulated calorimeter showers. In order to reduce the computational burden of the method, we explore compressing the calorimeter shower into a smaller latent space for the diffusion process. Optimization of this latent space, the handling of irregular detector geometries, and comparisons to other generative models will be discussed. We will also discuss the possibility of using diffusion models to enhance, or denoise, existing physics-based fast simulations as an alternative to the fully generative approach.
Recently, transformers have proven to be a generalized architecture for various data modalities, i.e., ranging from text (BERT, GPT3), time series (PatchTST) to images (ViT) and even a combination of them (Dall-E 2, OpenAI Whisper). Additionally, when given enough data, transformers can learn better representations than other deep learning models thanks to the absence of inductive bias, better modeling of long-range dependencies, and interpolation and extrapolation capabilities. Therefore, the transformer is a promising model to be explored for fast shower simulation, where the goal is to generate synthetic particle showers, i.e., the energy depositions in the calorimeter. The transformer should accurately model the non-trivial structure of particle showers, as well as quickly adapt to new detector geometries. Furthermore, the attention mechanism in transformers enables the model to better learn the complex conditional distribution of energy depositions in the detector. In this work, we will present how transformers can be used for accurate and fast shower simulation, as well as the know-how on transformer architecture, input data representation, sequence formation, and learning mechanism.
At the CMS experiment, a growing reliance on the fast Monte Carlo application (FastSim) will accompany the high luminosity and detector granularity expected in Phase 2. The FastSim chain is roughly 10 times faster than the application based on the GEANT4 detector simulation and full reconstruction referred to as FullSim. However, this advantage comes at the price of decreased accuracy in some of the final analysis observables. In this contribution, a machine learning-based technique to refine those observables is presented. We employ a regression neural network trained with a sophisticated combination of multiple loss functions to provide post-hoc corrections to samples produced by the FastSim chain. The results show considerably improved agreement with the FullSim output and an improvement in correlations among output observables and external parameters. This technique is a promising replacement for existing correction factors, providing higher accuracy and thus contributing to the wider usage of FastSim.
The Vera C. Rubin Observatory will produce an unprecedented astronomical data set for studies of the deep and dynamic universe. Its Legacy Survey of Space and Time (LSST) will image the entire southern sky every three days and produce tens of petabytes of raw image data and associated calibration data. More than 20 terabytes of data must be processed and stored every night for ten years.
The Production and Distributed Analysis (PanDA) system was evaluated by the Vera C. Rubin Observatory Data Management team and selected to serve the observatory’s needs due to its demonstrated scalability and flexibility over the years, for its Directed Acyclic Graph (DAG) support, it’s support for multi-site processing, and its highly scalable complex workflows via the intelligent Data Delivery Service (iDDS). PanDA is also being evaluated for prompt processing where data must be processed and alerts issued within 60 seconds.
This presentation will briefly describe the Vera C. Rubin Data Management system and its use at both the Interim Data Facility (IDF) hosted on the Google Cloud Platform (GCP) and the United States Data Facility (USDF) hosted at the SLAC Shared Scientific Data Facility (S3DF). Finally, it will describe in depth the work performed in order to integrate the PanDA system with the Vera Rubin Observatory to be able to run the Rubin Science Pipelines using PanDA.
The Vera C. Rubin Observatory, currently in construction in Chile, will start performing the Large Survey of Space and Time (LSST) late 2024 for 10 years. Its 8.4-meter telescope will survey the southern sky in less than 4 nights in six optical bands, and repeatedly generate about 2000 exposures per night, corresponding to a data volume of about 20 TB every night. Three data facilities are preparing to contribute to the production of the annual data releases: the US Data Facility (USDF) will process 25% of the raw data, the UK data facility (UKDF) will process 25% of the raw data and the French data facility (FrDF), operated by CC-IN2P3, that will locally process the remaining 50% of the raw data.
In the context of the Data Preview 0.2 (DP0.2), the Data Release Production (DRP) pipelines have been executed on the DC-2 simulated dataset (generated by the DESC collaboration, DESC). This dataset includes 20 000 simulated exposures, representing 300 square degrees of Rubin images with a typical depth of 5 years.
DP0.2 ran at the interim data facility (based on Google cloud), and the full exercise was replicated at CC-IN2P3. During this exercise, 3 PiB of data and more than 200 million files have been produced. In this contribution we will present a detailed description of the system that we set up to perform this processing campaign using CC-IN2P3's computing and storage infrastructure. Several topics will be addressed: workflow generation and execution, batch job submission, memory and I/O requirements, operations, etc. We will focus on the issues that arose during this campaign and how they have been addressed and will present the lessons learnt from this exercise.
The Large High Altitude Air Shower Observatory (LHAASO) is a large-scale astrophysics experiment led by China. The offline data processing was highly dependent on the Institute of High Energy Physics(IHEP) local cluster and the local file system.
As the LHAASO experimental cooperation groups’ resources are located geographically and most of them have the characteristics of limited scale, low stability, and lack of human support, it is difficult to integrate them via Grid. We designed and developed a lightweight distributed computing system for LHAASO offline data processing. Unlike the grid model, the system keeps the IHEP cluster as the main cluster and extends the cluster to the worker nodes of the remote site. LHAASO jobs are submitted to the IHEP cluster and are dispatched to the remote worker node in the system.
Tokens are the authentication and authorization solution in the whole cluster, LHAASO computing tasks are classified into several types. Each type of job is wrapped by a dedicated script which helps the job have no direct access to the IHEP file system. The system draws on the idea of “startd automatic cluster joining” of GlideinWMS but abandons the grid certificate authentication.
About 125 worker nodes with 4k CPU cores at the remote site have been joined into IHEP LHAASO cluster by the distributed computing system and provided LHAASO job to produce 700TB simulation data in 6 months.
The Cherenkov Telescope Array Observatory (CTAO) is the next generation ground-based observatory for gamma-ray astronomy at very high energies. It will consist of tens of Cherenkov telescopes, spread between two array sites: one in the Northern hemisphere in La Palma (Spain), and one in the Southern hemisphere in Paranal (Chile). Currently under construction, CTAO will start scientific operations in the next years for about 30 years. CTAO is expected to produce 2PB of raw data each year and to manage a global data volume which will grow through the years to reach around 100 PB. In addition, CTAO will require a high computing capacity for data processing and Monte Carlo simulations, of the order of hundreds of millions of CPU HS06 hours per year. To meet these requirements, CTAO will have a distributed computing model using 4 academic data centers, and use the DIRAC framework as its workload management system. In the past ten years, to optimize the instrument design and study its performances, CTAO has used the EGI grid infrastructure to run massive Monte Carlo campaigns. For these campaigns, CTAO has developed a production system prototype, based on DIRAC, to automatize the simulation and data processing workflows. This production system uses meta-data to link the different steps of a workflow. Recently, we have developed an interface to this system allowing for the configuration and submission of complex workflows.
In this contribution we present the CTAO production system and its use during the latest Monte Carlo campaigns as well as its recent interface development.
In preparation for LHC Run 3 and 4, the ALICE Collaboration has moved to a new Grid middleware, JAliEn, and workflow management system. The migration was dictated by the substantially higher requirements on the Grid infrastructure in terms of payload complexity, increased number of jobs and managed data volume, all of which required a complete rewrite of the middleware using modern software languages and technologies. Through containerization, self-contained binaries, managed by the JAliEn middleware, we provide a uniform execution environment across sites and various architectures, including accelerators. The model and implementation have proven their scalability and can be easily deployed across sites with minimal intervention.
This contribution outlines the architecture of the new Grid workflow as deployed in production and the workflow process. Specifically shown is how core components are moved and bootstrapped through CVMFS, enabling the middleware to run anywhere fully independent of the host system. Furthermore, it will examine how new middleware releases, containers and their runtimes are centrally maintained and easily deployed across the Grid, also by the means of a common build system.
The ALICE Grid is designed to perform a realtime comprehensive monitoring of both jobs and execution nodes in order to maintain a continuous and consistent status of the Grid infrastructure. An extensive database of historical data is available and is periodically analyzed to tune the workflow and data management to optimal performance levels. This data, when evaluated in real time, has the power to trigger decisions for efficient resource management of the currently running payloads, for example to enable the execution of a higher volume of work per unit of time. In this article, we consider scenarios in which, through constant interaction with the monitoring agents, a dynamic adaptation of the running workflows is performed. The target resources are memory and CPU with the objective of using them in their entirety and ensuring optimal utilization fairness between executing jobs.
Grid resources are heterogeneous and of different generations, which means that some of them have superior hardware characteristics than the minimum required to execute ALICE jobs. Our middleware, JAliEn, works on the basis of allocating 2GB of RAM memory per job (allowing up to 8GB when including SWAP). Many of the worker nodes have higher memory per core ratios than these basic limits, thus in terms of available memory they have free resources to accommodate extra jobs. The running jobs may have different behaviors and unequal resource usage depending on their nature. For example, analysis tasks are I/O bound while MonteCarlo tasks are CPU intensive. Running additional jobs with complementary resource usage patterns on a worker node has a great potential to increase the total efficiency of the worker nodes. This paper presents the methodology to exploit the different resource usage profiles by oversubscribing the executing nodes with extra jobs taking into account their CPU resource usage levels and memory capacity.
HEP data-processing frameworks are essential ingredients in getting from raw data to physics results. But they are often tricky to use well, and they present a significant learning barrier for the beginning HEP physicist. In addition, existing frameworks typically support rigid, collider-based data models, which do not map well to neutrino-physics experiments like DUNE. Neutrino physicists thus expend significant effort working around framework limitations instead of using a framework that directly supports their needs.
In this talk, I present Meld, a Fermilab R&D project, which intends to address these limitations. By leveraging modern C++ capabilities, state-of-the-art concurrency libraries, and a flexible data model, it is possible for beginning (and seasoned) HEP physicists to execute framework programs easily and efficiently, with minimal coupling to framework-specific constructs. Meld aims to directly support the frameworks needs of neutrino experiments like DUNE as well as the more common collider-based experiments.
The Belle II software was developed as closed source. As several HEP experiments released their code to the public, the topic of open source software was also discussed within the Belle II collaboration. A task force analyzed advantages and disadvantages and proposed a policy which was adopted by the collaboration in 2020. The Belle II offline software was then released under an open source license on github in 2021. In this contribution we will review the technical, social, and political challenges that had to be overcome for the publication of the Belle II software and take a look at the current status and prospects.
Detector studies for future experiments rely on advanced software
tools to estimate performance and optimize their design and technology
choices. The Key4hep project provides a flexible turnkey solution for
the full experiment life-cycle based on established community tools
such as ROOT, Geant4, DD4hep, Gaudi, podio and spack. Members of the
CEPC, CLIC, EIC, FCC, and ILC communities have joined to develop this
framework and have merged, or are in the progress of merging, their
respective software environments into the Key4hep stack.
This presentation will give an overview over the recent progress in
the Key4hep project: covering the developments towards adaptation of
state-of-the-art tools for simulation (DD4hep, Gaussino), track and
calorimeter reconstruction (ACTS, CLUE), particle flow (PandoraPFA),
analysis via RDataFrame, and visualization with Phoenix. We will also
cover the testing of some workflows on heterogeneous
computing resources. Finally, we will show how new communities can adopt the
Key4hep solution for their own purposes.
Open Data Detector (ODD) is a detector for algorithm research and development. The tracking system is an evolution of the detector used in the successful Tracking Machine Learning Challenge. It offers a more realistic design, with a support structure, cables, and cooling pipes. The ODD got extended with granular calorimetry and can be completed in future with a muon system. The magnetic field in the detector can be created with a solenoid located either in front or behind the calorimeters, providing two alternative options for detector studies.
Implementation in DD4hep allows to perform ACTS based simulation (Fatras) of tracking detector, and Geant4 simulation of the full detector using key4HEP software. The goal of the ODD is to create a benchmark detector with public simulation data released and available for algorithm studies. Such data can be used for all the ongoing activities in the areas such as fast simulation or reconstruction.
During Run 2 the ATLAS experiment employed a large number of different user frameworks to perform the final corrections of its event data. For Run 3 a common framework was developed that incorporates the lessons learned from existing frameworks. Besides providing analysis standardization it also incorporates optimizations that lead to a substantial reduction in computing needs during analysis.
ATLAS is one of the main experiments at the Large Hadron Collider, with a diverse physics program covering precision measurements as well as new physics searches in countless final states, carried out by more than 2600 active authors. The High Luminosity LHC (HL-LHC) era brings unprecedented computing challenges that call for novel approaches to reduce the amount of data and MC that is stored, while continuing to support the rich physics program.
With the beginning of LHC Run 3, ATLAS introduced a new common data format, PHYS, that replaces most of the individual formats that were used in Run 2, and therefore reduces the disk storage significantly. ATLAS also launched the prototype of another common format, PHYSLITE, that is about a third of the size of PHYS. PHYSLITE will be the main format for the HL-LHC, and aims to serve 80% of all physics analyses. To simplify analysis workloads and further reduce disk usage it is designed to largely replace user-defined analysis n-tuples and consequently contains pre-calibrated objects. PHYSLITE is also intended to support “columnar” data processing techniques, which for some analyses may have significant advantages over the traditional event-loop analysis style. The evolution of data formats, the design principles for PHYSLITE, techniques for file size reductions, and various forms of validations will be discussed.
Current analysis at ATLAS always involves a step of producing an analysis-specific n-tuple that incorporates the final step of calibrations as well as systematic variations. The goal for Run 4 is to make these analysis-specific corrections fast enough that they can be applied "on-the-fly" without the need for an intermediate n-tuple. The main complications for this are that some of these corrections have very complex implementations, and that a wide range of environments needs to be supported. An early prototype will be presented.
A performant and easy-to-use event data model (EDM) is a key component of any HEP software stack.The podio EDM toolkit provides a user friendly way of generating such a performant implementation in C++ from a high level description in yaml format. Finalizing a few important developments, we release v1.0 of podio, a stable release with backward compatibility for datafiles written with podio from now on. We present an overview of the podio basics, and go into slighty more technical detail on the most important topics and developments. These include: schema evolution for generated EDMs, multithreading with podio generated EDMs, the implementation of them as well as the basics of I/O. Using EDM4hep, the common and shared EDM of the Key4hep project, we highlight a few of the smaller features in action as well as some lessons learned during the development of EDM4hep and podio. Finally, we show how podio has been integrated into the Gaudi based event processing framework that is used by Key4hep, before we conclude with a brief outlook on potential developments after v1.0.
In the last two decades, there have been major breakthroughs in Quantum Chromodynamics (QCD), the theory of the strong interaction of quark and gluons, as well as major advances in the accelerator and detector technologies that allow us to map the spatial distribution and motion of the quarks and gluons in terms of quantum correlation functions (QCF). This field of research broadly known as Nuclear Femtography enters into a new era of exploration with the data from the 12 GeV Science program at Jefferson Lab being available and the construction of the Electron-Ion Collider and its detectors. Nuclear Femtography promises dramatic breakthroughs in our understanding of the subatomic world. It is now timely to rethink theoretical and experimental workflows for studying QCF and take advantage of recent algorithmic advances and unprecedented computing resources of the powerful new computers at the exascale to constrain QCF precisely in five or more kinematic dimensions.
The QUAntum chromodynamics Nuclear TOMography (QuantOm) Collaboration is proposing a unique event-level inference framework to obtain a quark and gluon tomography of nucleons and nuclei from high-energy scattering data. This new event-level approach stands to have a transformational impact on the data analysis workflow that connects theory with experiment, and will help ensure that current and future facilities, such as Jefferson Lab and the Electron-Ion Collider, deliver on their science mission to reveal the inner structure of the visible universe at the femtometer scale.
In the ideal world, we describe our models with recognizable mathematical expressions and directly fit those models to large data sample with high performance. It turns out that this can be done with a CAS, using its symbolic expression trees as template to computational back-ends like JAX. The CAS can in fact further simplify the expression tree, which can result in speed-ups in the numerical back-end.
The ComPWA project offers Python libraries that use this principle to formulate large expressions for amplitude analysis, so that the user has the flexibility to quickly implement different formalisms and can also easily perform fast computations on large data samples. The CAS additionally allows the project to standardize and automatically document these formalisms as they are being implemented.
The CMSWEB cluster is pivotal to the activities of the Compact Muon Solenoid (CMS) experiment, as it hosts critical services required for the operational needs of the CMS experiment. The security of these services and the corresponding data is crucial to CMS. Any malicious attack can compromise the availability of our services. Therefore, it is important to construct a robust security infrastructure. In this work, we discuss some new security features introduced to the CMSWEB kubernetes ("k8s") cluster. The new features include the implementation of network policies, deployment of Open Policy Agent (OPA), enforcement of OPA policies, and lastly, the integration of Vault. The network policies act as an inside-the-cluster firewall to limit the network communication between the pods to the minimum necessary, and its dynamic nature allows us to work with microservices. The OPA validates the objects against some custom-defined policies during create, update, and delete operations to further enhance security. Without recompiling or changing the configuration of the Kubernetes API server, it can apply customized policies on Kubernetes objects and their audit functionality enabling us to detect pre-existing conflicts and issues. Although Kubernetes incorporates the concepts of secrets, they are only base64 encoded and are not dynamically configured; once the configuration of any secret is changed, the service restart is required for the configuration to be incorporated. This is where Vault comes into play: Vault dynamically secures, stores, and tightly controls access to sensitive data. This way, the secret information is encrypted, secured, and centralized, making it more scalable and easier to manage. Thus, the implementation of these three security features will corroborate the enhanced security and reliability of the CMSWEB Kubernetes infrastructure.
Helmholtz Federated IT Services (HIFIS) provides shared IT services in across all fields and centres in the Helmholtz Association. HIFIS is a joint platform in which most of the research centres in the Helmholtz Association collaborate and offer cloud and fundamental backbone services free of charge to scientists in Helmholtz and their partners. Furthermore, HIFIS provides a federated authentication and authorization infrastructure that enables a unified login across all services.
DESY provides several of those cloud services in this Helmholtz Cloud, which include HedgeDoc, JupyterHub, the HIFIS Cloud Portal and more. The Cloud Portal is developed at DESY and provides a central entry point for users to find and access services in the Helmholtz Cloud. These services have been deployed on a shared Kubernetes cluster to ensure availability and scalability. To manage the deployments, a GitOps approach was taken to provide an automated deployment process that facilitates fast rollouts and accountability. This was achieved by using Gitlab and FluxCD to manage the configurations and apply them to the cluster. Additionally, for the Cloud Portal Gitlab pipelines have been developed that automatically deploy completely separated review environments for merge requests that enable full end-to-end tests.
This contribution describes the process to employ this new operational framework and the challenges that had to be overcome as well as organizational agreements taken within the administrating team.
The centralised Elasticsearch service has already been running at CERN for over 6 years, providing the search and analytics engine for numerous CERN users. The service has been based on the open-source version of Elasticsearch, surrounded by a set of external open-source plugins offering security, multi-tenancy, extra visualization types and more. The evaluation of OpenDistro for Elasticsearch, also based on the open-source Elasticsearch core, started couple of years ago. It offered similar functionality using a set of different modules, with the main difference being that everything was bundled together, making it easier to deploy new versions. Later on, after a restrictive license change from Elastic, this evaluation became much more critical. The OpenDistro project got re-branded as OpenSearch, having now a forked version of Elasticsearch at core. Motivated by the license change and by the streamlined deployment of the feature-rich OpenSearch project as a 100% open-source environment, the decision was taken to migrate the service at CERN towards it. Adjusting the service to the new modules required the full redesign of the architecture. This had to be achieved while maintaining the high standards of resource-efficiency already in place. In addition to the plethora of new capabilities, the new architecture enables a streamlined service deployment that overcomes long-standing maintainability issues, while covering the ever-rising demand of use-cases. At the time of writing this article, over 30 OpenSearch clusters are in production using our service. This contribution covers the motivation, design and implementation of this change for the diverse use-cases around CERN, as well as the challenges emerged along the road.
The LCAPE project develops artificial intelligence to improve operations in the FNAL control room by reducing the time to identify the cause of an outage, improving the reproducibility of labeling it, predicting their duration and forecasting their occurrence.
We present our solution for incorporating information from ~2.5k monitored devices to distinguish between dozens of different causes of down time.
We discuss the performance of different techniques for modeling the state of health of the facility and of different unsupervised clustering techniques to distinguish between different causes of down time.
Batch@CERN team manages over 250k CPU cores for Batch processing of LHC data with our HTCondor cluster comprising ~5k nodes. We will present a lifecycle management solution of our systems with our in-house developed state-manager daemon BrainSlug and how it handles draining, rebooting, interventions and other actions on the worker nodes, with Rundeck as our human-interaction endpoint and using StackStorm for automated procedures of remediating minor alarms, health-checks and enabling an overall self-healing infrastructure. We will demonstrate how these processes and reduced the manual overhead of handling daily operations by a 10x factor with StackStorm enabled workflows, and how we can enable operators to schedule and manage interventions while having granular control on the actions exposed to such operators.
The transition of WLCG storage services to dual-stack IPv4/IPv6 is nearing completion after more than 5 years, thus enabling the use of IPv6-only CPU resources as agreed by the WLCG Management Board and presented by us at earlier CHEP conferences. Much of the data is transferred by the LHC experiments over IPv6. All Tier-1 storage and over 90% of Tier-2 storage is now IPv6-enabled, yet we still see IPv4 transfers happening when both endpoints have IPv6 available or when remote data is accessed over the network from worker nodes.
The monitoring and tracking of all data transfers is essential, together with the ability to understand the relative use of IPv6 and IPv4. This paper presents the status of monitoring IPv6 data flows within WLCG and the plans to improve the ability to distinguish between IPv6 and IPv4. Furthermore, the Research Networking Technical Working Group has identified marking the IPv6 packet header as one approach for understanding complex large data flows. This provides another driver for full transition to the use of IPv6 in WLCG data transfers.
The agreed endpoint of the WLCG transition to IPv6 remains the deployment of IPv6-only services, thereby removing the complexity and security concerns of operating dual stacks. The working group is identifying where IPv4 can be removed and investigating the obstacles to the use of IPv6 in WLCG. Why do transfers between two dual-stack endpoints still use IPv4? This work is presented together with the obstacles defeated, those remaining, and those outside of our control.
The Large Hadron Collider (LHC) at CERN is the largest and most powerful particle collider today. The Phase-II Upgrade of the LHC will increase the instantaneous luminosity by a factor of 7 leading to the High Luminosity LHC (HL-LHC). At the HL-LHC, the number of proton-proton collisions in one bunch crossing (called pileup) increases significantly, putting more stringent requirements on the LHC detector electronics and real-time data processing capabilities.
The ATLAS Liquid Argon (LAr) calorimeter measures the energy of particles produced in LHC collisions. This calorimeter also feeds the ATLAS trigger to identify interesting events. In order to enhance the ATLAS detector physics discovery potential, in the blurred environment created by the pileup, an excellent resolution of the deposited energy and an accurate detection of the deposited time are crucial.
The computation of the deposited energy will be performed in real-time using dedicated data acquisition electronic boards based on FPGAs. FPGAs are chosen for their capacity to treat large amounts of data with very low latency. The computation of the deposited energy is currently done using optimal filtering algorithms that assume a nominal pulse shape of the electronic signal. These filter algorithms are adapted to the LHC conditions with very limited pileup and no timing overlap of the electronic pulses in the detector. However, with the increased luminosity and pileup at HL-LHC, the performance of the filter algorithms decreases significantly and no further extension nor tuning of these algorithms could recover the lost performance.
The off-detector electronic boards for the Phase-II Upgrade of the LAr calorimeter will use the next high-end generation of INTEL FPGAs with increased processing power and memory. This is a unique opportunity to develop the necessary tools, enabling the use of more complex algorithms on these boards. We developed several neural networks (NNs) with significant performance improvements with respect to the optimal filtering algorithms. The main challenge is to efficiently implement these NNs into the dedicated data acquisition electronics. Special effort was dedicated to minimising the needed computational power while optimising the NNs architectures.
Five NN algorithms based on CNN, RNN, and LSTM architectures will be presented. The improvement of the energy resolution and the accuracy on the deposited time compared to the legacy filter algorithms, especially for overlapping pulses, will be discussed. The implementation of these networks in firmware will be shown. Two implementation categories in VHDL and Quartus HLS code are considered. The implementation results on Stratix 10 INTEL FPGAs, including the resource usage, the latency, and operation frequency will be reported. Approximations for the firmware implementations, including the use of fixed-point precision arithmetic and lookup tables for activation functions, will be discussed. Implementations including time multiplexing to reduce resource usage will be presented. We will show that two of these NNs implementations are viable solutions that fit the stringent data processing requirements on the latency (O(100ns)) and bandwidth (O(1Tb/s) per FPGA) needed for the ATLAS detector operation. The results of the tests of one of the NNs on the hardware will be presented along with the test setup.
This development is completely new and targets a technological breakthrough in the usage of neural networks implemented in readout electronic boards of particle physics detectors. We show that this goal is achievable for the HL-LHC upgrade. The results from this work are published in a special edition of the Computing and Software for Big Science journal.
The data-taking conditions expected of Run 3 pose unprecedented challenges for the DAQ systems of the LHCb experiment at the LHC. The LHCb collaboration is pioneering the adoption of a fully-software trigger to cope with the expected increase in luminosity and, thus, event rate. The upgraded trigger system has required advances in the use of hardware architectures, software and algorithms. Among the last, the LHCb collaboration can be quoted for using Lipschitz monotonic neural networks for the first time. These are particularly appealing, owing to their robustness under varying detector conditions and sensitivity to highly displaced, high-momentum beauty candidates. An overview of the applications of such architectures within the LHCb trigger system is presented. Emphasis is placed on the topological triggers, devoted to selecting b-hadron candidates inclusively by exploiting the kinematics and decay topology characteristic of beauty decays.
The High-Luminosity LHC upgrade of the CMS experiment will utilise a large number of Machine Learning (ML) based algorithms in its hardware-based trigger. These ML algorithms will facilitate the selection of potentially interesting events for storage and offline analysis. Strict latency and resource requirements limit the size and complexity of these models due to their use in a high-speed trigger setting and deployment on FPGA hardware.
It is envisaged that these ML models will be trained on large, carefully tuned, Monte Carlo (MC) datasets and subsequently deployed in a real-world detector environment. Not only is there a potentially large difference between the MC training data and real-world conditions but these detector conditions could change over time leading to a shift in model output which could degrade trigger performance.
The studies presented explore different techniques to reduce the impact of this effect, using the CMS track finding and vertex trigger algorithms as a test case. The studies compare a baseline retraining and redeployment of the model, uncertainty quantification of the model output, and episodic training of a model as new data arrives in a continual learning context. The results show that a continually learning algorithm outperforms a simple retrained model when degradation in detector performance is applied to the training data and is a viable option for maintaining performance in an evolving environment such as the High-Luminosity LHC.
For the Belle II experiment, the electromagnetic calorimeter (ECL) plays a crucial role in both the trigger decisions and the offline analysis.
The performance of existing clustering algorithms degrades with rising backgrounds that are expected for the increasing luminosity in Belle II. In offline analyses, this mostly impacts the energy resolution for low-energy photons; for the trigger, it's most challenging to keep a high efficiency with low fake rates, especially for low-energy or overlapping clusters.
In the case of offline reconstruction, we developed a soft clustering algorithm based on graph neural networks (GNN) that improves the energy resolution for photons. We report a significant improvement over the current Belle II algorithm with better resolution for low-energy photons, particularly for the increased background rates expected with higher instantaneous luminosity.
For online reconstruction, we implemented a resource-efficient GNN-based algorithm for object condensation that is able to detect an unknown number of clusters and their respective position and energy inside the calorimeter, despite the presence of background energy and the irregular geometry of the ECL. This is compared to the current trigger algorithm in Belle II and could provide an improved trigger decision, especially for higher background rates.
In a decade from now, the Upgrade II of LHCb experiment will face an instantaneous luminosity ten times higher than in the current Run 3 conditions. This will bring LHCb to a new era, with huge event sizes and typically several signal heavy-hadron decays per event. The trigger scope will shift from selecting interesting events to select interesting parts of multi-signal events. To allow for an inclusive, automatic and accurate multi-signal selection per event, we propose evolving from the current signal-based trigger to a Deep-learning based Full Event Interpretation (DFEI) approach. We have designed the first prototype for the DFEI algorithm, leveraging the power of Graph Neural Networks (GNN). The algorithm takes as input the final-state particles and has a two-folded goal: select the sub-set of particles originated in heavy-hadron decays, and reconstruct the decay chains in which they were produced. In this talk, we describe the design and development of this prototype, its current performance on simulated data for Run 3 conditions, and the studies and developments done so far towards and eventual integration in the Real Time Analysis (RTA) system of LHCb.
The search for exotic long-lived particles (LLP) is a key area of the current LHC physics programme and is expected to remain so into the High-Luminosity (HL)-LHC era. As in many areas of the LHC physics programme Machine Learning algorithms play a crucial role in this area, in particular Deep Neural Networks (DNN), which are able to use large numbers of low-level features to achieve enhanced search sensitivity. Sophisticated algorithms however present computing challenges, especially looking forward to the data rates and volumes of the HL-LHC era. Accelerated computing, using heterogeneous hardware such as GPUs and FPGAs alongside CPUs, offers a solution to the computing challenges, both in offline processing and realtime triggering applications. Demonstrating state-of-the-art algorithms on such hardware is a key benchmark for developing this computing model for the future.
The studies presented describe the implementation of a DNN based LLP jet-tagging algorithm, published by the CMS experiment, on an FPGA. Novel optimisations in the design of this DNN are presented, including the adoption of cyclic random access memories for a simplified convolution operation, the reuse of multiply accumulate operations for a flexibly selectable tradeoff between throughput and resource usage, and storing matrices distributed over many RAM memories with elements grouped by index as opposed to traditional storage methods. An evaluation of potential dataflow hardware architectures is also included. It is shown that the proposed optimisations can yield performance enhancements by factors up to an order of magnitude compared to other FPGA implementations. They can also lead to smaller FPGA footprints and accordingly reduce power consumption, allowing for instance duplication of compute units to achieve increases in effective throughput, as well as deployment on a wider range of devices and applications.
The first stage of the LHCb High Level Trigger is implemented as a GPU application. In 2023 it will run on 400 NVIDIA GPUs and its goal is to reduce the rate of incoming data from 5 TB/s to approximately 100 GB/s. A broad scala of reconstruction algorithms is implemented as approximately 70 kernels. Machine Learning algorithms are attractive to further extend the physics reach of the application, but inference must be integrated into the existing GPU application and be very fast to maintain the required throughput of at least 10 GB/s per GPU. We investigate the use of NVIDIA TensorRT for flexible loading of Machine Learning models and fast inference, benchmark its performance for a range of interesting Machine Learning models and compare it to hand-coded implementations where possible.
In mainstream machine learning, transformers are gaining widespread usage. As Vision Transformers rise in popularity in computer vision, they now aim to tackle a wide variety of machine learning applications. In particular, transformers for High Energy Physics (HEP) experiments continue to be investigated for tasks including jet tagging, particle reconstruction, and pile-up mitigation.
In a first of its kind a Quantum Vision Transformer (QViT) with a Quantum-enhanced attention mechanism (and thereby quantum-enhanced self-attention) is introduced and discussed. A shallow circuit is proposed for each component of self-attention to leverage current Noisy Intermediate Scale Quantum (NISQ) devices. Variations of the hybrid architecture/model are explored and analyzed.
The results demonstrate a successful proof of concept for the QViT, and establish a competitive performance benchmark for the proposed design and implementation. The findings also provide strong motivation to experiment with different architectures, hyperparameters, and datasets, setting the stage for implementation in HEP environments where transformers are increasingly used in state of the art machine learning solutions.
A new theoretical framework in Quantum Machine Learning (QML) allows to compare the performances of Quantum and Classical ML models on supervised learning tasks. We assess the performance of a quantum and classic support vector machine for a High Energy Physics dataset: the Higgs tt ̄H(b ̄b) decay dataset, grounding our study in a new theoretical framework based on three metrics: the geometry between the classical and quantum learning spaces, the dimensionality of the feature space, and the complexity of the ML models. Hence, we can exclude those areas where we do not expect any advantage in using quantum models and guide our study through the best parameter configurations. We observe, in a vast parameter region, that the used classical rbf kernel model overtakes the performances of the devised quantum kernels. According to the adopted quantum encoding, the Higgs dataset has been proved to be low dimensional in the quantum feature space. Nevertheless, including a projected quantum kernel, able to reduce the expressivity of the traditional fidelity quantum, a clever optimization of the parameters revealed a potential window of quantum advantage where quantum kernel is able to better classify the Higgs boson events and surpass the classical ML model.
Free energy-based reinforcement learning (FERL) with clamped quantum Boltzmann machines (QBM) was shown to significantly improve the learning efficiency compared to classical Q-learning with the restriction, however, to discrete state-action space environments. We extended FERL to continuous state-action space environments by developing a hybrid actor-critic scheme combining a classical actor-network with a QBM-based critic. Results obtained with quantum annealing, both simulated and with D-Wave quantum annealing hardware, are discussed, and the performance is compared to classical reinforcement learning methods. The method is applied to a variety of particle accelerator environments among which is the actual electron beam line of the Advanced Plasma Wakefield Experiment (AWAKE) at CERN.
With the emergence of the research field Quantum Machine Learning, interest in finding advantageous real-world applications is growing as well.
However challenges concerning the number of available qubits on Noisy Intermediate Scale Quantum (NISQ) devices and accuracy losses due to hardware imperfections still remain and limit the applicability of such approaches in real-world scenarios.
For simplification, most studies therefore assume nearly noise-free conditions as they are expected with logical, i.e. error-corrected, qubits instead of real qubits provided by hardware.
However, the number of logical qubits is expected to scale slowly as they require a high number of real qubits for error correction.
This is our motivation to deal with noise as an unavoidable, non-negligible problem on NISQ devices.
Using the example of particle decay tree reconstruction as a highly complex combinatoric problem in High Energy Physics we investigate methods to reduce the noise impact of such devices and propose a hybrid architecture where a classical graph neural network is extended by a parameterized quantum circuit.
While we have shown that such a hybrid architecture enables a reduction of the amount of trainable parameters compared to the fully classical case, we are now specifically interested in the actual performance on real quantum devices.
Using simple synthetic Decay Trees, we train the network in classical simulations to allow for efficient optimization of the parameters.
The trained parameters are validated on NISQ devices by "IBM Quantum" and are used in interpretability and significance studies, enabling improvements in the accuracy on real devices.
In summary we improved the results of the existing architecture in terms of the validation performance, on real quantum devices.
In the search for advantage in Quantum Machine Learning, appropriate encoding of the underlying classical data into a quantum state is a critical step. Our previous work [1] implemented an encoding method inspired by underlying physics and achieved AUC scores higher than that of classical techniques for a reduced dataset of B Meson Continuum Suppression data. A particular problem faced by these Quantum SVM techniques was overfitting of training data. One possible method of tackling this is by reducing the expressibility of the model by exploiting symmetries in the data using symmetry invariant encodings. There are often several natural symmetries present in Particle Physics data (permutation of particle order and rotational symmetry) that can be targeted. This presentation demonstrates a method of encoding that guarantees invariance under permuting the ordering of particles in the data input. A downside of this model for more general applicability is the quadratic scaling of ancilla qubits as the number of states to be symmetrised increases. However, data from Particle Physics may only contain a small number of particles in each event, meaning this scaling is not too prohibitive and suggests particle data is well suited to this approach. In addition we explore solutions to this scaling using approximately invariant encoding created through genetic algorithms. As quantum technology develops over the coming decade it is hoped the methods discussed here can form a basis for Quantum Machine Learning model development in a Particle Physics context.
References:
[1] Heredge, J., Hill, C., Hollenberg, L., Sevior, M., Quantum Support Vector Machines for Continuum Suppression in B Meson Decays. Comput Softw Big Sci 5, 27 (2021). https://doi.org/10.1007/s41781-021-00075-x
The nature and origin of dark matter are among the most compelling mysteries of contemporary science. There is strong evidence for dark matter from its role in shaping the galaxies and galaxy clusters that we observe in the universe. Still, physicists have tried to detect dark matter particles for over three decades with little success.
This talk will describe the leading effort in that search, the LUX-ZEPLIN (LZ) detector. LZ is an instrument that is superlative in many ways. It consists of 10 tons of liquified xenon gas, maintained at almost atomic purity and stored in a refrigerated titanium cylinder a mile underground in a former gold mine in Lead, South Dakota.
The increasing volumes of data produced at light sources such as the Linac Coherent Light Source (LCLS) enable the direct observation of materials and molecular assemblies at the length and timescales of molecular and atomic motion. This exponential increase in the scale and speed of data production is prohibitive to traditional analysis workflows that rely on scientists tuning parameters during live experiments to adapt data collection and analysis. User facilities will increasingly rely on the automated delivery of actionable information in real time for rapid experiment adaptation which presents a considerable challenge for data acquisition, data processing, data management, and workflow orchestration. In addition, the desire from researchers to accelerate science requires rapid analysis, dynamic integration of experiment and theory, the ability to visualize results in near real-time, and the introduction of ML and AI techniques. We present the LCLS-II Data System architecture which is designed to address these challenges via an adaptable data reduction pipeline (DRP) to reduce data volume on-the-fly, online monitoring analysis software for real-time data visualization and experiment feedback, and the ability to scale to computing needs by utilizing local and remote compute resources, such as the ASCR Leadership Class Facilities, to enable quasi-real-time data analysis in minutes. We discuss the overall challenges facing LCLS, our ongoing work to develop a system responsive to these challenges, and our vision for future developments.
The astronomy world is moving towards exascale observatories and experiments, with data distribution and access challenges that are comparable with - and on similar timescales to - those of HL-LHC. I will present some of these use cases and show progress towards prototyping work in the Square Kilometre Array (SKA) Regional Centre Network, and present the conceptual architectural view of the global SRCNet that we hope to implement ready for SKA operations from around 2027.
{kind=link}